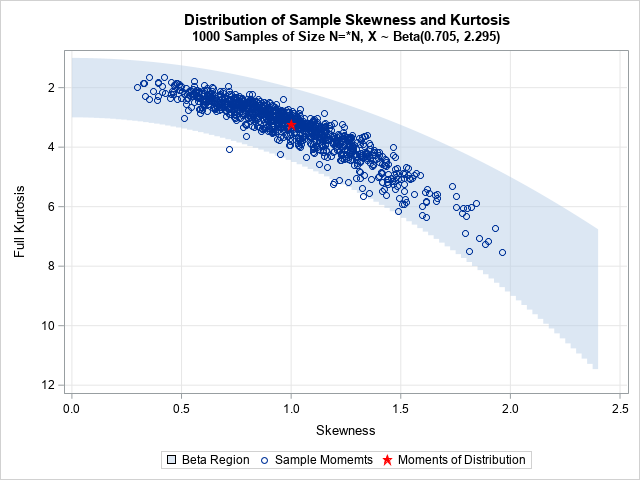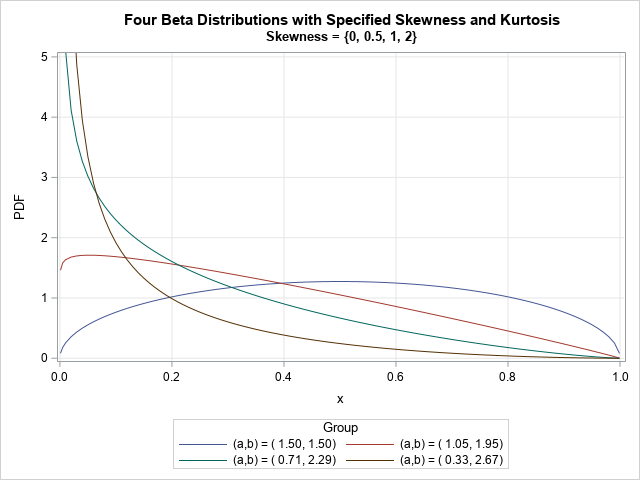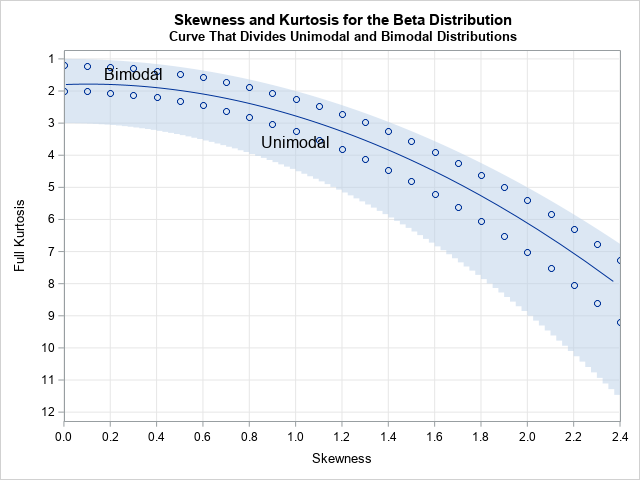
Bimodal and unimodal beta distributions

In a recent article, I graphed the PDF of a few Beta distributions that had a variety of skewness and kurtosis values. I thought that I had chosen the parameter values to represent a wide variety of Beta shapes. However, I was surprised to see that the distributions were all