On discussion forums, many SAS programmers ask about the best way to generate dummy variables for categorical variables. Well-meaning responders offer all sorts of advice, including writing your own DATA step program, sometimes mixed with macro programming. This article shows that the simplest and easiest way to generate dummy variables in SAS is to use PROC GLMSELECT. It is not necessary to write a SAS program to generate dummy variables. This article shows an example of generating dummy variables that have meaningful names, which are based on the name of the original variable and the categories (levels) of the variable.
A dummy variable is a binary indicator variable. Given a categorical variable, X, that has k levels, you can generate k dummy variables. The j_th dummy variable indicates the presence (1) or absence (0) of the j_th category. These variables are part of the design matrix that is used for solving a linear regression model. Although the focus of this article is dummy variables, PROC GLMSELECT can create many kinds of manufactured effects such as spline effects and interaction effects.
Before creating dummy variables, as yourself if you really need them. Most SAS regression procedures support the CLASS statement, which enables you to specify categorical variables and various encodings. The procedure will internally create and use the dummy variables. If a procedure supports the CLASS statement, you might not need to create the dummy variables yourself.
Why GLMSELECT is the best way to generate dummy variables
I usually avoid saying "this is the best way" to do something in SAS. But if you are facing an impending deadline, you are probably more interested in solving your problem and less interested in comparing five different ways to solve it. So let's cut to the chase: If you want to generate dummy variables in SAS, use PROC GLMSELECT.
Why do I say that? Because PROC GLMSELECT has the following features that make it easy to use and flexible:
- The syntax of PROC GLMSELECT is straightforward and easy to understand.
- The dummy variables that PROC GLMSELECT creates have meaningful names. For example, if the name of the categorical variable is X and it has values 'A', 'B', and 'C', then the names of the dummy variables are X_A, X_B, and X_C.
- PROC GLMSELECT creates a macro variable named _GLSMOD that contains the names of the dummy variables.
- When you write the dummy variables to a SAS data set, you can include the original variables or not.
- By default, PROC GLMSELECT uses the GLM parameterization of CLASS variables. This is what you need to generate dummy variables. But the same procedure also enables you to generate design matrices that use different parameterizations, that contain interaction effects, that contain spline bases, and more.
The only drawback to using PROC GLMSELECT is that it requires a response variable to put on the MODEL statement. But that is easily addressed.
How to generate dummy variables
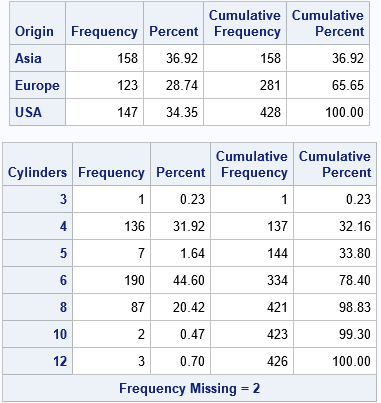
Let's show an example of generating dummy variables. I will use two categorical variables in the Sashelp.Cars data: Origin and Cylinders. First, let's look at the data. As the output from PROC FREQ shows, the Origin variable has three levels ('Asia', 'Europe', and 'USA') and the Cylinders variable has seven valid levels and also contains two missing values.
%let DSIn = Sashelp.Cars; /* name of input data set */ %let VarList = Origin Cylinders; /* name of categorical variables */ proc freq data=&DSIn; tables &VarList; run; |
In order to use PROC GLMSELECT, you need a numeric response variable. PROC GLMSELECT does not care what the response variable is, but it must exist. The simplest thing to do is to create a "fake" response variable by using a DATA step view. To generate the dummy variables, put the names of the categorical variables on the CLASS and MODEL statements. You can use the OUTDESIGN= option to write the dummy variables (and, optionally, the original variables) to a SAS data set. The following statements generate dummy variables for the Origin and Cylinders variables:
/* An easy way to generate dummy variables is to use PROC GLMSELECT */ /* 1. add a fake response variable */ data AddFakeY / view=AddFakeY; set &DSIn; _Y = 0; run; /* 2. Create the dummy variables as a GLM design matrix. Include the original variables, if desired */ proc glmselect data=AddFakeY NOPRINT outdesign(addinputvars)=Want(drop=_Y); class &VarList; /* list the categorical variables here */ model _Y = &VarList / noint selection=none; run; |
The dummy variables are contained in the WANT data set. As mentioned, the GLMSELECT procedure creates a macro variable (_GLSMOD) that contains the names of the dummy variables. You can use this macro variable in procedures and in the DATA step. For example, you can use it to look at the names and labels for the dummy variables:
/* show the names of the dummy variables */ proc contents varnum data=Want(keep=&_GLSMOD); ods select Position; run; |
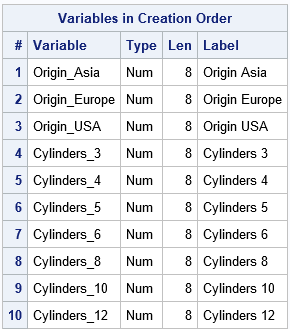
Notice that the names of the dummy variables are very understandable. The three levels of the Origin variable are 'Asia', 'Europe', and 'USA, so the dummy variables are named Origin_Asia, Origin_Europe, and Origin_USA. The dummy variables for the seven valid levels of the Cylinders variable are named Cylinders_N, where N is a valid level.
A macro to generate dummy variables
It is easy to encapsulate the two steps into a SAS macro to make it easier to generate dummy variables. The following statements define the %DummyVars macro, which takes three arguments:
- DSIn is the name of the input data set, which contains the categorical variables.
- VarList is a space-separated list of the names of the categorical variables. Dummy variables will be created for each variable that you specify.
- DSOut is the name of the output data set, which contains the dummy variables.
/* define a macro to create dummy variables */ %macro DummyVars(DSIn, /* the name of the input data set */ VarList, /* the names of the categorical variables */ DSOut); /* the name of the output data set */ /* 1. add a fake response variable */ data AddFakeY / view=AddFakeY; set &DSIn; _Y = 0; /* add a fake response variable */ run; /* 2. Create the design matrix. Include the original variables, if desired */ proc glmselect data=AddFakeY NOPRINT outdesign(addinputvars)=&DSOut(drop=_Y); class &VarList; model _Y = &VarList / noint selection=none; run; %mend; /* test macro on the Age and Sex variables of the Sashelp.Class data */ %DummyVars(Sashelp.Class, Age Sex, ClassDummy); |
When you run the macro, it writes the dummy variables to the ClassDummy data set. It also creates a macro variable (_GLSMOD) that contains the name of the dummy variables. You can use the macro to analyze or print the dummy variables, as follows:
/* _GLSMOD is a macro variable that contains the names of the dummy variables */ proc print data=ClassDummy noobs; var Name &_GLSMod; run; |
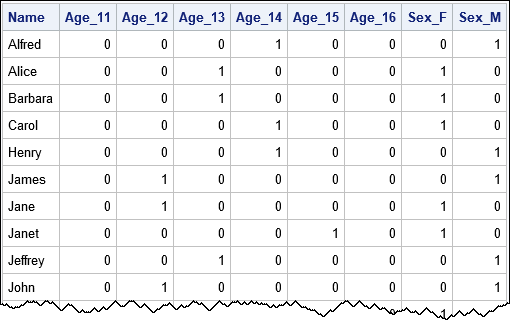
The dummy variables tell you that Alfred is a 14-year-old male, Alice is a 13-year-old female, and so forth.
What happens if a categorical variable contains a missing value?
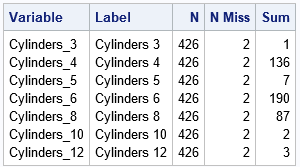
If a categorical variable contains a missing value, so do all dummy variables that are generated from that variable. For example, we saw earlier that the Cylinders variable for the Sashelp.Cars data has two missing values. You can use PROC MEANS to show that the dummy variables (named Cylinders_N) also have two missing values. Because the dummy variables are binary variables, the sum of each dummy variable matches the number of levels. Compare the SUM column in the PROC MEANS output with the earlier output from PROC FREQ:
/* A missing value in Cylinders results in a missing value for each dummy variable that is generated from Cylinders */ proc means data=Want N NMiss Sum ndec=0; vars Cylinders_:; run; |
Summary
In most analyses, it is unnecessary to generate dummy variables. Most SAS procedures support the CLASS statement, which enables you to use categorical variables directly in statistical analyses. However, if you do need to generate dummy variables, there is an easy way to do it: Use PROC GLMSELECT or use the %DummyVars macro in this article. The result is a SAS data set that contains the dummy variables and a macro variable (_GLSMOD) that contains the names of the dummy variables.
Further Reading
Here are links to previous articles about dummy variables and creating design matrices in SAS.
- The GLMMOD procedure enables you to create dummy variables. However, the dummy variables are named COL1, COL2, ..., which might be harder work with.
- Generating dummy variables is a special case of generating a design matrix. You can read about four procedures that can generate a design matrix in SAS. However, PROC GLMSELECT can do everything those procedures can do, except the GLIMMIX procedure can generate design columns for random effects.
- There are other ways to generate meaningful names for dummy variables, but none is easier than using PROC GLMSELECT.

15 Comments
Very nice! I wish I had seen this a month ago - it would have saved me a lot of work!
The features in GLMSELECT that allow the easy creation of dummy variables are a great convenience. Thanks for the detailed explanation, Rick. Regarding the creation of a "fake" response variable, I found a long time ago that it was frequently useful to have a variable that was always equal to 1 -- which I cleverly called ONE. It allows for counting things in certain ways e.g. by getting sums of that variable for certain subsets. I also can't resist putting an a plug for my SUGI 30 paper on "Parameterizing Models to Test the Hypotheses You Want: Coding Indicator Variables and Modified Continuous Variables" https://support.sas.com/resources/papers/proceedings/proceedings/sugi30/212-30.pdf. It includes some discussion of the alternative parameterizations available.
Thanks, David. For readers who are interested in knowing which SAS regression procedures support "alternative parameterizations," see this cheat sheet for CLASS variable encodings.
Hi sir,
In my SAS environment, there is a space (instead of underscore character) between the variable name and value (e.g. "Origin Europe" instead of "Origin_Europe"). Is it another one of those differences due the different versions of SAS?
Thanks for writing. The only way you can get a space in a variable name is if you are using the VALIDVARNAME=ANY system option.
On my blog, I use VALIDVARNAME=V7. To find out your value, use
proc options option=validvarname value; run;
Hi Rick, I just discovered my server has VALIDVARNAME=ANY. So my 200 + indicators created in this way all had a space, which I cannot use once I export the data to run models in STATA. Is there a way we can change it?
I don't know how to get PROC GLMSELECT to change it, but you can use the RENAME statement to get rid of the blanks. You can use PROC SQL or the DATA step. A macro that replaces blanks with underscores is provided as an answer to a question on the SAS Support Communities, which is where you can ask questions like this.
Hi Bocheng, I had the same problem as you. I modified the macro with: options validvarname=v7 and then the dummy variables were created with an underscore instead of a space! Love this code!!! Thank you Rick.
Thanks for pointing to GLMSELECT.
It works fine for me when using a single class variable, but I would like to have a full rank design matrix with several class variables, ie. some dummies need be eliminated. How do I obtain that without detailed programming?
Or are there other ways of getting rid of dummies. When using the dummies in a syslin model, estimation stops with the message "model is not of full rank". In comparison, Stata cleans up without being asked. Obviously is SAS not that friendly, but how do I ask it to be?
best Øyvind
1. The best place to ask SAS programming questions is the SAS Support Communities. You can post sample data and the model that you are interested in.
2. By default, the design matrix is singular because it uses the so-called GLM parameterization. If you re-read the article, you will notice that it shows how to use the PARAM=EFFECT option to obtain a nonsingular design matrix. I think this will resolve your issue.
Thanks Rick
Your point 2 answers my question. Whenever possible, I would avoid programming.
best Øyvind
Pingback: The QR algorithm for least-squares regression - The DO Loop
Hi Rick,
Thank you for sharing. I encountered some issue when using your method. Unfortunately, I cannot share the data with you. The problem I encountered is that your method will ignore some dummies for an unknown reason. For example, there are two countries in my data, A and B. Out of 2000 observations, only 200 are from country B. In this case, the method choose to create only Country_A. However, not all variables are like that. I currently do not have a clue about what is the reason behind it. My feeling is that having missing values, too many categories, and very unbalanced distribution are plausible causes to the problem but none of them can explain the problem by itself. Have you met similar problems? I will dig deeper to see why it does that, your opinion will definitely be valuable! Thanks.
Sincerely,
David
No, I have never encountered any problems. Be sure you understand how SAS regression procedures use listwise deletion to omit observations where ANY independent variable is missing. That is the most likely cause of your problem. Some things to do:
1. Output only the complete cases and then use PROC FREQ to investigate whether any observations from Country="B" remain.
2. Same as above, but you can do it in one step by using PROC MI.
3. If you can anonymize your data, you can post the data and your question to the SAS Support Communities.
Pingback: Standardized regression coefficients in PROC GLIMMIX - The DO Loop