All Posts

Let SAS handle the data prep, R take care of the modeling, and skip the environment-hopping so your team can focus on building cool stuff faster.


From transforming online insurance services to combating the opioid epidemic, SAS customers are using data and AI to drive innovation, enhance efficiency and make a positive impact on society. These stories – and more – offer a glimpse into how our customers are shaping the future with SAS. Dive into

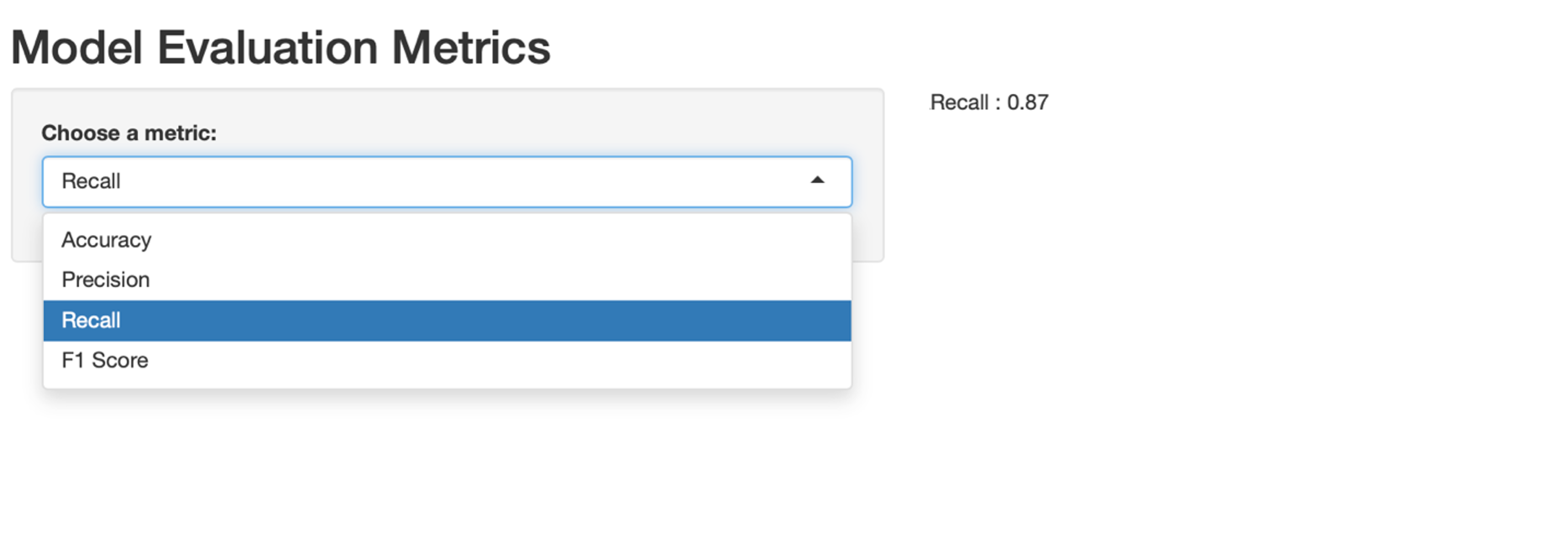
SAS provides procedures to fit common probability distributions to sample data. You can use PROC UNIVARIATE in Base SAS or PROC SEVERITY in SAS/ETS software to estimate the distribution parameters for approximately 20 common distributions, including normal, lognormal, beta, gamma, and Weibull. Since there are infinitely many distributions, you may


Dentro de las causas que han generado los gastos recientemente cubiertos por las aseguradoras, se incluyen el año más caluroso jamás registrado y el más mortífero desde 2010, y otros fenómenos que evidencian que el cambio climático se ha convertido en el principal desafío para las aseguradoras a nivel mundial,


IA agêntica aliada a uma nova abordagem vêm para transformar processos que definem a competitividade no setor bancário – mas existem desafios que líderes precisam ter no radar O setor bancário atualmente atravessa um ponto de inflexão tecnológico sem precedentes. E não se trata somente de um projeto de transformação
Foco em capacitação e na transformação cultural estão entre os principais fatores que podem contribuir para a evolução da IA no setor público Quando falamos sobre transformação digital no setor público brasileiro, há duas realidades que parecem caminhar em ritmos diferentes. De um lado temos o entusiasmo pela adoção de


Os dados sintéticos vêm se mostrando uma ótima abordagem para diversos casos de uso e setores de mercado. Hoje, discuto a aderência dessa tecnologia nas seguradoras, principalmente diante do ORSA, nova exigência regulatória da SUSEP. A capacidade de antecipar e gerenciar riscos sempre esteve no centro do negócio das seguradoras.


Let’s face it, supply chains today can feel like one headline away from chaos. Whether it’s new tariffs, labor strikes, warehouse fires or unpredictable weather patterns, retail and consumer goods companies are constantly juggling curveballs. Each disruption comes with a price: tighter margins, out-of-stock products, unhappy customers and many operational
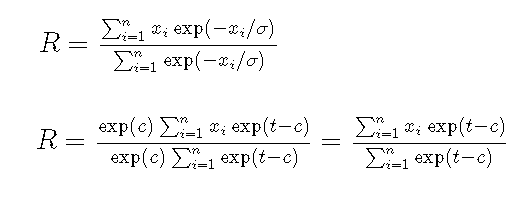
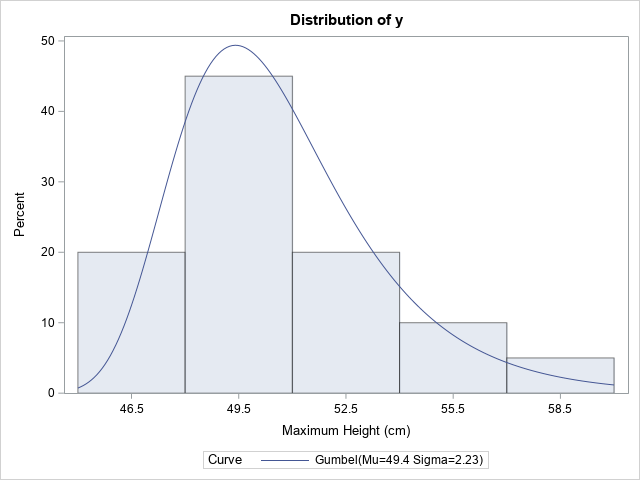
Many common probability distributions contain terms that increase or decrease quickly, such as the exponential function and factorials. The numerical evaluation of these quantities can result in numerical overflow (or underflow). This is why we often work on the logarithmic scale: on the log-scale, the numerical computations for equations such

Learn how to modernize legacy SAS workflows by integrating Python and automating processes using GitHub Actions and SAS Viya Workbench, enabling seamless collaboration and CI/CD across development environments.


전세계가 끊임없는 위기 속에서 혼돈의 시기를 지나고 있습니다. 미국의 금리 정책 변화, 지역 분쟁, 원자재 가격의 급등락, 규제 변화, 그리고 점점 더 잦아지는 기후 재난 등은 기존의 운영 계획을 무용지물로 만들고 있습니다. 이러한 시대에 은행이 생존하고 성장하기 위해 반드시 갖추어야 할 역량이 있습니다. 바로 통합 재무제표 관리(Integrated Balance Sheet


Synthetic data – algorithmically generated data that mimics real-world data – has emerged as a cornerstone in modern AI workflows. But its promise comes with persistent myths about its capabilities, limitations and reliability. Synthetic data is being explored across industries, from training machine learning models to helping businesses safeguard customer


The future is already here and somehow, it keeps accelerating. Small to midsize businesses (SMBs), in particular, are feeling all the effects of this in real time. From shifting customer demands to tightening budgets and fiercer competition, SMBs are navigating more change than ever. Technology can be a powerful growth


El fraude digital en Colombia no es solo una amenaza, es un fenómeno en expansión que desafía nuestra confianza institucional, impacta las finanzas públicas y golpea con fuerza a los más vulnerables. A medida que los delincuentes migran al entorno digital, los métodos tradicionales de control se quedan cortos. Pero,


Every AI success story starts with a single decision: to move beyond experimentation and commit to real-world impact. But moving from idea to enterprise-scale deployment isn’t just about algorithms – it’s about laying the right groundwork. In the first part of this series, we explored three ways to lay the