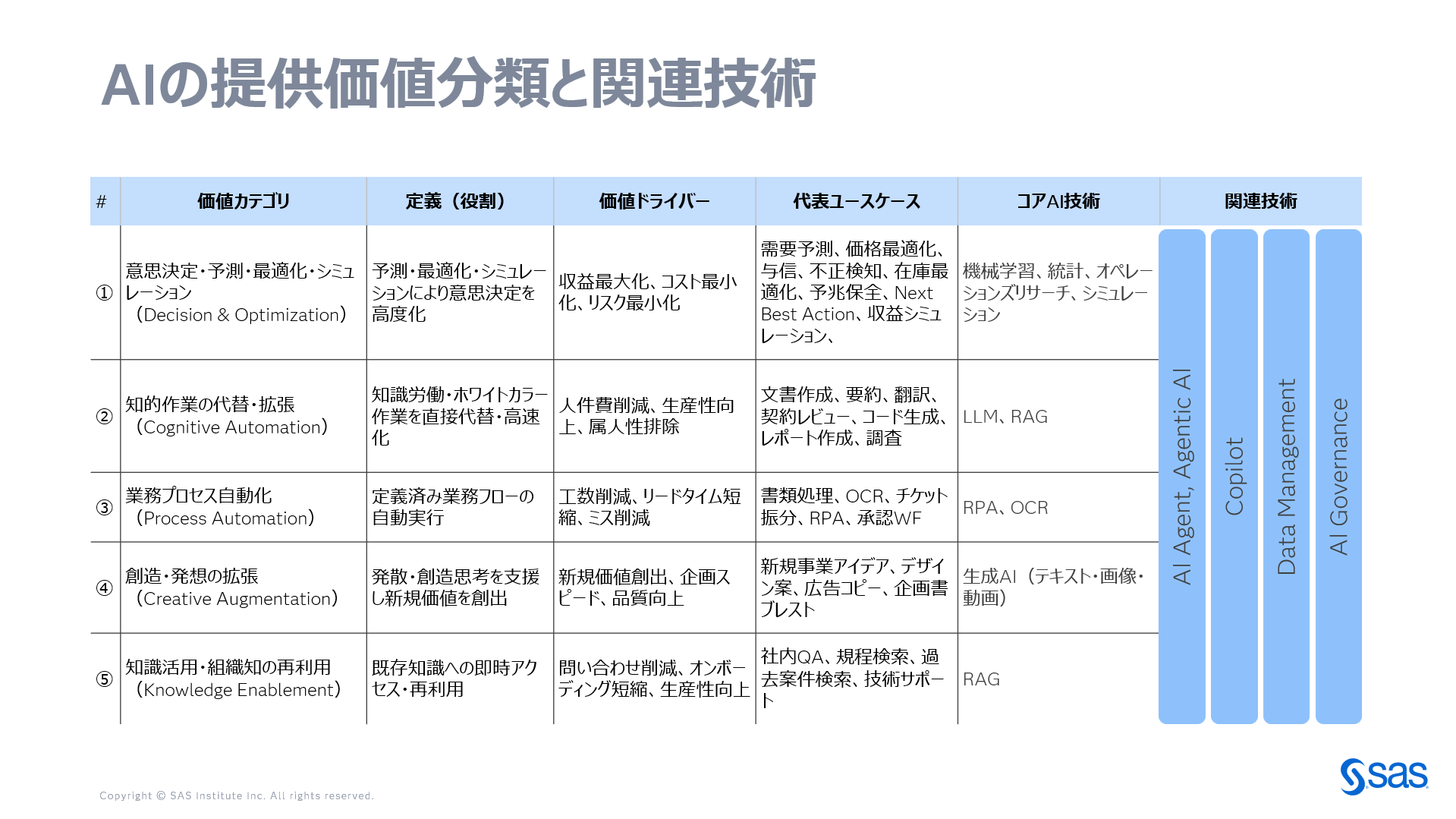

AI投資におけるバイアス 昨今、AIというと主に生成AI、LLM、Copilotなどの技術を指していることが多いですよね。それは、IT市場が長年そうであるように、「新奇性バイアス」(新しいものを過大評価してしまう人間の脳の特性)や、FOMO効果(取り残されることへの不安)、さらには「ハロー効果」(肩書にひきずられる心理現象)など、いわゆる認知バイアスによって、認知や期待がゆがめられている影響もあります。また、それに乗じて、もちろんビジネスにおける競争戦略としては当然なのですが、新しいテクノロジーでマーケットに参入したい企業や、関心を集めたいメディアも、こぞって流行りの単語を使うため、人間の認知バイアスをさらに増幅させる構造がそこにあるためです。 しかし、そうしたバイアスが実は事業会社が適切に行動することを阻害しているのもまだ事実です。今回は、そういったバイアスに惑わされずAIへの投資をより適切にするための一つの考え方をご紹介します。 AI技術への投資判断の評価がしづらい理由 AI技術は、冒頭で触れたようにさまざまな認知バイアスの影響を受けやすく、企業が自らの戦略を十分に整理しないまま、「導入そのもの」が目的化してしまうケースが少なくありません。もちろん、企業・組織自身が自社の課題を正しく見つめ、成長戦略の中でどのようにAIによる価値を享受していくかを計画的に検討し、推進している企業も存在します。ただし、それが多数派かというと、決してそうではないのが実情です。 AI導入が目的化してしまっている企業・組織では、次のような混乱をよく目にします。 AIの導入が、LLMやチャットシステムの導入そのものと同一視されている AI Agent、Agentic AI、Copilotといった概念の違いが曖昧なまま議論が進んでいる 技術要素と提供価値が混在したまま語られている 重要度の整理がされていないため、「とりあえず何でもPoC」という状態に陥っている プロフィット部門である業務部門が十分に巻き込まれず、コストセンターであるIT部門やDX部門、データサイエンス部門が、技術や基盤の導入目的だけで検討を進めてしまっている その結果、「結局、我々はAIでどのような価値を生み出そうとしているのか」という点について、組織内で明確なコンセンサスを得ることなく、IT部門やDX部門を中心に個別の施策やPoCだけが増えていきます。これは技術の問題ではなく、目的が定義・共有されていないことに起因するものです。 AI活用が叫ばれて久しい中で、経営層から「成果の実感がない」と感じられる理由の多くは、「どの価値の話をしているのかが整理されていない」ことにあります。 そこで本稿では、AIという一言では括れない幅広い提供価値と、それを支える関連技術を整理することで、経営層と現場、部門間の共通理解を促し、適切な投資判断と、より確実な成果創出につなげるための一助としたいと考えています。 分類の基準:AIは「技術」ではなく「提供価値」で整理すると投資判断に使える AIの話題になると、IT部門やDX部門、さらにはメディアにおいても、技術スタックやモデル、アルゴリズムの種類から議論が始まりがちです。しかし、売上向上やコスト削減の責任を担う業務部門の外側で、技術の話に終始するアプローチでは、言うまでもなくビジネス上の成果は生まれません。 IT部門やDX部門だけでなく、経営層や業務部門を巻き込み、透明性と説明責任を果たす投資活動にするためには、「AI技術」ではなく、「AI活用によってどのような価値を提供するのか」という視点でのコミュニケーションが不可欠です。 20年以上この業界に携わってきた経験から、AIの提供価値を以下の5つに大きく分類してみました。 1. 意思決定・予測・最適化・シミュレーション(Decision & Optimization) AI活用の原点とも言えるのが、この領域です。需要予測、価格最適化、与信、不正検知、在庫最適化、Next Best Action、収益・財務シミュレーションなど、すでに多くの企業で実運用されています。 ここでAIが提供しているのは、人の直感や経験だけでは扱いきれない複雑さを、数理モデルによって扱えるようにする価値です。機械学習(ML)、統計、オペレーションズリサーチ(OR)、シミュレーションといった技術は、この価値を支える基盤として長年活用されてきました。 2. 知的作業の代替・拡張(Cognitive Automation) 生成AIの登場によって、最も注目を集めているのがこのカテゴリでしょう。文書作成、要約、翻訳、契約レビュー、コード生成、レポート作成、調査業務など、これまで人が時間をかけて行ってきた知的作業を、AIが直接代替したり、大幅に高速化したりします。 価値は単なる省力化にとどまりません。業務のスピードと均質性を高め、属人性を下げる点にあります。LLMやRAGは、この提供価値を成立させる代表的な技術です。 3. 業務プロセス自動化(Process Automation) 業務プロセス自動化は、定義された業務フローを正確に、繰り返し実行することに価値があります。書類処理、OCR、チケット振り分け、RPA、承認ワークフローなど、対象は明確で、成果も測定しやすい領域です。工数削減、リードタイム短縮、ミス削減といった効果が、比較的早期に表れます。 AI活用の中では地味に見えるかもしれませんが、組織にとっては欠かせない実践領域です。 4. 創造・発想の拡張(Creative Augmentation) このカテゴリでは、AIは人の代替ではなく、思考の相棒として機能します。新規事業アイデア、デザイン案、広告コピー、企画書、プレゼンテーションなどにおいて、生成AIは発散と試行錯誤の回数を増やし、人の発想を押し広げます。 成果の定量化は容易ではありませんが、新しい価値を生み出す力という観点では、今後ますます重要になる領域です。 5. 知識活用・組織知の再利用(Knowledge Enablement) 多くの組織には、すでに膨大な知識が蓄積されています。しかし、それらが必ずしも「使える形」になっているとは限りません。社内QA、規程検索、過去案件検索、技術サポートなどにAIを活用することで、知識へのアクセスコストを下げ、再利用を促進できます。RAGは、この提供価値を支える代表的な技術です。 企業によって、5つの提供価値への投資優先順位は異なる ここで、もう一つ重要な点を補足しておきます。この5つの提供価値は、すべての企業で同じ重要度を持つわけではありません。業種、企業規模、事業フェーズによって、どこに重心が置かれるかは大きく異なります。 例えば、