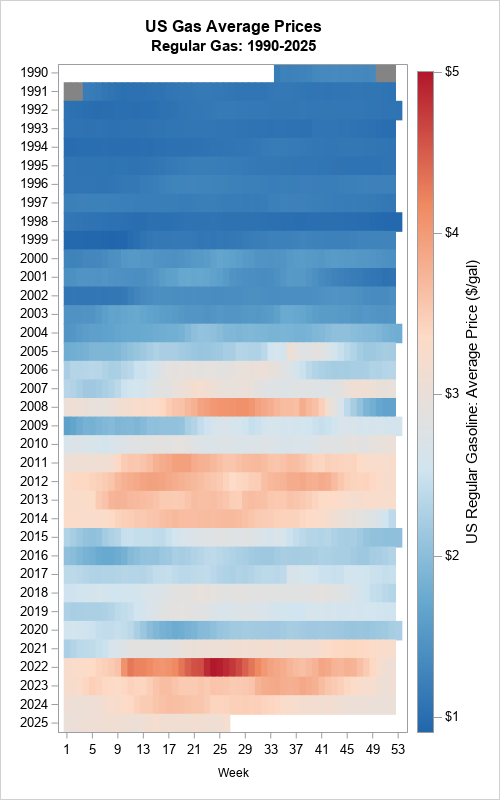
Use a lasagna plot to visualize US gas prices

I follow several data visualization experts on social media. Sometimes, I see a graph that I struggle to interpret. When that happens, I ask myself whether there is a simpler and more effective way to visualize the data. Recently, I saw an example of using a "horizon plot" to visualize