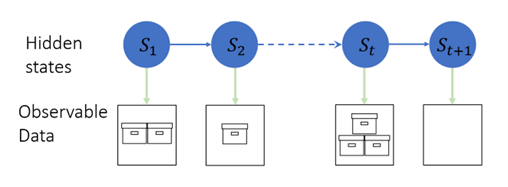
Poisson HMM: The model of count time series

SAS' Ji Shen introduces you to an effective solution for modeling and forecasting count time series.
SAS' Ji Shen introduces you to an effective solution for modeling and forecasting count time series.

A lot of programmers have been impressed by the ability of ChatGPT, GPT-4, and Bing Chat to write computer programs. Recently, I wrote an article that discusses an elementary programming assignment, called FizzBuzz, which is sometimes used as part of a hiring process to assess a candidate's basic knowledge of

What do you get when you mix leaders from every industry, a hall-of-fame basketball coach and a best-selling author together in three days? SAS Innovate in Orlando, of course. As organizations navigate this changing economic landscape, many are turning to analytics and AI to help them stay ahead of the

