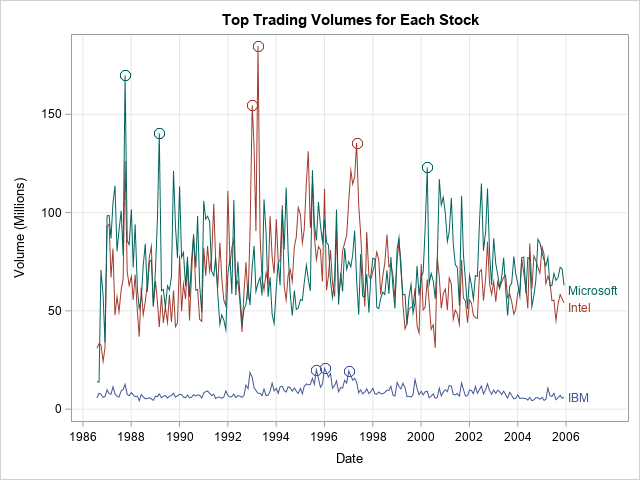
Isotonic regression: An application of quadratic optimization

Isotonic regression (also called monotonic regression) is a type of regression model that assumes that the response variable is a monotonic function of the explanatory variable(s). The model can be nondecreasing or nonincreasing. Certain physical and biological processes can be analyzed by using an isotonic regression model. For example, a