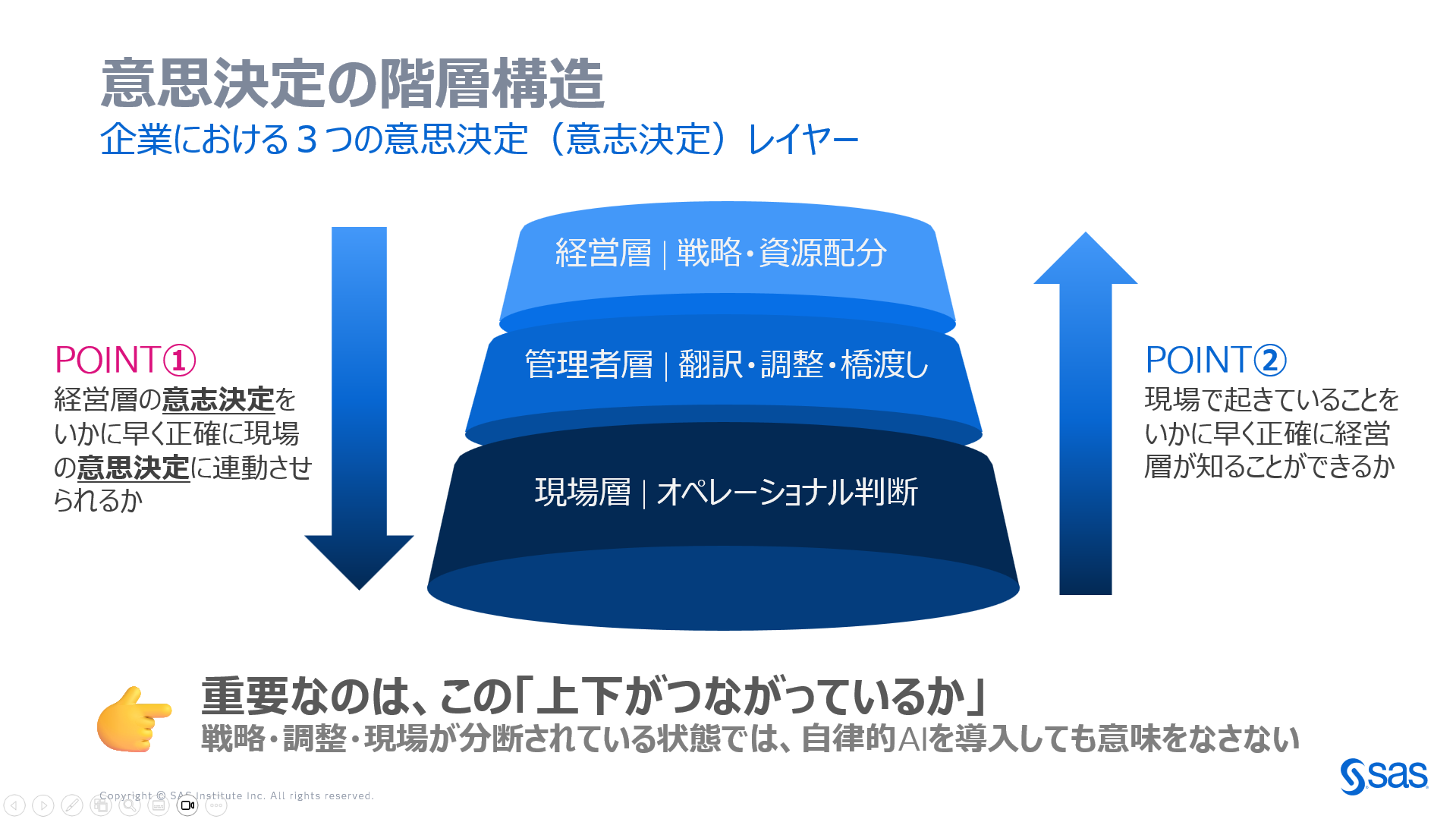
企業・組織がデータをまとめることに躍起になっている間に、本質を見失っていることが多く見受けられます。 データは手段であり、目的ではありません。 「データ統合」という言葉を、皆さんは何度耳にされているでしょうか。 経営会議で、ITロードマップで、ベンダー提案書で。まるで呪文のように繰り返されるこの言葉に、私はずっと違和感を覚え意義をとなえ続けています。 結論を先に言います。「データ統合」は、そのままでは意味をなさない概念です。 本当に企業が取り組むべきは「意思決定の統合」であり、データはその手段に過ぎません。 1.「データ統合」はそもそも何を指しているのか 実は私はそこをあまりわかっていません。なぜなら私の中にその概念がないためです。ただ世の中での「データ統合」という言葉の使われ方から推察すると、実際には二つの異なる意味で使われているように見受けられます。 💡キーポイント: 「①置く統合」はメッシュアーキテクチャで不要になりつつある。 「②加工の統合」はそれ自体が目的ではなく、意思決定改善という目的への手段に過ぎない。 どちらの解釈においても、「データ統合」は価値あるものとしては定義できない。 2.データは組織を動かさない Data doesn't drive your organization. Decisions do. こちらのブログで詳しくお話していますが、データは組織を動かしません。意思決定が組織を動かします。 これは私が日頃お伝えしているメッセージですが、「データ統合」という言葉が流行するとき、この順序が逆転していることが多いです。 自律型AIエージェント時代の意思決定~ROI創出とリスク管理を「技術」ではなく「意思決定」で整理する 3.「統合データベース」という幻想 仮にデータ統合という意味が正確に定義できなくても明らかに手段であるものではなく、目的志向で、「すべての意思決定モデルを格納した統合データベース」を作ろうとすると、どうなるでしょうか。 企業の中で生まれる意思決定は無数にあります。価格設定、在庫補充、顧客対応、採用、設備投資、与信判断、リスク管理……それぞれの意思決定は、固有のコンテキスト・時間軸・責任者を持ち、互いに複雑に干渉し合っています。 それらすべてを網羅する「統合データベース」などは、私が知る限り現時点では現実的に存在しないですし、仮に存在したとしても、その構築自体がナンセンスだと思います。なぜなら意思決定間の相互作用は、設計段階では分からない部分が多く、実際に動かしてみて初めてわかる側面も大きいからです。 4.意思決定の構造① - 組織の階層構造 企業の意思決定を正しく捉えるには、まずその階層構造を理解する必要があります。 重要なのは、この三層が「つながっているか」です。 経営層の「意志決定」がいかに早く正確に現場の「意思決定」に連動するか。 現場で起きていることがいかに早く正確に経営層にフィードバックされるか。 この双方向の連動がなければ、どれだけデータを集めても、どれだけAIを導入しても、意味をなしません。 💡キーポイント:意思決定と意志決定の違い 「意思決定(Decision-making)」はデータと論理に基づく合理的な選択であり、AIが担える領域。 「意志決定(Commitment)」は責任を持って結果にコミットする判断であり、人間の領域。 データ活用の議論では、この二つが混同されることが多い。 5.「意思決定の統合」こそが本質的なチャレンジ 企業が経営指標を改善するプロセスを整理すると、以下の縦のバリューチェーンが見えてきます。 経営層が意志決定をする - 戦略目標・KPI・資源配分を定義し、「何を最適化するか」にコミットする。 管理者層が翻訳・調整する - 経営の意図を各部門の言葉と判断基準に変換し、部門間の整合を取る。 現場が意思決定をし、バリューチェーン全体で最適化する - 日々のオペレーションの中でデータとモデルを使った判断を実行する。部門をまたがった判断が全体最適につながる。