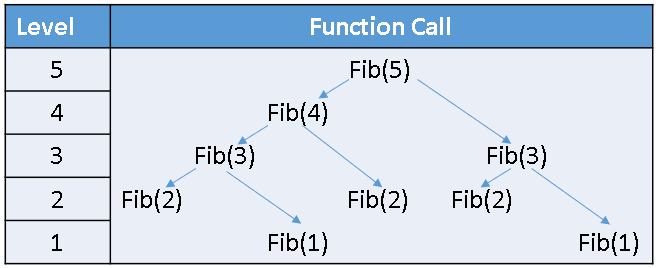
How to write a SAS macro to emulate recursion (and why you shouldn't)

There are two programming tools that I rarely use: the SAS macro language and recursion. The SAS macro language is a tool that enables you to generate SAS statements. I rarely use the SAS macro language because the SAS IML language supports all the functionality required to write complex programs,
