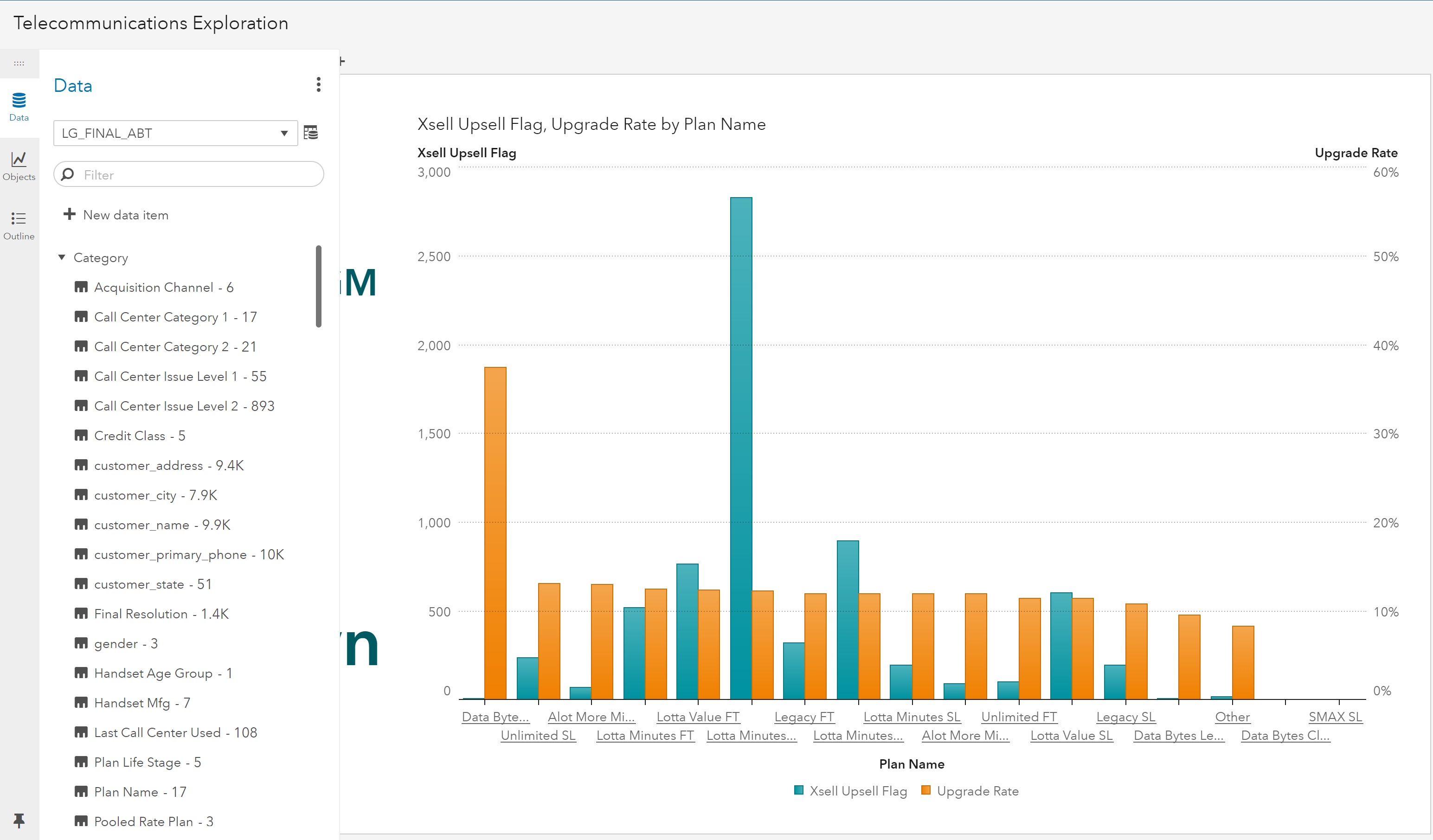
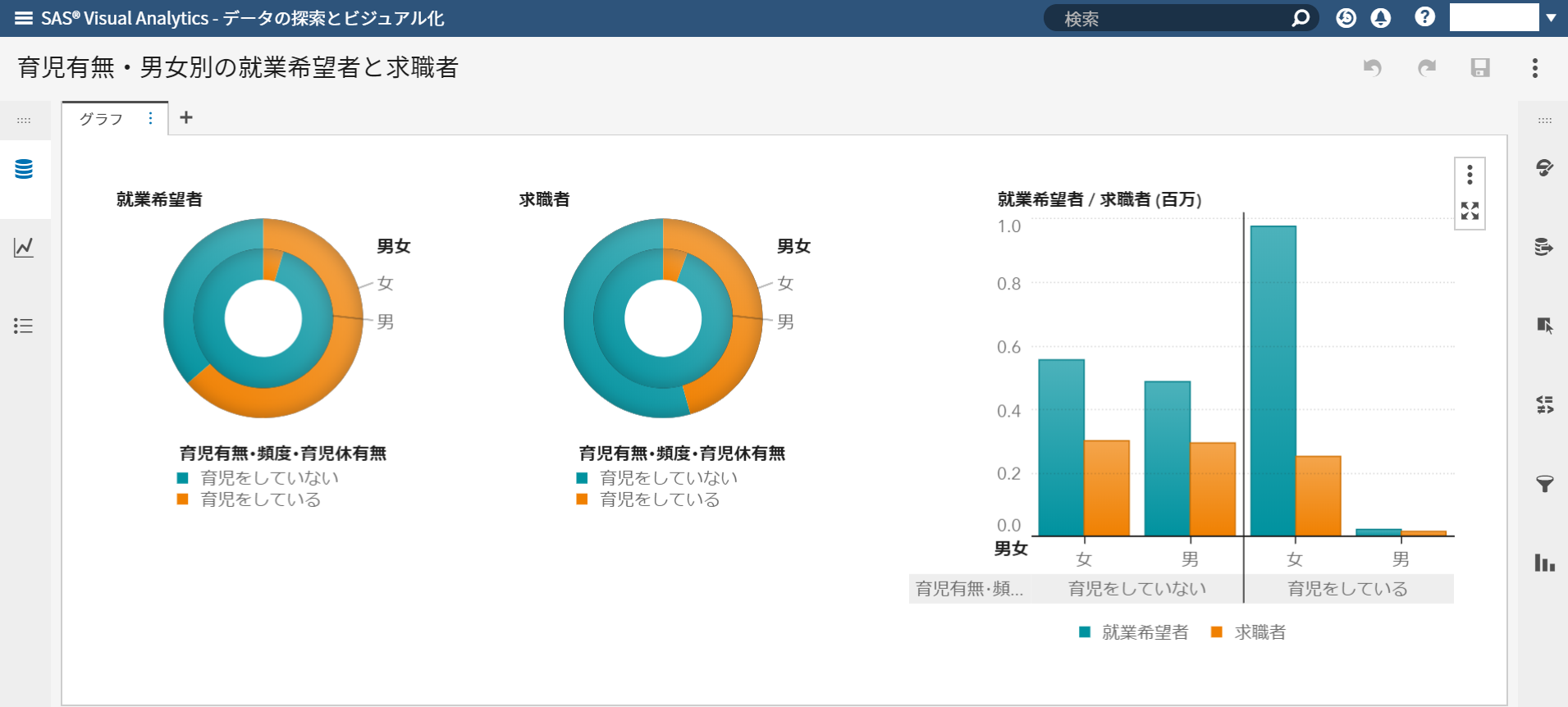
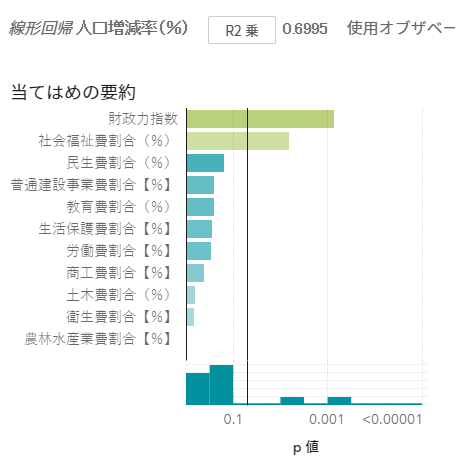
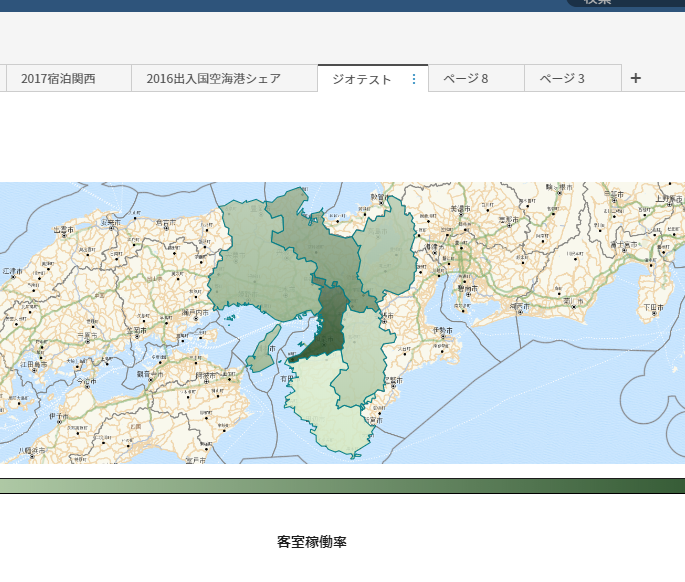
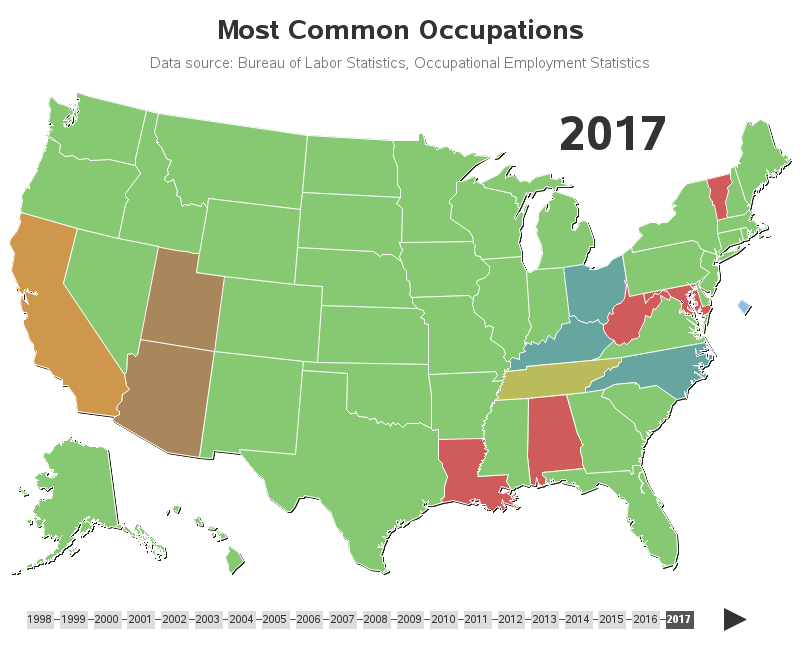
SAS Viyaの新しい権限設定方法
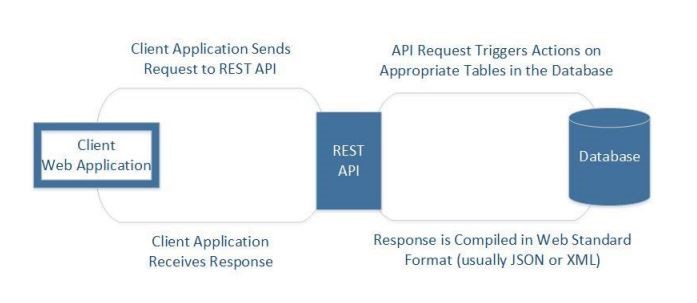
このブログでは、SAS Viyaで提供される各種機能やリソースへのアクセス制限を設定する方法を紹介します。 ユーザーやグループが行うことができる(あるいは参照することができる)内容はルールによって設定されます。ルールは以下の権限要素によって構成されています。: ・プリンシパル:ユーザーまたはグループ。 ・ターゲット:サービス、フォルダ、レポートなどのリソース。 ・権限:アクセスのタイプ(たとえば、読み取りまたは書き込み)。 ・設定:アクセスが提供されているかどうかの表示、たとえば許可または禁止。 ルールのターゲットは、uniform resource identifier(uri)を使用して識別されます。URIは、フォルダやレポート、データプランなどのコンテンツ、またはデータのインポートなどの各種の機能などを表すことができます。 SAS Viyaでのuriの例をいくつか紹介します。 ・データプラン:/ dataPreparationPlans / plans / 810e2c6b-4733-4d53-94fd-dfeb4df0de9e ・フォルダ:/ folders / folders / e28e35af-2673-4fc7-81fa-1a074f4c0de9 ・機能性:/ SASVisualAnalytics / ** 以下の例では、「レポート開発者」カスタムグループを作成し、そのグループのユーザーのみがSAS Visual Analyticsでレポートを作成することができるように設定しています。 カスタムグループを作成します。 ルールを使用して、そのグループに使用機能に対する権限を設定します。 1. カスタムグループを作成 SAS Viyaの環境の管理(SAS Environment Manager)上で、管理者(管理者のみがユーザーとグループを管理できます)が、ユーザー>カスタムグループ>カスタムグループの新規作成を選択します。 カスタムグループの新規作成画面で、「名前」にグループ名、「ID」に一意のID、「説明」に必要に応じて説明を記載します。 新しいグループが作成されたら、編集ボタンをクリックして、新しいメンバーをグループに追加します。 ユーザーまたは他のグループを新しいグループのメンバーとして追加することができます。 2.ルールを使用して、そのグループに使用機能に対する権限を設定 「レポート開発者」グループのみがSAS Visual Analyticsの機能にアクセスできるようにルールを作成、または更新します。まず、SAS Visual Analyticsに現在適用されているルールを見ていきます。 環境の管理(SAS Environment