Add a second axis to a SAS graph

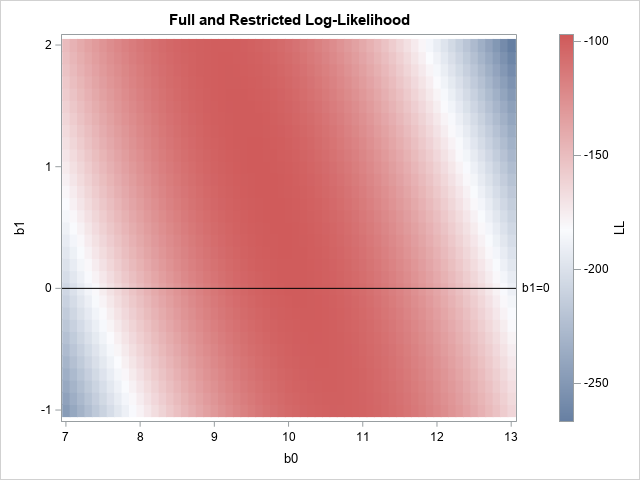
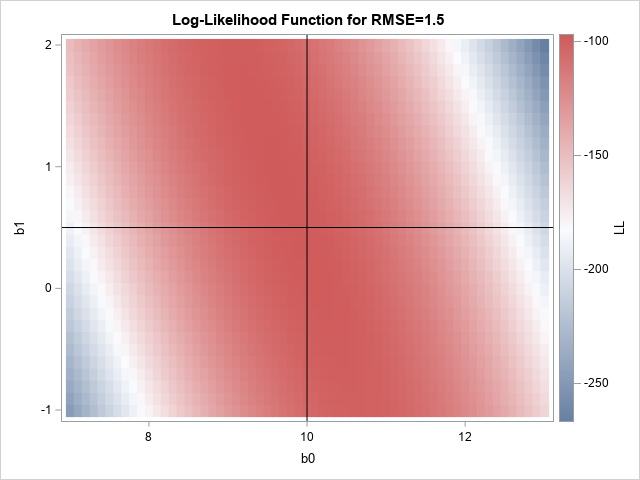
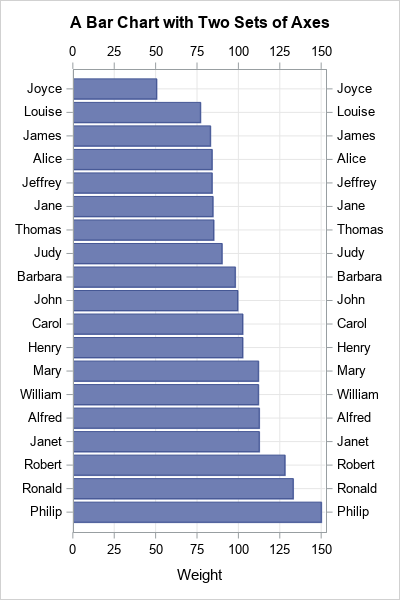
Recently, I saw a scatter plot that displayed the ticks, values, and labels for a vertical axis on the right side of a graph. In the SGPLOT procedure in SAS, you can use the Y2AXIS option to move an axis on the right side of a graph. Similarly, you can