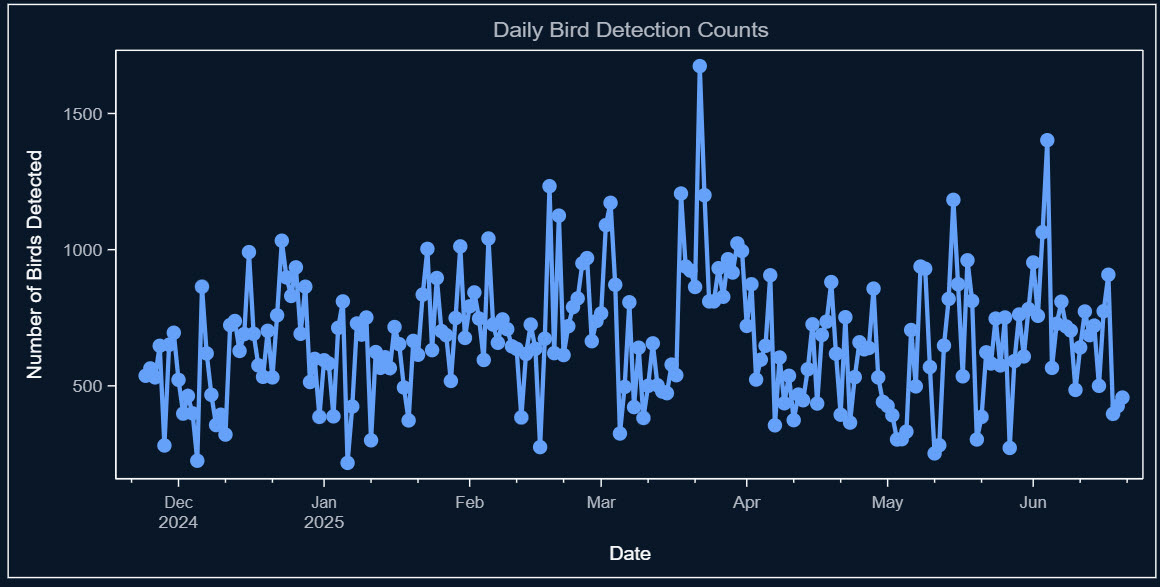
How I use BirdNET-PI and SAS to track my feathered neighbors

How I collected birdsong detection data from BirdNET-PI and used SAS to visualize the bird visits across the seasons.



