I don't know much about the SQL procedure, but I know that it is powerful. According to the SAS documentation for the SQL procedure, "PROC SQL can perform some of the operations that are provided by the DATA step and the PRINT, SORT, and SUMMARY procedures."
Recently, a fellow blogger, Charlie H., posted an interesting article titled Top 10 most powerful functions for Proc SQL. Although I don't understand every example in his article, I thought that it would be instructive for me to duplicate some of the SQL functions in the SAS/IML language.
The following DATA step creates data for comparing the SQL and PROC IML operations. The data consist of 100 observations and two variables. The first variable contains the integers 1–100, except that a missing value replaces about 20% of the integers. The second variable is similar: about 30% of its values are missing and the rest are integers.
data A; do i=1 to 100; x1=i; x2=abs(-70+i); if ranuni(1)<0.2 then call missing(x1); if ranuni(1)<0.3 then call missing(x2); drop i; output; end; run; |
I'm always excited to learn something new, so here are the first two SQL functions and their SAS/IML equivalents.
The MONOTONIC Function
The first SQL function on Charlie's list is the MONOTONIC function, which he states is equivalent to the DATA step internal variable, _N_. My modification of his example follows, along with the output:
/** (1) MONOTONIC()--SPECIFY ROW NUMBER **/ title 'Specify row numbers'; proc sql; select monotonic(x2) as Obs_num, * from A where monotonic() between 51 and 55; quit; |
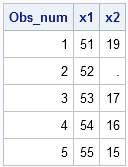
In the SAS/IML language, indexes provide the equivalent functionality. In particular, if you read the data into a matrix and want to extract rows 51–55, you can use the colon operator (:) to form the consecutive indices, and use subscript notation to extract the specified rows of the data. To get all of the columns, leave the column indices unspecified, as shown in the following SAS/IML statements:
proc iml; use A; /** read all data **/ read all var _NUM_ into x[c=VarNames]; close A; idx = 51:55; /** specify rows **/ y = x[idx, ]; /** subset the rows **/ print y[c=VarNames label=NONE]; |
The COUNT, N, FREQ, and NMISS Functions
Charlie's next example uses several functions: the COUNT, N, FREQ, and NMISS functions in SQL. You can use these functions to count the number of rows in the data and the number of missing and nonmissing values in a variable, as follows:
/** (2) COUNT(), N(), FREQ(), NMISS() FIND MISSING and NONMISSING VALUES **/ title 'Find the number of missing values'; proc sql; select count(*) as total, count(x2) as count_x2, N(x2) as n_x2, freq(x2) as freq_x2, nmiss(x2) as miss_x2 from A; quit; |
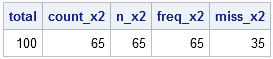
I don't understand the difference (if any) between the COUNT, N, and FREQ functions when applied to a single variable. Perhaps someone can enlighten me?
In the SAS/IML language, you can read the data into a matrix. The NROW function returns the total number of rows in the data. There are several ways to count the number of nonmissing values:
- The syntax x2^=. returns an indicator variable. The variable contains a 1 for rows in which x2 is nonmissing. To get the total number of nonmissing rows, use the SUM function to add up all the 1s.
- You can call the N function in Base SAS software from your SAS/IML program. The expression N(x2) also returns an indicator variable.
- In SAS/IML 9.22 and beyond, you can call the COUNTN function to obtain the count of the nonmissing values.
You can also count the missing values in a variety of ways, such as calling the NMISS function in Base SAS software. The following statements use PROC IML to compute the number of rows in the data, and the number of missing and nonmissing values:
proc iml;
use A; /** read only one variable **/
read all var {x2};
close A;
total = nrow(x2);
count_x2 = sum(x2^=.);
n_x2 = sum(n(x2));
freq_x2 = countn(x2); /** IML 9.22 **/
miss_x2 = sum(nmiss(x2));
print total count_x2 n_x2 freq_x2 miss_x2; |
I haven't looked at the other functions in Charlie's article, but I'll return to this topic occasionally over the next few months. I think it is useful to compare different ways to accomplish the same task. It gives SAS/IML programmers like myself a better understanding of SQL.

2 Comments
Pingback: The UNIQUE Function: PROC SQL compared with PROC IML - The DO Loop
Pingback: The COALESCE function: PROC SQL compared with PROC IML - The DO Loop