Because the SAS/IML language is a general purpose programming language, it doesn't have a BY statement like most other SAS procedures (such as PROC REG). However, there are several ways to loop over categorical variables and perform an analysis on the observations in each category.
One way is to use the powerful UNIQUE-LOC technique, which I have blogged about several times and wrote about in my book, Statistical Programming with SAS/IML Software. This is a convenient technique when all of the data fit into memory and when there is a single BY variable.
However, sometimes you might need to process data that does not fit into RAM. In this case, you can use a DO loop to iterate over the categories and use WHERE processing inside the loop to read only a single BY group into memory (assuming each BY group fits). Furthermore, you might want to analyze the joint levels of several categorical variables, and it easy to compute the joint levels by using PROC FREQ.
Computing the BY groups
Suppose that you want to analyze the observations that correspond to joint categories of the Sashelp.Cars data set for the ORIGIN and TYPE variables. You can find the joint categories (and the number of observations in each) by using PROC FREQ, as shown in the following example:
/* find unique BY-group combinations */ proc freq data=Sashelp.Cars; tables Origin*Type / out=FreqOut; run; proc print data=FreqOut; run; |
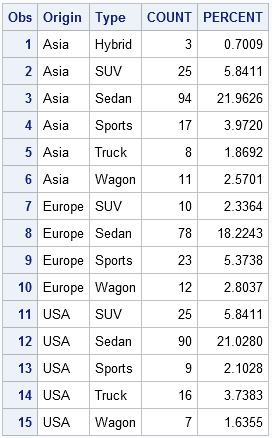
Notice that some potential 3x6 combinations do not appear in the data. For example, these data do not contain a European or American hybrid vehicle, nor a European truck.
Now suppose that you want to iterate over these 15 categories and do an analysis of the observations that belong to each. The next section shows how to proceed if the data set is so large that it doesn't fit into memory, but each individual BY group does fit into memory.
Analyzing BY groups in PROC IML
For the sake of the example, I'll compute a trivial statistic: the mean of each BY group. Doing this computation in SAS/IML software is completely unnecessary because you can compute it more efficiently with PROC MEANS, but the point of this example is to show how you can access the observations in each BY group within the SAS/IML language.
The following program reads the joint categories (the BY group levels) from the FreqOut data set into SAS/IML vectors. Then, for each BY group, it uses a READ statement with a WHERE clause to read only the observations in that BY group.
proc iml;
/* read unique BY groups */
use FreqOut nobs NumObs;
read all var {origin type};
close FreqOut;
varNames = {"MPG_City" "MPG_Highway"}; /* analysis variables */
use Sashelp.Cars; /* open data set for reading */
Mean = j(NumObs, ncol(varNames)); /* allocate results */
do i = 1 to NumObs; /* for each BY group */
read all var varNames into X /* read data for the i_th group */
where(Origin=(origin[i]) & Type=(type[i]));
/* X contains data for i_th group; analyze it */
Mean[i,] = mean(X);
end;
close Sashelp.Class;
print Origin Type Mean[label="" colname=varNames format=4.1]; |
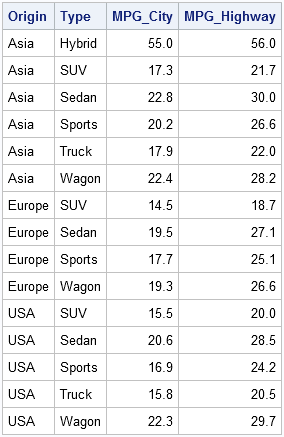
A few comments on this program:
- When the FreqOut data set is read, the NOBS keyword is used to store the number of observations (15) into the NumObs variable. This value is used to allocate the Mean array and to control the number of iterations in the DO loop.
- The program is not efficient in terms of reading the data. Notice that the program passes through the data 15 times, once for each BY group.
- Notice the syntax of the WHERE clause. In the expression WHERE(Origin=(origin[i])), the left side of the equal sign specifies a variable in the data set. The expression on the right side of the equal sign returns the ith element of the origin vector, which was read from the FreqOut data set. The parentheses around the expression are required.
I'll repeat this isn't an efficient way to read data compared to reading it all at once. However, this technique might be necessary when the data set is large. It can also be used when the groups that should be analyzed are specified in a data set such as FreqOut. It is not necessary that the data set contain all levels of the BY groups. For example, if you want to analyze data for a handful of vehicle types (or states, or counties, ...), you can use this approach to read only the data for groups that you are interested in.
This same technique is also a way to avoid calling a SAS/IML program in a macro %DO loop. Some programmers like to write a program that handles a single subgroup and then use a macro loop to subset their data and call the program on each subset. (For example, the program might analyze one year's worth of data, and you want to call it for all the years 1990–2010.) I find it difficult to debug and modify programs that have lots of macro variables and are embedded in a macro loop. Therefore I prefer the technique presented here, which avoid using macro statements.

5 Comments
Hi Rick,
Just a comment. All combinations of by groups can be obtained artificially from the SPARSE options in proc freq.
Best,
Todd
Thanks. For this application we don't want all POSSIBLE levels, we only want the levels that actually occur in the data.
Pingback: Indexing a SAS data set to improve processing categories in SAS/IML - The DO Loop
Hi Rick,
I'm pretty new at IML. I tried to transfer your post to my data. Unfortunately, it did not work. Is it possible to e-mail to you for discussing my problem?
Thanks,
Betty
Welcome to SAS/IML. For help with SAS/IML issues, post your questions to the SAS/IML Discussion Forum.