All Posts


Agentic AI has been heralded as a top tool for efficiently orchestrating customer engagement activities at insurance companies. It can: Automate repeatable, rule-based processes that affect customer experience (think claims processing and customer onboarding). Rapidly retrieve disparate data, analyze risks and recommend decisions. Help lower operational costs while keeping humans


Advanced AI technology is transforming how governments think, work and solve problems. With new terminology and evolving tools, understanding AI can feel overwhelming. Before diving into new applications, it helps to build a strong foundation in its core concepts. This overview breaks down three of today’s most prominent AI capabilities: machine learning,


Optimice y modernice todo el proceso de planificación financiera con analítica El problema El ritmo de los cambios normativos, junto con el crecimiento explosivo de los datos financieros y operativos disponibles, ha hecho que las soluciones de contabilidad tradicionales sean incapaces de proporcionar la información crítica sobre los costes, la


If you have decided to track your food intake recently, you might feel overwhelmed by all the options. There are hundreds (even thousands) of food tracking apps available, with new ones popping up all the time. Apps like MyFitness Pal, Lose It! and Cronometer have been around for a long


Many conversations about AI agents focus on models and frameworks. But when organizations attempt to deploy agents in real operational environments, a different challenge quickly emerges. How agents reliably and securely access enterprise data. Without reliable access to relevant data, AI agents struggle to support operational decisions. Whether diagnosing equipment


Governance, risk and compliance (GRC) has evolved beyond a control mechanism or regulatory safeguard. In today’s environment, it forms the operational backbone of effective corporate management – enabling organizations to identify risks early, meet regulatory expectations reliably, and ensure that decisions and processes remain transparent and traceable. Yet many organizations still


Enterprise decisioning has moved far beyond isolated, one‑off decisions. Today’s organizations operate in environments where decisions are continuous, high‑volume and increasingly autonomous – executed thousands to millions of times per day across credit origination, fraud detection, next‑best action, pricing and personalized engagement. These decisions are not monolithic. They combine business


Everyone is racing to scale their AI right now, but we keep hitting the same uncomfortable truth: your AI platform is only as good as what you feed it. The problem? Real-world data is a mess. It’s hard to get your hands on. It's expensive to clean, often biased and


A nagging question remains after asking, “What’s next after zero-click search?” How do frontier models – like OpenAI’s o3 series or Google’s Gemini 3 – learn? Garbage in, garbage out Large language models (LLMs) learn from massive amounts of text data, including billions of words, public information, and, you guessed it,
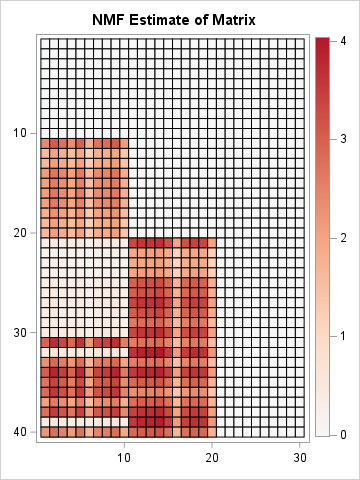

The classical singular value decomposition (SVD) has a long and venerable history. I have described it as a fundamental theorem of linear algebra. Nevertheless, the mathematical property that makes it so useful in general (namely, the orthogonality of the matrix factors) also makes it less useful for certain applications. In


에이전틱 AI는 자동화와 의사결정을 위한 차세대 키워드로 주목받으며 큰 기대를 모으고 있습니다. 하지만 이러한 열기 이면에는 다소 조심스러운 전망이 자리 잡고 있습니다. 가트너(Gartner)는 비용 급증, 불분명한 비즈니스 가치, 부적절한 리스크 관리 등의 이유로 에이전틱 AI 프로젝트의 40% 이상이 2027년 말까지 중단될 것이라고 경고합니다. *이 글은 SAS 글로벌 공공 부문 전략


Para impulsionar a inovação no ensino superior, o SAS oferece acesso gratuito à software de ponta para universidades que desejam preparar seus alunos para o mercado de trabalho cada vez mais orientado a dados e IA por meio do SAS Programa Acadêmico Para reduzir a lacuna entre oferta e demanda


Before the day properly begins, there is already movement. A few steps between shacks. A bucket, a tap and a narrow strip of soil that refuses to be ‘too small’ to matter. In an informal settlement on the edge of the Cradle of Humankind, food is not just bought. It

금융 산업의 성장과 디지털 전환, 핀테크의 부상은 전례 없는 편리한 금융 서비스를 가능하게 했습니다. 그러나 비대면 거래가 일상화되며 금융사기(Fraud) 역시 빠르게 조직화·지능화되고 있습니다. 최근에는 AI 기반 음성 합성, 딥페이크 등이 범죄에 악용되면서 개인의 경험만으로는 이상 징후를 식별하기 어려운 수준까지 진화했습니다. 더 중요한 변화는 책임의 범위입니다. 정부는 금융회사가 일정 한도 내에서


Nos últimos anos, a IA deixou de ser uma tecnologia futurista para se tornar um elemento cada vez mais central na estratégia das empresas, inclusive para a área de Marketing ao ajudar na redefinição da forma como as marcas interagem e chegam até aos consumidores. Segundo, aliás, o estudo Marketers