
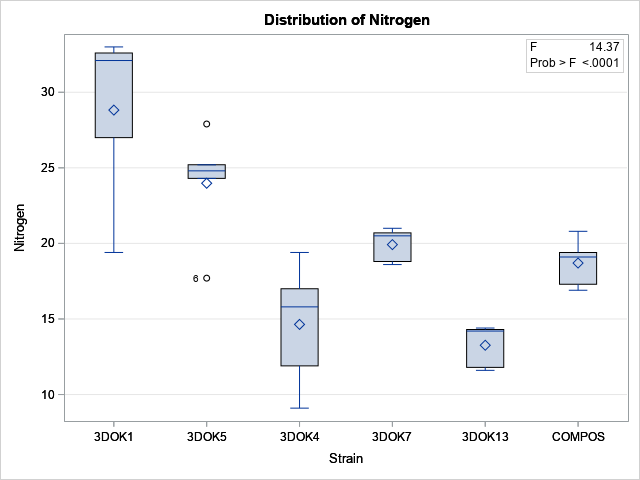
Programming the formulas for an ANOVA in SAS

In practice, there is no need to remember textbook formulas for the ANOVA test because all modern statistical software will perform the test for you. In SAS, the ANOVA procedure is designed to handle balanced designs (the same number of observations in each group) whereas the GLM procedure can handle
