The “last mile” is well known in telecommunications and supply chains. It’s that challenging last stage of the journey to deliver the product or service to the customer’s premises. It’s so hard because that’s where you meet all kinds of real-world difficulties out of your own control. We are now seeing a similar problem in analytics. We can make rapid progress in a lab environment. But putting the analytical model with associated code and data into operations proves far more difficult. According to a survey by IDC*, only 35% of organizations have analytical models fully deployed in production. Recent research by SAS indicates that 90% of models take more than three months to get into production. And 44% of models take over seven months.
Similar problems in the realm of application development led to the practice known as DevOps. With attention now focusing on analytical models, we have a new term: ModelOps.
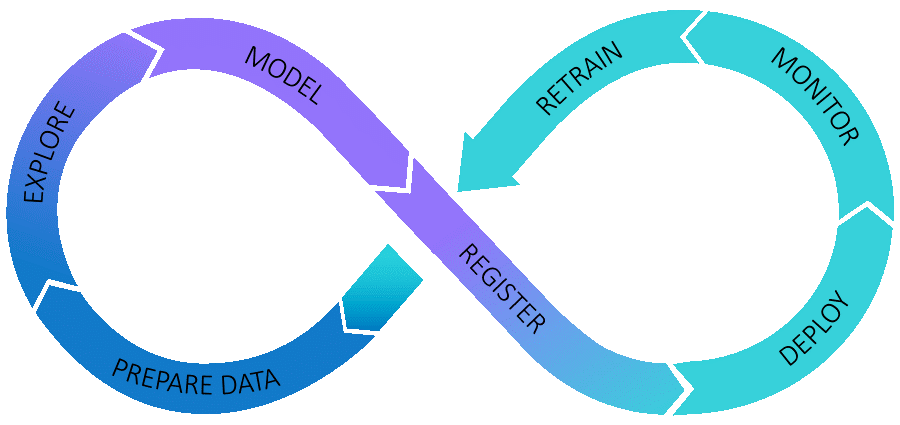
Getting models into production is at the heart of this, but why is it so difficult? Let’s have a look at some of the issues.
Gathering data
Part of the last mile problem actually occurs at the start: gathering and combining data from various sources into a single analytical base table (ABT). In a lab environment, you can gather data from various sources and scramble it together into a table. But that doesn’t provide you with quality ETL code that you can put into production. If you take this approach, you will face a considerable delay when you want to deploy your model. This is because IT will need to start a project to develop the ABT, test it and put it live.
One way to avoid this delay is to make the investment upfront and build an analytical data mart with a wide range of data items from multiple sources to support a number of potential models. This would be put into production and refreshed regularly. If you can source the data you need for a model from this production ABT, then it saves time in both the development of the model and the deployment of the model into production. I was recently talking with the analytics team in a bank that had fast and streamlined processes for deploying models so long as those models could be built using the data in the data mart.
Feature engineering
Of course, the analyst may still need to perform feature engineering to transform the variables in the data mart (e.g., convert age to age bands) or impute missing values. But this is a distinctly separate step that follows after the creation of the data mart and may be different for each type of model. Feature engineering can be done through manual coding. Or you can use a point-and-click machine learning pipeline tool, such as SAS Model Studio. Either way, code gets bundled with the model scoring code to be run just before the model when it is deployed.
Some models may require data that is not in the existing data mart. In that case, you need a slick process to make that data available for both analytical model building and for running the resulting models, as well as creating the required metadata and lineage. It involves coordination between the data science team and the IT team responsible for data. We call the discipline for this DataOps.
Nice model but the wrong software
Once you develop the model, you record it in a register and hand it over to IT for implementation. A typical problem at this stage is that the software used to develop the model may not be available or supported in production. A data scientist may have created the model in Python. But if IT only supports Java in production, it is not going to get any further without being rewritten and validated, adding more delay to the process. This highlights that it is not enough to create an isolated lab environment with whatever software takes your fancy. You need to align the lab and the production environment to avoid the delays, cost and risk of recoding.
The most obvious way to align the environments is to have the same software in each. Whatever you run in the lab, you can then equally run in production. That’s fine in theory, but it may take months to update a new version of the software in production after you've implemented and tested it in a nonproduction environment. The latest version may be available in the lab, but there could be a delay in upgrading production before models using the latest software can be deployed there.
Containers
Another approach gaining in popularity is to use containers. You develop the model in SAS, Python or R and then package it in a Docker container with the necessary software to run it. When you promote the container to production, it runs on a container orchestration platform, such as Kubernetes. With this approach you do not have to update any production software as all the software you need is included in the container. You can also run different versions of software in each container without them interfering with each other. This is especially important for open source software as versions change frequently. SAS publishes recipes on GitHub for building containers to run models written in R or Python.
Decision logic
Having the model in production is usually just half of the picture. Usually, you want to use the result of the model in an automated business process to make a decision or take some action. For example, having a credit score model in production may not be much use unless you assess whether the score is over a threshold. Then you can combine that with some other factors to decide whether to offer a loan.
This decision logic may be complex, and it’s critically important that it is implemented correctly. I have heard of a bank’s IT department mistakenly coding the decision logic for credit card applications so that the high-risk applicants were accepted while the low-risk ones were rejected, simply by misinterpreting the 0s and the 1s! It is now possible to avoid these delays and risks by using a point-and-click tool that also allows you to build the decision logic graphically and test it in combination with models and business rules.
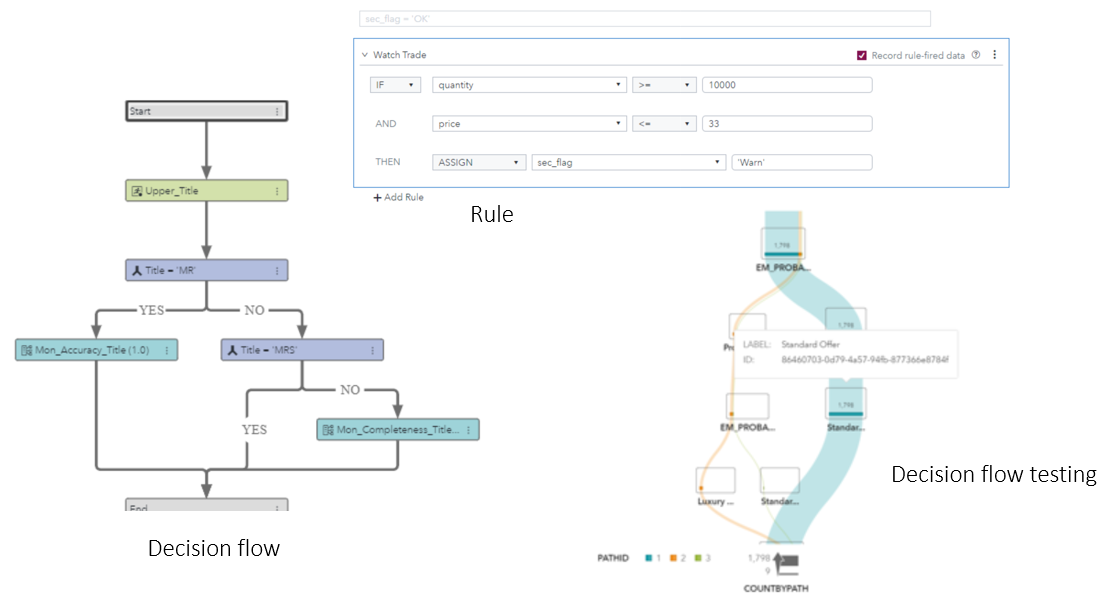
Orchestrating the deployment
Whether you are using containers or deploying to a conventional environment on virtual machines, the process of deploying a model involves many steps. Using orchestration tools – such as Jenkins or Bamboo – can help to automate sequences of tasks, avoiding operational risks and speeding up the process. You can set up SAS Model Manager as the control centre, managing the workflow and triggering other orchestration tools to perform work such as packaging the model into a container.
Integrating with applications and business process
Deploying the model is not the end of the journey. But it brings us to the point where ModelOps meets DevOps. We then need to integrate the model with an application and manage all the steps to put the combined system into live operation. The application could simply be a scheduled batch job or possibly a web app calling the model through an API. We need to set up connections to data sources and populate any new data stores. And we need to functionally test it. The model and application are there to support a business process. So we need to assess the integrated system in terms of its usability and whether it delivers the expected business outcomes. Once this is done and approved, we can put it live.
The last mile - An approach gaining in popularity is to use #containers. The #model is developed in #SAS, #Python or R and then packaged in a Docker container with the necessary software to run it. Share on XContinuous improvement
The last mile is a tricky problem that you cannot solve overnight. It requires a range of incremental improvements that will take time to implement. The important thing, of course, is to examine each stage of the process. You must monitor the impact of your changes and look for the next opportunities. You may not be able to eliminate the last mile problem altogether. But through innovation and continual improvement, you can speed the process of getting analytics into operations.
* IDC’s Advanced and Predictive Analytics survey and interviews, n = 400, 2017 – 2019.
