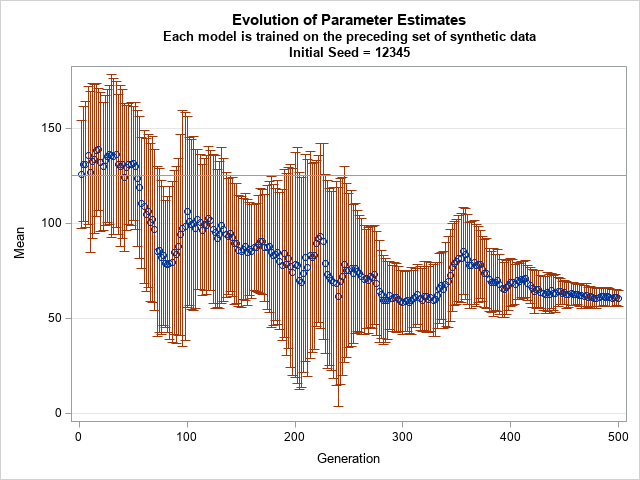
Simulate data from a Poisson regression model

This article shows how to simulate data from a Poisson regression model, including how to account for an offset variable. If you are not familiar with how to run a Poisson regression in SAS, see the article "Poisson regression in SAS." A Poisson regression model is a specific type of