Being able to reshape data is a useful skill in data analysis. Most of the time you can use the TRANSPOSE procedure or the SAS DATA step to reshape your data. But the SAS/IML language can be handy, too.
I only use PROC TRANSPOSE a few times per year, so my skills never progress beyond the "beginner" stage. I always have to look up the syntax! Sometimes, when I am trying to meet a deadline, I resort to using the SAS/IML language, which I find more intuitive for reshaping data.
Recently I had data that contained two variables: a character categorical variable and a numerical variable. I wanted to reshape the data so that each level (category) of the categorical variable became a new variable, and I wanted to use the levels to name the new variables. (This is an example of converting data from a "long" description to a "wide" description.) Because the number of observations usually differs among categories, some of the new variables will have missing values.
A Canonical Example
A simple example is given by the Sashelp.Class data set. The SEX variable contains two values, F and M. There are several numerical variables; I'll use HEIGHT for this example. For these data, I want to reshape the data to create two variables named X_F and X_M, where the first variable contains the heights of the females and the second variable contains the heights of the males. The following DATA step shows one way to accomplish this:
data combo; keep x_F x_M; merge sashelp.class(where=(sex="F") rename=(height=x_F)) sashelp.class(where=(sex="M") rename=(height=x_M)); run; proc print; run; |
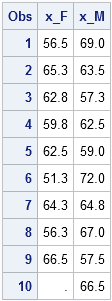
Notice that the X_F variable contains a missing value because there are only nine females in the data, whereas there are ten males.
This technique works when you know the levels of the categorical variable, which you can discover by using PROC FREQ. However, what do you do if the categorical variable has dozens or hundreds of levels? It would be tedious to have to type in the generalization of this DATA step. I'd prefer to have code that works for an arbitrary categorical variable with k levels, and that automatically forms the names of the new variables as X_C1, X_C2, ..., X_Ck where C1, C2, ..., are the unique values of the categorical variable.
Obviously, this can be done, but I had a deadline to meet. Rather than mess with SAS macro, PROC SQL, and other tools that I do not use every day, I turned to the SAS/IML language
SAS/IML to the Rescue
To reshape the data, I needed to do the following:
- Find the levels (unique values) of the categorical variable and count the number of observations in each level.
- Create the names of the new variables by appending the values of each level to the prefix "X_".
- Allocate a matrix large enough to hold the results.
- For the ith level of the categorical variable, copy the corresponding values from the continuous variable into the ith column of the matrix.
The following SAS/IML statements implement this algorithm:
proc iml;
use sashelp.class;
read all var {sex} into C;
read all var {height} into x;
close;
/* TABULATE is SAS 9.3; you can also use UNIQUE + LOC */
call tabulate(u, count, C); /* 1. find unique values and count obs */
labels = "x_" + u; /* 2. create new variable names */
y = j(max(count), ncol(count), .); /* 3. allocate result matrix */
do i = 1 to ncol(count); /* 4. for each level... */
y[1:count[i], i] = x[loc(C=u[i])]; /* copy values into i_th column */
end;
print y[colname=labels]; |
The y matrix contains the desired values. Each column corresponds to a level of the categorical variable. Notice how the LOC function (also known as "the most useful function you've never heard of") is used to identify the observations for each category; the output from the LOC function is used to extract the corresponding values of x.
The program not only works for the Sashelp.Class data, it works in general. The TABULATE function (new in SAS 9.3) finds the unique values of the categorical variable and counts the number of observations for each value. If you do not have SAS 9.3, you can use the UNIQUE-LOC technique to obtain these values (see Section 3.3.5 of my book, Statistical Programming with SAS/IML Software). The remainder of the program is written in terms of these quantities. So, for example, if I want to reshape the MPG_CITY variable in the Sashelp.Cars data according to levels of the ORIGIN variable, all I have to do is change the first few lines of the program:
use sashelp.cars;
read all var {origin} into C;
read all var {mpg_city} into x; |
Obviously, this could also be made into a macro or a SAS/IML module[REF], where the data set name, the name of the categorical variable, and the name of the numerical variable are included as parameters. It is also straightforward to support numerical categorical variables.
Yes, it can be done with Base SAS...
Although the SAS/IML solution is short, simple, and does not require any macro shenanigans, I might as well provide a generalization of the earlier DATA step program. The trick is to use PROC SQL to compute the number of levels and the unique values of the categorical variable, and to put this information into SAS macro variables, like so:
proc sql noprint; select strip(put(count(distinct sex),8.)) into :Count from sashelp.class; select distinct sex into :C1- :C&Count from sashelp.class; quit; |
The macro variable Count contains the number of levels, and the macro variables C1, C2,... contain the unique values. Using these quantities, you can write a short macro loop that generalizes the KEEP and MERGE statements in the original DATA step:
/* create the string x_C1 x_C2 ... where C_i are unique values */ %macro keepvars; %do i=1 %to &Count; x_&&C&i %end; %mend; /* create the various data sets to merge together, and create variable names x_C1 x_C2 ... where C_i are unique values */ %macro mergevars; %do i=1 %to &Count; sashelp.class(where=(sex="&&C&i") rename=(height=x_&&C&i)) %end; %mend; data combo; keep %keepvars; merge %mergevars; run; |
Again, this could be made into a macro where the data set name, the name of the categorical variable, and the name of the numerical variable are included as parameters.
I'd like to thank my colleagues Jerry and Jason for ideas that led to the formulation of the preceding macro code. My colleagues also suggested several other methods for accomplishing the same task. I invite you to post your favorite technique in the comments.
Addendum (11:00am): Several people asked why I want to do this. The reason is that some procedures do not support a classification variable (or don't handle classification variables the way I want). By using this transformation, you can create multiple variables and have a procedure operate on those. For example, the DENSITY statement in PROC SGPLOT does not support a GROUP= option, but you can use this trick to overlay the densities of subgroups.
In reponse to this post, several other techniques in Base SAS were submitted to the SAS-L discussion forum. I particularly like Nat Wooding's solution, which uses PROC TRANSPOSE.

7 Comments
Hi Rick,
Nice post. Minor comment, I think you meant to type labels without quotation marks on the last line of your IML code.
Thanks for the sharp eyes. It is corrected.
Pingback: Overlay density estimates on a plot - The DO Loop
Pingback: Comparative densities - Graphically Speaking
Pingback: Add a prediction ellipse to a scatter plot in SAS - The DO Loop
How do you get the proc iml output (y) into a data set. I tried data new; set y; and got an error. I have never used iml, but it seemed like a good solution.
See "Write data from a matrix to a SAS data set." You can ask questions about SAS/IML programming at the SAS/IML Support Community.