The other day I encountered an article in the SAS Knowledge Base that shows how to write a macro that "returns the variable name that contains the maximum or minimum value across an observation." Some people might say that the macro is "clever." I say it is complicated. This is a simple problem; it deserves a simple solution.
This is one of those situations where a SAS/IML implementation is simpler and cleaner than a macro/DATA step solution. The following DATA step creates the data that are used in the SAS Knowledge Base article:
/* Data for Sample 46471: Return the variable name that contains the max or min value across an observation */ data one; input a b c d e; cards; 1 3 12 6 15 34 583 294 493 2 ; run; |
By inspection, the minimum value in the first row is 1, which occurs for the variable A. In the second row, the minimum value is 2, which occurs for the variable E.
To find the variable for each row that contains the minimum value for that row, you can use the index minimum subscript reduction operator, which has the symbol >:<. The subscript reduction operators are a little-known part of the SAS/IML language, but they can be very useful. The following SAS/IML program begins by reading all numerical variables into a matrix, X. The subscript reduction operator then computes a column vector whose ith element is the column for which the ith row of X is minimal. You can use this column vector as an index into the names of the columns of X.
/* For each row, find the variable name corresponding to the minimum value */ proc iml; use one; read all var _NUM_ into X[colname=VarNames]; close one; idxMin = X[, >:<]; /* find columns for min of each row */ varMin = varNames[idxMin]; /* corresponding var names */ print idxMin varMin; |

Yes, those two statements compute the same quantity as the complicated macro. And, if you are willing to nest the statements, you can combine them into a single statement:
varNames[X[, >:<]].
Finding the maximum value for each row is no more difficult: simply use the <:> subscript reduction operator.
The macro featured in the Knowledge Base article includes an option to compute with specified variables, rather than all numerical variables. That, too, is easily accomplished. For example, the following statements find the variable that has the largest value among the A, B, and C variables:
varNames = {a b c};
use one;
read all var varNames into X;
close one;
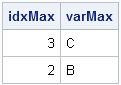
idxMax = X[,<:>];
varMax = varNames[idxMax];
print idxMax varMax; |
My next post will discuss subscript reduction operators in further details.
To my readers who are SQL experts: Is there a simple way to solve this problem by using PROC SQL? Leave a comment.

16 Comments
Neat tip. I'm DEFINITELY not a SQL expert. So I added a transpose step, then used SQL to grab the records of interest. Will look forward to seeing solution(s) from real SQL heads...
data one;
input a b c d e;
id=_n_; *create an ID for the transpose;
cards;
1 3 12 6 15
34 583 294 493 2
;
run;
proc transpose data=one out=two;
by id;
run;
proc sql;
select id, _name_ from two
group by id
having col1=min(col1)
;
quit;
id _NAME_
------------------
1 a
2 e
I totally agree with you on that there are better ways than the macro in Sample 46471. Maybe the sample is written a long time ago, when the newer functions were not available yet. Assuming that the numeric values are not very similar to each other finding out the variable name of the max value within an obs takes only a few lines in the data step:
This works too. IML is probably great, if you know IML. For me a data step is nice.
DATA two;
SET one;
ARRAY nums [*] a b c d e;
lowest=MIN(a, b, c, d, e);
DO i=1 TO DIM(nums);
IF nums[i]=lowest THEN lowestvar=VNAME(nums[i]);
END;
RUN;
Bingo..
It think its most easiest and simple way to doing the same. Awesome solution.
Thx a lot Dan.
Here's a small adaptation for datasets with a larger number of variables, when you don't want to list all of them. It also counts the number of times the minimum value occurs:
data two; set one;
array nums [*] _numeric_;
lowest=min(of nums[*]);
counter = 0;
do i=1 to dim(nums);
if nums[i]=lowest then do;
lowestvar = vname(nums[i]);
counter=counter+1;
end;
end;
run;
I imagine every method assumes there is always a unique minimum. When there isn't, do they all give the same partially right answer? Which method is best if you want to flag that there are ties?
The SAS/IML solution gives the first (leftmost) variable that contains the minimum.
The solution I posted above counts the ties.
I'm stuck using a CASE WHEN statement, but I can use DICTIONARY.COLUMNS to get the column names associated with the minimum values. PROC SQL does not do array style processing, hence the complications.
/* Data for Sample 46471: Return the variable name that contains
the max or min value across an observation */
;
data one;
input a b c d e;
cards;
1 3 12 6 15
34 583 294 493 2
;
run;
;
PROC SQL;
CREATE TABLE WORK.ONEMINS AS
SELECT MIN(a,b,c,d,e) AS MINVAL,
CASE
WHEN (a = calculated MINVAL) THEN 1
WHEN (b = calculated MINVAL) THEN 2
WHEN (c = calculated MINVAL) THEN 3
WHEN (d = calculated MINVAL) THEN 4
WHEN (e = calculated MINVAL) THEN 5
ELSE 9 END AS COLNUM
FROM WORK.ONE;
;
CREATE TABLE WORK.MINCOLS AS
SELECT uno.name, uno.varnum,dos.minval
FROM DICTIONARY.COLUMNS AS uno
RIGHT JOIN WORK.ONEMINS AS dos
ON uno.varnum=dos.colnum
WHERE uno.libname='WORK' AND uno.memname='ONE'
;
QUIT;
;
ODS HTML;
PROC PRINT DATa=WORK.MINCOLS ;
RUN;
ODS HTML CLOSE;
;
I have another question to expand on this topic-can you write code in which SAS can flag an observation with duplicate/tied maximum values. Say the dataset above is:
data one;
input ID a b c d e f;
cards;
4563 1 3 12 6 15 15
568 34 583 294 493 2 4
34 4 56 3 90 1 90
;
run;
I still want to obtain the maximum of the variables (a-f) but want to flag those observations in which the max is tied as for ID 4563 and 34 so that I know those observations I need to examine in a separate dataset.
Thank you, Cara
@Cara and other with general "how do I" questions:
SAS has many discussion forums where you can ask questions about how to compute various quantities in SAS. You can link to this post for background information, and then post your question.
Three of my favorites are:
1) The SAS/IML forum, for questions about how to compute quantities in the SAS/IML language
2) The SAS/STAT forum, for questions about how to compute statistical quantities in SAS
3) The SAS Macro and DATA step forum, which is great for DATA step and macro questions
How about these?
Method 1: Using data step
data two; set one;
MinValue=min(of a--e);
run;
Method 2: Using proc sql
proc sql;
create table three as
select *, min(a,b,c,d,e) as MinValue
from one;
quit;
If variable names are required programatically, proc contents could be used:
proc contents data=work.one out=one_c noprint; run;
DICTIONARY.COLUMNS could also be used to get variable names. However, that might increase the processing time if your library is having a large number of tables.
Now use an array variable to get the variable names in the desired format and use that in the data or the proc sql methods given above.
So, Method 1 will now be:
proc sql noprint;
select strip(NAME) into :VarNameString2
separated by '--'
from one_c
having VarNum =Min(VarNum) or VarNum =Max(VarNum)
order by VarNum;
quit;
data two_macro; set one;
MinValue=min(of &VarNameString2);
run;
And Method 2 will be:
proc sql noprint;
select strip(NAME) into :VarNameString
separated by ','
from one_c
order by VarNum;
create table three_macro as
select *, min(&VarNameString) as MinValue
from one;
quit;
To clarify, the goal is not to find the minimum value, but to find the name of the variable that contains the minimum value.
We can do this thing through array too..for eg.
data a;
input year jan feb mar apr may jun jul aug sep oct nov dec;
cards;
1997 123 343 324 5434 3454 1212 654 3443 212 4564 123 555
1998 253 2566 2535 5586 5595 9658 5874 5826 9562 9856 5585 5576
1999 524 548 2132 2413 6888 9989 7767 5576 990 6567 9897 9899
2000 3213 213 3122 3322 5434 7565 8759 8878 9494 4994 3233 2222
;
run;
data b ;
set a;
array mon(12) jan--dec;
array var(12) $var1-var12('jan' 'feb' 'mar' 'apr' 'may' 'jun' 'jul'
'aug' 'sep' 'oct' 'nov' 'dec');
do i = 1 to 12;
if max(of mon(*)) = mon(i) then Max = Var(i);
end;
run;
We can always put all the variables in another array and access them with the same iterator as the Max.
Or we can you vname() for the Variable name.
data c;
set a;
array max(12) jan--dec;
do i = 1 to 12;
if max(of max(*)) = max(i) then Max = Vname(max(i)); /* This will return the variable name */
end;
run;
Pingback: Determine whether a SAS product is licensed - The DO Loop
id visit result newvalue
01 1 30 .
01 2 25 30
01 3 45 25
01 4 14 25
01 5 5 14
02 1 29 .
02 2 13 29
02 3 23 13
02 4 34 13
02 5 7 13
creat the first three variable then min value creat newvalue then show upcase