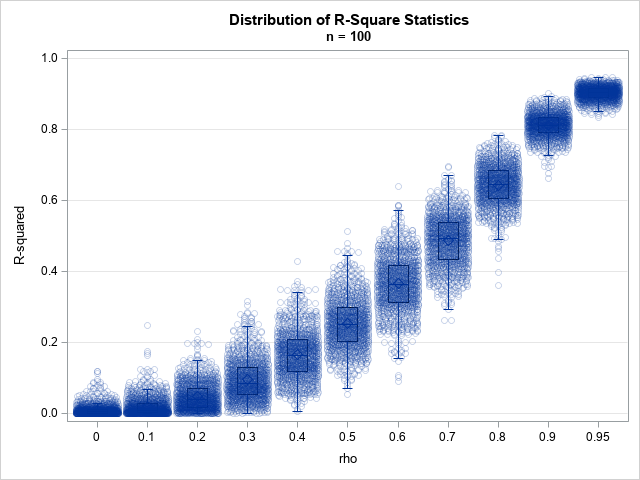
A bootstrap confidence interval for an R-square statistic

A previous article discusses a formula for a confidence interval for R-square in a linear regression model (Olkin and Finn (1995) "Correlations redux", Psychological Bulletin) The formula is useful for large data sets, but should be used with caution for small samples. At the end of the previous article, I