As part of my research for a different article, I recently collected data about my driving commute home via an accelerometer recorder app on my phone. The app generates a simple TSV file. (A TSV file is like a CSV file, but instead of a comma separator, it uses a TAB character to separate the values.) The raw data looks like this:
With SAS, it's simple to import the file into a data set. Here's my DATA step code that uses the INFILE statement to identify the file and how to read it. Note that the DLM= option references the hexadecimal value for the TAB character in ASCII (09x), the delimiter for fields in this data.
data drive; infile "/home/chris.hemedinger/tsv/drivehome.tsv" dlm='09'x; length counter 8 timestamp 8 x 8 y 8 z 8 filename $ 25; input counter timestamp x y z filename; run; |
In my research, I didn't stop with just my drive home. In addition to my commute, I collected data about 4 other activities, and thus accumulated a collection of TSV files. Here's my file directory in my SAS OnDemand for Academics account:
To import each of these data files into SAS, I could simply copy and paste my code 4 times and then replace the name of the file for each case that I collected. After all, copy-and-paste is a tried and true method for writing large volumes of code. But as the number of code lines grows, so does the maintenance work. If I want to add any additional logic into my DATA step, that change would need to be applied 5 times. And if I later come back and add more files to my TSV collection, I'll need to copy-and-paste the same code blocks for my additional cases.
Using a wildcard on the INFILE statement
I can read all of my TSV files in a single step by using the wildcard notation in my INFILE statement. I replaced the "drivehome.tsv" filename with *.tsv, which tells SAS to match on all of the TSV files in the folder and process each of them in turn. I also changed the name of the data set from "drive" to the more generic "accel".
data accel; infile "/home/chris.hemedinger/tsv/*.tsv" dlm='09'x; length counter 8 timestamp 8 x 8 y 8 z 8 filename $ 25; input counter timestamp x y z filename; run; |
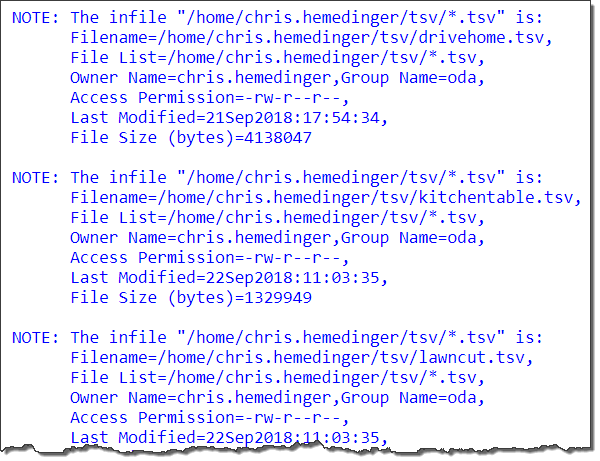
The SAS log shows which files have been processed and added into my data set.
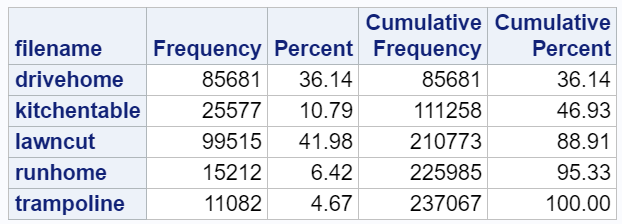
With a single data set that has all of my accelerometer readings, I can easily segment these with a WHERE clause in later processing. It's convenient that my accelerometer app also captured the name of each TSV file so that I can keep these cases distinct. A quick PROC FREQ shows the allocation of records for each case that I collected.
Add the filename into the data set
If your input data files don't contain an eponymous field name, then you will need to use a different method to keep track of which records come from which files. The DATA step INFILE statement supports a special option for this -- it's the FILENAME= option. The FILENAME= option allows you to specify an automatic variable to store the name of the current input file. Like all automatic variables in the DATA step, this variable won't be written to the output data set by default. So, you need to include code that assigns the value to a permanent variable that you can save. Here's my code, refactored a little bit, now with the options for reading/storing the file names we're processing:
filename tsvs "/home/chris.hemedinger/tsv/*.tsv"; data accel; length casefile $ 100 /* to write to data set */ counter 8 timestamp 8 x 8 y 8 z 8 filename $ 25 tsvfile $ 100 /* to hold the value */ ; /* store the name of the current infile */ infile tsvs filename=tsvfile dlm='09'x ; casefile=tsvfile; input counter timestamp x y z filename; run; |
In the output, you'll notice that we now have the fully qualified file name that SAS processed using INFILE.
Managing data files: fewer files is better
Because we started this task with 5 distinct input files, it might be tempting to store the records in separate tables: one for each accelerometer case. While there might be good reasons to do that for some types of data, I believe that we have more flexibility when we keep all of these records together in a single data set. (But if you must split a single data set into many, here's a method to do it.)
In this single data set, we still have the information that keeps the records distinct (the name of the original files), so we haven't lost anything. SAS procedures support CLASS and BY statements that allow us to simplify our code when reporting across different groups of data. We'll have fewer blocks of repetitive code, and we can accomplish more across all of these cases before we have to resort to SAS macro logic to repeat operations for each file.
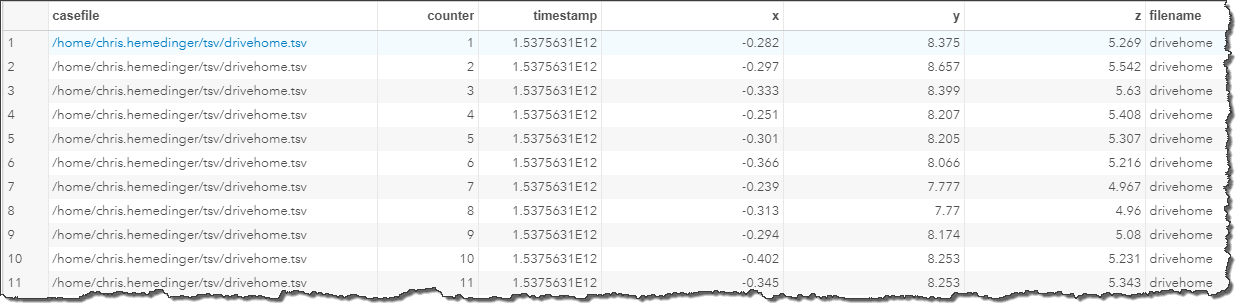
As a simple example, I can create a simple visualization with a single PROC SGPANEL step.
ods graphics / width=1600 height=400; proc sgpanel data=accel; panelby filename / columns=5 noheader; series x=counter y=x; series x=counter y=y; series x=counter y=z; colaxis display=none minor; rowaxis label="m/s**2" grid; where counter<11000; run; |
Take a look at these 5 series plots. Using just what you know of the file names and these plots, can you guess which panel represents which accelerometer case?
Leave your guess in the comments section. Update: answers revealed (via SAS Visual Analytics) in this post!

17 Comments
My first guess was that they are displayed in alphabetical order, but that just doesn't quite match my expectations.
I'll venture #1 is lawn cut, #2 is definitely kitchen table, #3 is run home, #4 is drive home, and #5 is trampoline.
Good guesses Paul! I won't confirm your answers...yet :)
I thought PANELBY orders the values in the filename column, making it drivehome, kitchentable, lawncut, runhome, trampoline? Although, that makes you a very smooth driver but erratic mower!
On reading external files with the wildcard notation, I found this is great for text files with a stable structure. I found that when dealing with hundreds of files, I was almost certainly getting one or two that were irregularly formed and caused my data step to stop. That meant I needed to rerun the step from scratch, which can take a while if pulling text files from a far. I decided to loop with a macro processing them one at a time. That allowed me to better handle the file(s) that fail without stopping the rest of the data imports. It was also easier to see the performance of each read in the log file, something that became useful as files grew. I still appended the imports into a single data set, then you have one table to use down stream. Just my experience.
It's a great example Chris, could the next step be streaming data from the phone into ESP for analysis?
David, it's good to hear your real-world experience on this.
ESP would be a great next step!
Chris,
The hexadecimal conversion syntax to convert tabs to text doesn't make a lot of sense to 21st century user.
It just shows how long you've been reading text files in SAS.
'Expandtabs' does the same thing and is a lot easier to explain to and remembered by clients
Edzard - I'm one of those who think all programmers should be able to count in hexadecimal -- that gives the kids-these-days an appreciation for how computers really work!
But seriously -- yes, EXPANDTABS is much better. We should probably revamp all of those old examples that still reference hex codes...
Here is my guess: #1 runhome #2 kitchentable #3 trampoline #4 lawncut #5 drivehome
What if each of the data files has field names in the first row? Using firstobs=2 appears to only apply to the first file in the in the folder.
In the context of the examples I shared, I don't think I would use FIRSTOBS. There might be a more elegant method than this, but you might need to detect with the FILENAME= value changes (by RETAINing the value across iterations) and just discard the first _INFILE_ record for each file.
Actually, I just came across this post from Reeza that shows how to manage this with a condition checking for _N_=1 and the EOV= option.
Pingback: A skeptic's guide to statistics in the media - The SAS Dummy
To handle headers use the example that is using the FILENAME= option and test if tsvfile=LAG(tsvfile). You will need to add two extra INPUT statements. One with trailing @ to make sure the name is updated so that name change can be detected. And one to skip the header when it has changed.
infile tsvs filename=tsvfile dlm='09'x ;
input @;
if tsvfile ne lag(tsvfile) then input;
input counter timestamp x y z filename;
casefile=tsvfile;
Thanks for that Tom!
Chris does this multi-file import work in SAS Viya with SAS Studio only. I have to upload files to SAS Viya cloud, using SAS Drive. So I have multiple text files myfile1.txt to myfile10.txt with same format, but to refer to them I'm using
filename ACH FILESRVC folderpath = '/Users/jwalker/My Folder/My Data/'; (also tried folderuri method) then I've tried multiple different infile statements. It works with one file but not with wildcard
this works
data dsn;
infile ACH("myfile1.txt") filename=filename;
Does not work:
data dsn;
infile ACH("*.*") filename=filename;
data dsn;
infile ACH(*.txt) filename=filename;
I also tried this:
filename ACH FILESRVC folderpath='/Users/jwalker/My Folder/My Data/' filename='*.txt';
DATA WORK.dsn;
INFILE ACH;
Hi Jim,
I haven't tested this but my guess is that it doesn't work. Instead you would need to use DATA step to generate a list of the files in a folder, then use INFILE on each. Example of listing these files from the doc.
I think wildcard support would be a good addition here though. Would you consider adding a suggestion to the SASWare Ballot?
Thanks Chris, I was able to list the files in my user folder in viya using this logic:
filename myfldr filesrvc folderPath='/Users/jwalker/My Folder/My Data';
data FILES_LISTED (keep=filename);
did = dopen('myfldr');
mcount = dnum(did);
put 'MYFLDR contains ' mcount 'member(s)...';
do i=1 to mcount;
filename = dread(did, i);
put filename;
output;
end;
rc = dclose(did);
run;
PROC SQL;
CREATE TABLE WORK.NEW_FILES AS SELECT
t1.filename
FROM WORK.FILES_LISTED t1
WHERE t1.filename LIKE "ACHA%";
QUIT;
struggling to figure out how to refer to these filename in the infile statement. I've tried:
data dsn;
set NEW_FILES;
infile myfldr(filename);
ERROR: Physical file does not exist, filename.DATA.
tried this based on my EG code that works with using a dataset to import files:
data dsn;
length location $1000;
set NEW_FILES;
location=cats("/Users/jwalker/My Folder/My Data/",filename);
infile dummy filevar=location end=done;
ERROR: Physical file does not exist, /Users/jwalker/My Folder/My Data/ACHAJ01125109019PDIN20211014164703987.ach.prd.
tried this:
data dsn;
length location $1000;
set NEW_FILES;
location=cats("/Users/jwalker/My Folder/My Data/",filename);
infile location end=done;
ERROR: No logical assign for filename LOCATION.
Any Help would be appreciated. Thanks
Try using the FNAME function to assign the fileref using the FILESVC method, and then use that as the infile source. Something like:
location=cats("/Users/jwalker/My Folder/My Data/",filename); rc = filename('in',location,'FILESVC'); infile in end=done;