
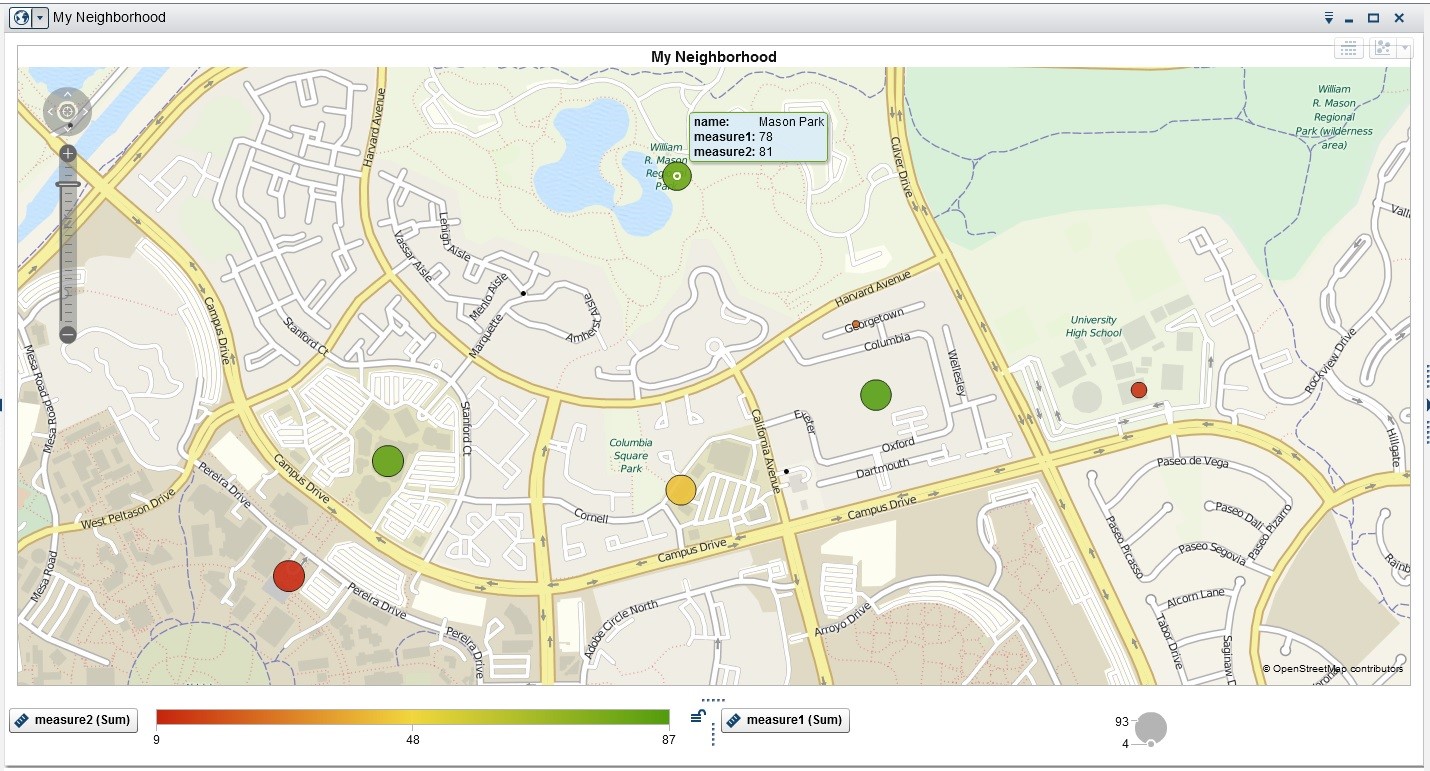
Custom Maps in SAS Visual Analytics: My Neighborhood

The Geo Map Visualization has several built-in geographical units, including country and region names and codes, US state names and codes, and US zip codes. You can also define your own geographic units. This paper describes how to identify any geographic point of interest, or collection of points, on a map to create custom maps in SAS.