Last week the SAS Training Post blog posted a short article on an easy way to find variables in common to two data sets. The article used PROC CONTENTS (with the SHORT option) to print out the names of variables in SAS data sets so that you can visually determine whether the data sets have any variables in common. The article also mentioned using the COMPARE procedure or writing a PROC SQL query that interrogates DICTIONARY tables.
But what if you want to find variable names that are common to many data sets?
The PROC SQL approach is a programming solution, so it might be up to the challenge. A quick internet search reveals one way to use PROC SQL to find common variables in two data sets (see p. 4 of the linked paper). I am not a PROC SQL expert, but the approach in that paper seems difficult to generalize to the case of multiple data sets.
Because I like the SAS/IML language, this article shows how to find all variables that are common to multiple data sets. The following statements define six SAS data sets:
data D1 D2; A=1; b=2; C=3; D=4; E=5; F=6; g=7; h=8; I=9; J=10; run; data D3 D4; j=1; f=2; h=3; a=4; N=7; L=6; c=7; run; data D5; J=1; D=2; A=3; g=4; h=5; P=6; q=7; run; data D6; C=1; M=2; F=3; a=4; j=5; H=6; B=7; R=8; K=9; run; |
I would have a hard time visually determining which variables are common to all of the data sets, so I'm going to write a program. I will use two SAS/IML functions to help:
- The CONTENTS function returns a sorted list of the variables in a SAS data set. Use the UPCASE function in Base SAS to get the names in uppercase format so that you can perform case-insensitive comparisons.
- The XSECT function returns the intersection between two or more arrays of values.
With those two functions, you can obtain the variables names that are common to the data sets D1–D6, as follows:
proc iml; DSNames = "D1":"D6"; InCommon = upcase(contents(DSNames[1])); /* get all vars in D1 */ do i = 2 to ncol(DSNames); /* loop over data sets */ varNames = upcase(contents(DSNames[i])); /* get variable names */ InCommon = xsect(InCommon, varNames); /* intersect with previous */ end; print InCommon; |
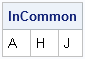
The variables that are common to all the SAS data sets are A, H, and J. If you want to generalize the problem even more, you can use the SAS/IML DATASETS function to get the names of all data sets in a library. For example, you could use DSNames = T(datasets("work")) instead of hard-coding the data set names in this example.
I invite you to submit your own solution in the comments.

9 Comments
An SQL query of the following form should do it (pseudo-SQL):
select the variable names from the dictionary tables
where names in list-of-table-names
group by variable names
having count(*) = number-of-tables;
Use a case-shift function if required.
I have not tested this but the concept is fairly straightforward.
A slight deficiency is that you must count the list-of-table-names yourself.
Here is a PROC SQL solution:
proc sql noprint;
create table check as
select memname, name from sashelp.vcolumn
having libname = 'WORK' and count(name) > 1
and name not in('VAR1','VAR2') /* variables to ignore... */
order by memname,name;
quit;
This is easily generalizable to variables that appear in only one data set, all but one data set, and so forth.
You could combine the two SQL statements into a single statement.
The following query can be used to list common variables (regardless of case) among multiple data sets:
proc sql; select distinct upcase(name) from dictionary.columns where libname='WORK' and memname in ('D1','D2','D3','D4','D5','D6') group by upcase(name) having count(*)>1; quit;This can be used to find common variable(s) that will be overwritten when data sets are merged.
Bost (2007) uses PROC SQL to rename common variables to prevent overwriting when merging two data sets. Young (2011) adapts this technique with a macro to prevent overwriting when merging more than two data sets.
Hi,
if I have a large number of files and all of them are supposed to have some( 1 or 2 )common variables). the objective is to see if there are some files which do not have the common variables and list them out .How to accomplish that? Also how to check if the length of these common variables are same across files?
This is a common question that is asked on the SAS Support Community for Base SAS. Include some sample data and you'll get a solution quicker.
Going a step ahead, what if out of , say we need to merge 10 datasets, some have common variables and some don't have, e.g., 3 out of 10 have a common variable. So after merging these 3(resulting dataset name: merge1) , you get hold of a variable which is common to 2 other datasets. so you perform merge on merge1 with these 2 datasets and keep doing so till you have merged all 10. For 10 datasets having numerous variables it's tedious to find common variables and the work is perplexed if you have, say, 50 datasets. Is there a technique to find out the common variables in any two datasets out of 50 datasets so that we can step forward to merge those.
Thanks,
R.
It sounds like you want to examine all pairwise data sets for common variables. This leads to "N choose 2" combinations to consider. Yes, that can be done. It would be straightforward in SAS/IML by using the ALLCOMB function. If you need more help or you want the solution by using SQL, post your question to the SAS Support Communities.
Thanks a lot Rick. I shall try ALLCOMB.