All Posts
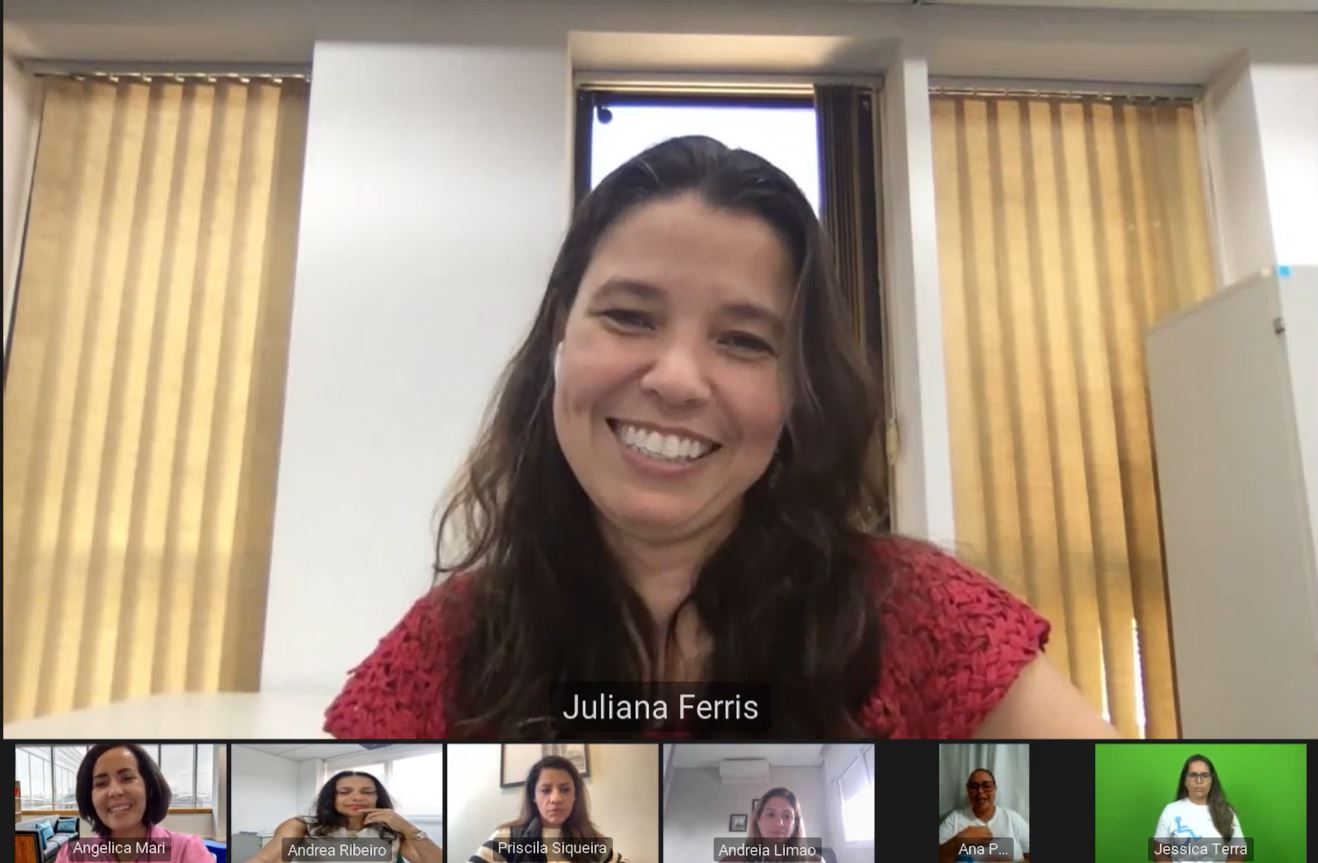

Em painel com líderes de tecnologia, as mulheres debateram sobre a importância da presença feminina em cargos de liderança. Nesta quarta-feira (16), foi realizada mais uma edição do SAS Women Empowerment Day, evento destinado ao debate sobre as oportunidades e os desafios vividos pelas mulheres no ambiente corporativo e principalmente


Nyvi Estephan, apresentadora de games e esportes eletrônicos eleita como a maior host da América Latina, foi uma das keynote speakers do SAS Women Empowerment Day 2022 e abordou a importância de trazer mais mulheres ao mercado de jogos eletrônicos e de combater a toxicidade da comunidade gamer. Durante sua

Em um painel mediado por Thais Cerioni, head de marketing Brasil e gerente de comunicação do sul da América Latina no SAS, quatro mulheres da área de tecnologia debateram os principais desafios e a importância da atuação feminina no setor de tecnologia durante o SAS Women Empowerment Day 2022. Lívia

現代において統計学は様々な分野で利用されており、データアナリティクスとは切っても切れない関係にあります。しかし、実際にデータアナリティクを行う人すべてが、その内容を適切に理解しているのでしょうか。「有意差がつくかどうかとりあえず検定を行ってみる」、「集めたデータ全てをモデルに組み込んでみる」このような経験を持つ方も実は多いのではないでしょうか。分析に用いる手法の仮定や限界、その他解釈や留意事項への理解がないまま行われるデータアナリティクスは、誤った解釈を生む可能性があります。しかし、実社会においては、統計学はその活用事例が注目されがちであり、適切ではない事例が身の回りにあるというのもまた事実です。データアナリティクスを行う側としても、その結果を受け取る側としても、統計学を一般教養として学んでみてはどうでしょうか。 今回紹介するのは、e-learningコース「Statistics 1: Introduction to ANOVA, Regression, and Logistic Regression」です。統計学を学ぶ時に、学習がうまく進まない一つの理由として、各種内容が実際にどう活用されるか、そのイメージがつかないという声を多く耳にします。本コースは純粋な統計学の知識だけでなく、そのような具体的なデータアナリティクスに至るまでの「何を目的とするのか」、「目的によってどのような手法が適切であるのか」といった「データリテラシー」に関する内容も潤沢に用意されているため、一環した流れの中で学習を行う事ができます。このような何のために統計学を学ぶ必要があるのかという点は、どうしても”学問としての”統計学の学習の際には意識がされないため、統計学を初めて学ぶ方だけではなく、簡単にその内容を触れたことがある中級者の方にも最適な学習教材です。 統計学は「記述統計学」と「推測統計学」に分類されます。前者はデータの持つ特徴(最大値、平均など)を記述し、整理することによって、そのデータ自体への理解を行おうというものです。それに対し後者は、データをとある大きな集団からのサンプルであると仮定し、データからその大きな集団(母集団)の持つ特徴について、推測を行うものです。ここでは、実際に推測統計学でよく用いられている「統計的仮説検定」と「統計モデル」という、2つの手法について紹介します。これらについてもコース中ではより詳細に、活用されている事例とともに紹介されているので、ご興味のある方はぜひ一度コースに登録・受講してみてください。登録手順はこちらの以前の記事を参照ください。 統計的仮説検定 ある大きな集団(母集団)に対しその特徴を知りたい場合、すべてのデータを得ることができるのは非常に稀です。例えば、日本国民全員があるテレビ番組Aを見ているかどうかの情報を得ることは、労力的にも、費用的にもほぼ不可能です。統計的仮説検定はそういった場合に、標本である一部のデータを用いて、母集団に対する特定の仮説が成立するか否かを、背理法的に判断する方法です。先のテレビ番組の視聴率調査は、実際にこの考えに基づくものであり、よく見かける視聴率はおおよそ1万世帯のデータをもとに、統計的に推定されています。検定の手順は以下の通りです。 母集団に対し、帰無仮説とそれに対応する対立仮説の計2種類の仮説を設定する 帰無仮説の下で、得られたデータ(とそれ以上に極端な結果)が得られる確率(P値)を計算する 事前に設定した基準(有意水準)とその確率を比較する 基準よりも確率が低いのであれば、そもそも帰無仮説が妥当ではないと判断する(帰無仮説を棄却) 統計学でよく誤解を生みやすい「P値」というものが利用される内容になります。仮説検定は非常によく用いられる方法ですので、自分でどういった手順で検定は行われているのか、その解釈はどう行えばいいのか、を説明できない方は受講してみることをお勧めします。 統計モデル データから母集団の特徴について推定を行う場合には「統計モデル」というものが用いられます。このモデルはなぜ必要なのでしょうか?ここで、日本人の男性と女性の身長について、それぞれ推測をするという例を考えます。また、現実に得られるデータは、男性のみデータだけだとします。すると一つ問題が生じます。それは「女性については推定を行うことができない」ということです。男性については、得られたデータが男性50名の身長データですので、妥当な推定が可能です(ここにも男性の身長分布は正規分布であるという仮定は置きます)。しかし、女性の身長について推定を行おうとしても手元には男性のみのデータしかないため、推定ができません。もし何の仮定もなければ、男性の身長データを女性の身長の推定のために用いることは妥当ではありません。ではここに、『女性の身長の分布は男性の分布より10cm低く、分布の形状は同じである』という仮定があるとどうでしょうか?(いくつかの調査によると期待値としては12~13cmほど低いそうですが) 上記の仮定があるのであれば、男性の身長分布から女性の身長分布が想定可能なので、男性のみのデータからデータには含まれていない女性についても推定を行うことが可能になります。つまり、「統計モデル」とは観測されたデータにはない未知の部分について推測を行うために、仮定する一種の数学的・統計学的な制約条件になります。ただ一概にモデルといっても様々なものがあるため、データの置かれている状況によって想定される適切なモデルは異なり、どれを選択すべきかはケースバイケースです。このモデルの選択をどうすべきかは先行研究やこれまでの知見による部分が大きいため、様々な場面でのデータアナリティクスを学ぶ必要があります。 学生の方であれば今後、卒業研究やコンペティション参加など、多くの場面で統計学の知識が必要になるかと思います。数日学習を行えば統計学への理解が深まるだけでなく、SASから学習認定デジタルバッジを無料でもらうこともできます。ぜひこの機会に一度統計学について、学習を行ってみてはいかがでしょうか?
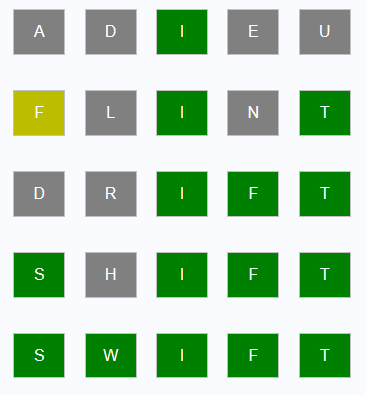

One approach to creating the Wordle game in the SAS programming language. Ready to play?
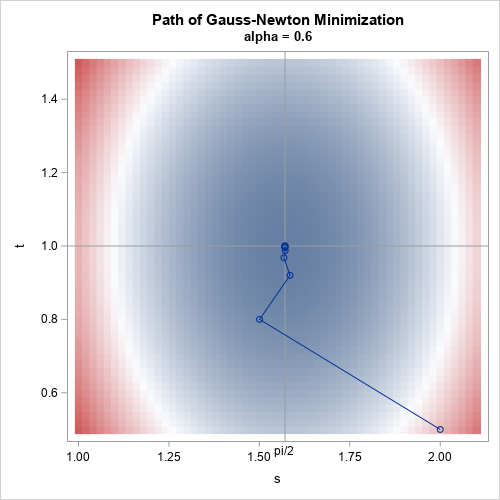

A previous article showed how to use SAS to compute finite-difference derivatives of smooth vector-valued multivariate functions. The article uses the NLPFDD subroutine in SAS/IML to compute the finite-difference derivatives. The article states that the third output argument of the NLPFDD subroutine "contains the matrix product J`*J, where J is


For the last three weeks, our Work/Life series on Coping with Symptoms of Anxiety and Worry has sent out short videos with strategies shared by Alex Harrison, LCSW, Alumni and Family Liaison for ERC/Pathlight Mood and Anxiety Center. Below you'll find all three videos on demand. Video One: Understanding


최근 보고서에 따르면 기후 위기는 심각한 상태에 놓여 있습니다. 대형 산불과 홍수, 허리케인, 해수면 상승 등 기후 변화로 인한 전례 없는 기상 이변으로 지구촌 수십억 명의 사람들이 목숨을 잃었습니다. 데이터와 분석은 이 같은 상황을 예측하고 알림으로써 예방 조치를 취하게 하고, 기후 개선에 대한 인식을 높입니다. IoT 분석을 통한 홍수 대응


Money laundering is a growing threat within the insurance industry. The regulatory framework within banking is adding stronger controls and governance processes which will encourage launderers to seek alternative areas to launder funds. While insurance presents a different type of Anti-Money Laundering (AML) risk, the risks still exist. Long considered


SAS' Xuejun Liao weighs the pros and cons of collaborative filtering and supervised learning and explores their use in a unified framework.

On this Pi Day, let's explore the "πth roots of unity." (Pi Day is celebrated in the US on 3/14 to celebrate π ≈ 3.14159....) It's okay if you've never heard of the πth roots of unity. This article starts by reviewing the better-known nth roots of unity. It then


For Pi Day, veteran SAS user Leonid Batkhan reveals a pi paradox.

Successful asset liability management in banks requires a modern analytics infrastructure.


En el sector Seguros el precio es fundamental. Se trata de un tipo de productos que los clientes saben que es necesario contratar, pero esperan no tener que usarlos nunca, por lo que, en teoría y tradicionalmente, quieren pagar por ellos lo menos posible. Por su parte, las compañías de


Om innovatie op het gebied van data en analytics op een laagdrempelige manier voor ziekenhuizen toegankelijk te maken, bieden SAS en PW Consulting de Healthcare Startup Service aan. Een stapsgewijze aanpak die ziekenhuizen helpt om meer waarde uit hun data en analytics projecten te halen en tevens makkelijk te kunnen