Use the moment-ratio diagram to visualize the sampling distribution of skewness and kurtosis

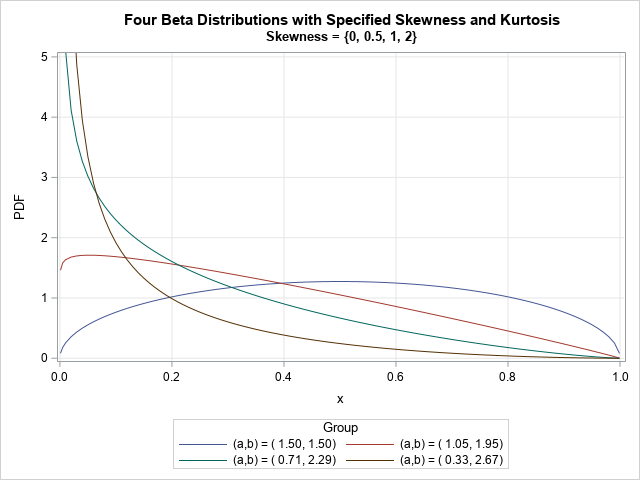
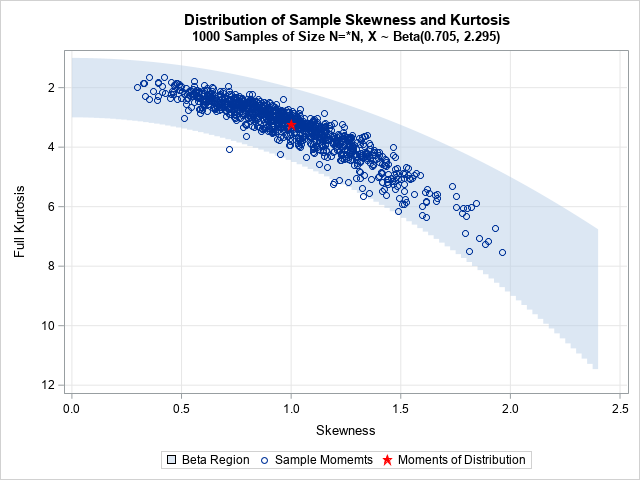
The moment-ratio diagram is a tool that is useful when choosing a distribution that models a sample of univariate data. As I show in my book (Simulating Data with SAS, Wicklin, 2013), you first plot the skewness and kurtosis of the sample on the moment-ratio diagram to see what common