先日投稿した「機械学習のパラメータをオートチューニングしよう(分類編)!」の続きです。
今回は回帰分析をオートチューニングします。
あらまし
機械学習の課題はパラメータチューニングで、手動で最高のパラメータを探そうとすると、とても時間がかかり効率的ではありません。
SAS Viyaではパラメータチューニングを自動化するオートチューニング機能を提供しています。
オートチューニング機能を使うことで、限られた時間内、条件下で最高のパラメータを探索し、予測モデルを生成することができます。

今回やること
今回はオートチューニングを使って数値予測モデルを生成します。
使うデータは架空の銀行の金融商品販売データです。顧客の取引履歴と営業履歴から構成されており、新たな金融商品の販売数を予測するデータとなっています。
内容は以下のようになっており、約5万行、22列の構成です。
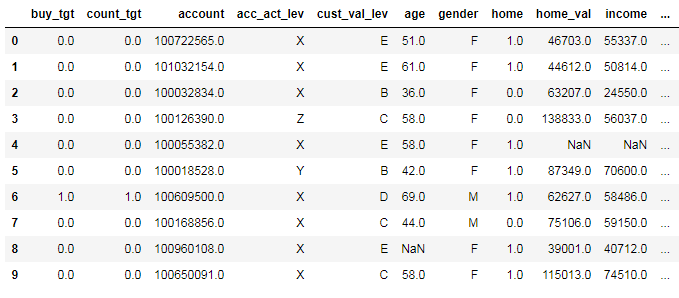
1行1お客様データとなっていて、顧客の口座情報や取引履歴、営業履歴が1行に収納されています。
ターゲット変数はcount_tgtで、これは各顧客が購入した金融商品数を表しています。
ほとんどが0(=未購入)ですが、購入されている顧客の購入数を予測するモデルを生成します。
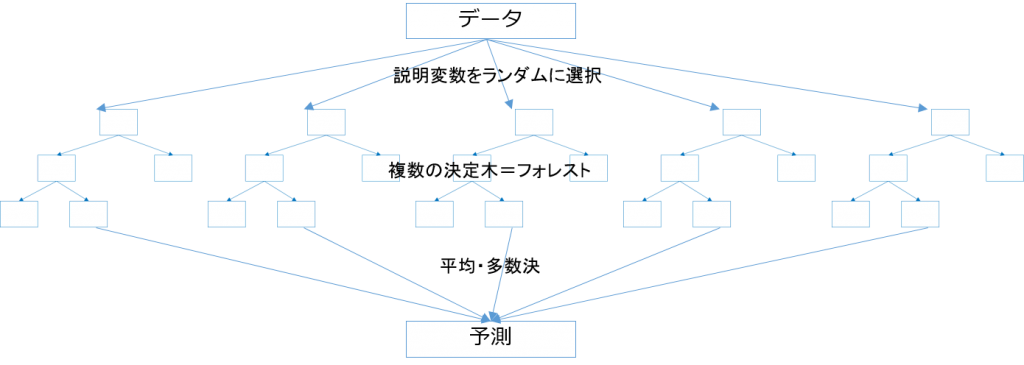
今回はランダムフォレストを使って予測したいと思います。
ランダムフォレストは別々の決定木を複数作り、各決定木の予測値をアンサンブルして最終的な予測値とする機械学習の一種です。
まずは手動で予測
SAS Viyaでランダムフォレストを使って予測モデルを生成するにあたり、まずはCASセッションを作ってトレーニングデータとテストデータをインメモリにロードします。
# PythonからCASを操作するためのSWATライブラリをインポート import swat # 接続先ホスト名、ポート番号、ユーザー名、パスワードを指定 host = "localhost" port = 5570 user = "cas" password = "p@ssw0rd" # mysessionという名称のCASセッションを作成 mysession = swat.CAS(host, port, user, password) # /opt/handson/ディレクトリにmycaslibというCASLIBを作成 add_caslib = mysession.table.addCaslib( dataSource = {"srcType" : "PATH"}, name = "mycaslib", path = "/opt/handson", session = True, ) # bank_trains, bank_testsをmycaslibにロード bank_trains = mysession.load_path("bank_trains.csv", caslib='mycaslib') bank_tests = mysession.load_path("bank_tests.csv", caslib='mycaslib') |
データはあらかじめトレーニングデータ47,186行、テストデータ5,243行に分割されています。
トレーニングデータを使って予測モデルを生成し、テストデータでモデルを評価します。
まずはオートチューニングなしでランダムフォレストの予測モデルを生成し、評価します。
# アクションセットをロード mysession.loadactionset("decisionTree") # ランダムフォレストによる学習 bankRF = mysession.decisionTree.forestTrain( table={"caslib":"mycaslib", "name":"bank_trains"}, # 入力データとしてbankTrainImputedを指定 target="count_tgt", # ターゲット変数 inputs={"age", "home_val", "income", "ave_sale_3yr", "ave_sale_lt", "ave_sale_3yr_promo", "last_purchase", "cnt_purch_3yr", "cnt_purch_lt", "cnt_purch_3yr_promo", "cnt_purch_lt_promo", "mnth_since_last_purch", "cnt_tot_promo", "cnt_dir_promo","cust_tenure", "acc_act_lev", "cust_val_lev", "gender", "home"}, # 説明変数 nominals={"acc_act_lev", "cust_val_lev", "gender", "home"}, # 名義尺度となる説明変数 casOut={"caslib":"mycaslib", "name":"bank_rf_model_cnt", "replace":True}, # 出力するスコアリングモデル名 varImp=True, # 重要な説明変数を表示 # ランダムフォレストのハイパーパラメータ oob=True, leafSize=5, maxLevel=6, nBins=20, nTree=50 ) # スコアリング rfScore = mysession.decisionTree.forestScore( # スコアリング対象にbankTestImputedを指定 table={"caslib":"mycaslib", "name":"bank_tests"}, # モデル名 modelTable={"caslib":"mycaslib", "name":"bank_rf_model_cnt"}, # 出力テーブル名 casOut={"caslib":"mycaslib", "name":"bank_rf_scored_cnt", "replace":True}, # テーブルにコピーする変数 copyVars={"count_tgt"} ) # テストデータのスコアリング結果をアセスメント rfAssess = mysession.percentile.assess( table={"name":"bank_rf_scored_cnt"}, inputs=[{"name":"_RF_PredMean_"}], response="count_tgt", ) # リフトチャートを表示 import matplotlib.pyplot as plt meant = rfAssess.LIFTRegInfo["meanT"] meanp = rfAssess.LIFTRegInfo["meanP"] plt.figure(figsize=(12,8)) plt.plot(meant, "r-", label="Target") plt.plot(meanp, "b-", label="Prediction") plt.xlabel("Depth") plt.ylabel("Response") plt.grid(True) plt.legend(loc="best") plt.title("Lift Chart") plt.show() |
プログラムの最後でリフトチャートを表示します。
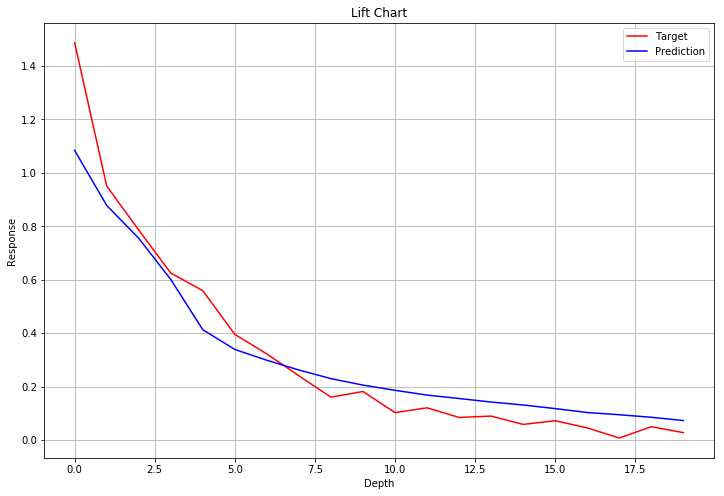
リフトチャートは予測値と正解値の乖離具合を可視化します。予測値を降順に並べ替え、263個ずつビン化します。各ビンの予測値の平均と正解値の平均をプロットしたのがリフトチャートになります。
高い数値を予測した値から順に予測値と正解値の離れ具合を可視化することで、予測モデルがどのあたりの予測値で良い予測ができているのか(または良い予測ができていないのか)がひと目でわかるようになります。
また、どのあたりの予測値が正解値より低く推定され、どのあたりの予測値が正解値より高く推定されるか、傾向を見ることも可能です。
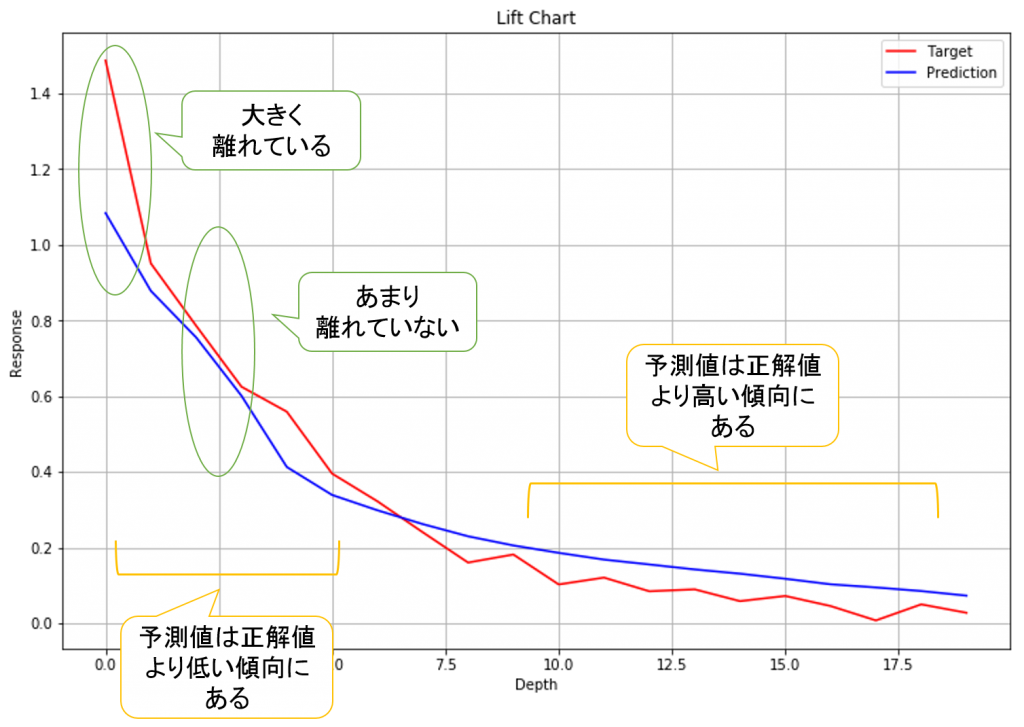
リフトチャートをみると、全体的に予測値と正解値が離れているようです。もう少し良い予測モデルを作れるか、オートチューニングを試してみましょう。
オートチューニング
オートチューニングでランダムフォレストの数値予測モデルを生成します。
# autotuneアクションセットをロード mysession.loadactionset("autotune") # ランダムフォレストにオートチューニングを適用 bankATRF = mysession.autotune.tuneForest( trainOptions={ 'table' : {'name':'bank_trains'}, # テーブル名を指定 'target':"count_tgt", # ターゲット変数 'inputs':{"cnt_purch_3yr", "cnt_purch_3yr_promo", "mnth_since_last_purch", "cnt_purch_lt", "home_val", # 説明変数 "cnt_purch_lt_promo", "cust_tenure", "cnt_dir_promo", "cust_val_lev", "acc_act_lev", "cnt_tot_promo"}, 'nominals':{"acc_act_lev", "cust_val_lev"}, # 名義尺度となる説明変数 'casOut':{"name":"bank_atrf_model_cnt", "replace":True}, # 出力するスコアリングモデル名 }, tunerOptions={ # オートチューニングの制限時間やチューニングアルゴリズム等々を指定。 'maxEvals': 100, # 最大検証回数 'maxTime': 1200, # 最長検証時間(秒) 'searchMethod': 'GA', # チューニングアルゴリズム。選択肢:GA, Bayesian, LHS, Random 'seed': 123456, # ランダムシード 'objective': 'RASE' # 目的関数。選択肢:'ASE', 'AUC', 'F05', 'F1', 'GAMMA', 'GINI', 'KS', 'MAE', 'MCE', # 'MCLL', 'MISC', 'MSE', 'MSLE', 'RASE', 'RMAE', 'RMSLE', 'TAU' }, # 探索するハイパーパラメータの制限値 tuningParameters=[{ 'namePath': 'maxLevel', # ランダムフォレストを構成する決定木の深さを10から20の間に指定 'lowerBound': 10, 'upperBound': 30 }, { 'namePath': 'nTree', # ランダムフォレストを構成する決定木の数を指定 'lowerBound': 50, # 下限だけ(または上限だけ)を指定することも可能 }] ) |
書き方は前回同様です。
- trainOptions: データセットや変数を設定。
- tunerOptions: オートチューニングの制限値や探索アルゴリズム、目的関数を指定。
- tuningParameters: ランダムフォレストのパラメータに制限を指定。
トレーニングデータの容量が前回より大きく、ランダムフォレストのモデル生成も決定木より負荷が重いため、今回はトレーニングが完了するのに時間がかかります。
tunerOptionsにmaxTimeを1,200秒と指定することで、パラメータ探索は最長で20分に制限しています。20分程度であれば、ちょっと休憩している間に最適なパラメータ探索が完了します。
オートチューニングで生成した予測モデルをテストデータで評価します。
# スコアリング atrfScore = mysession.decisionTree.forestScore( # スコアリング対象にbankTestImputedを指定 table={"caslib":"mycaslib", "name":"bank_tests"}, # モデル名 modelTable={"caslib":"mycaslib", "name":"bank_atrf_model_cnt"}, # 出力テーブル名 casOut={"caslib":"mycaslib", "name":"bank_atrf_scored_cnt", "replace":True}, # テーブルにコピーする変数 copyVars={"count_tgt"} ) # テストデータのスコアリング結果をアセスメント atrfAssess = mysession.percentile.assess( table={"name":"bank_atrf_scored_cnt"}, inputs=[{"name":"_RF_PredMean_"}], response="count_tgt", ) # リフトチャートを表示 import matplotlib.pyplot as plt meant = atrfAssess.LIFTRegInfo["meanT"] meanp = atrfAssess.LIFTRegInfo["meanP"] plt.figure(figsize=(12,8)) plt.plot(meant, "r-", label="Target") plt.plot(meanp, "b-", label="Prediction") plt.xlabel("Depth") plt.ylabel("Response") plt.grid(True) plt.legend(loc="best") plt.title("Lift Chart") plt.show() |
最後にリフトチャートを表示します。
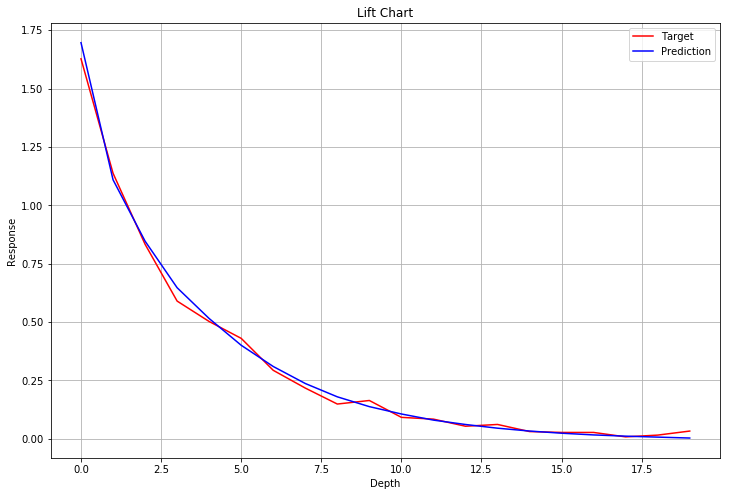
ご覧のとおり予測値と正解値がほぼ重なっており、手動で生成した予測モデルよりも精度の高いモデルとなっていることがわかります。
SAS Viyaのオートチューニングは分類、回帰のいずれでも適用可能で、特定の条件下(制限時間等々)に最適な予測モデルを作ることが可能です。
おまけ
今回作ったプログラムの全文です。
# PythonからCASを操作するためのSWATライブラリをインポート import swat # 接続先ホスト名、ポート番号、ユーザー名、パスワードを指定 host = "localhost" port = 5570 user = "cas" password = "p@ssw0rd" # mysessionという名称のCASセッションを作成 mysession = swat.CAS(host, port, user, password) # /opt/handson/ディレクトリにmycaslibというCASLIBを作成 add_caslib = mysession.table.addCaslib( dataSource = {"srcType" : "PATH"}, name = "mycaslib", path = "/opt/handson", session = True, ) # bank_trains, bank_testsをmycaslibにロード bank_trains = mysession.load_path("bank_trains.csv", caslib='mycaslib') bank_tests = mysession.load_path("bank_tests.csv", caslib='mycaslib') # アクションセットをロード mysession.loadactionset("decisionTree") # ランダムフォレストによる学習 bankRF = mysession.decisionTree.forestTrain( table={"caslib":"mycaslib", "name":"bank_trains"}, # 入力データとしてbankTrainImputedを指定 target="count_tgt", # ターゲット変数 inputs={"age", "home_val", "income", "ave_sale_3yr", "ave_sale_lt", "ave_sale_3yr_promo", "last_purchase", "cnt_purch_3yr", "cnt_purch_lt", "cnt_purch_3yr_promo", "cnt_purch_lt_promo", "mnth_since_last_purch", "cnt_tot_promo", "cnt_dir_promo","cust_tenure", "acc_act_lev", "cust_val_lev", "gender", "home"}, # 説明変数 nominals={"acc_act_lev", "cust_val_lev", "gender", "home"}, # 名義尺度となる説明変数 casOut={"caslib":"mycaslib", "name":"bank_rf_model_cnt", "replace":True}, # 出力するスコアリングモデル名 varImp=True, # 重要な説明変数を表示 # ランダムフォレストのハイパーパラメータ oob=True, leafSize=5, maxLevel=6, nBins=20, nTree=50 ) # スコアリング rfScore = mysession.decisionTree.forestScore( # スコアリング対象にbankTestImputedを指定 table={"caslib":"mycaslib", "name":"bank_tests"}, # モデル名 modelTable={"caslib":"mycaslib", "name":"bank_rf_model_cnt"}, # 出力テーブル名 casOut={"caslib":"mycaslib", "name":"bank_rf_scored_cnt", "replace":True}, # テーブルにコピーする変数 copyVars={"count_tgt"} ) # テストデータのスコアリング結果をアセスメント rfAssess = mysession.percentile.assess( table={"name":"bank_rf_scored_cnt"}, inputs=[{"name":"_RF_PredMean_"}], response="count_tgt", ) # リフトチャートを表示 import matplotlib.pyplot as plt meant = rfAssess.LIFTRegInfo["meanT"] meanp = rfAssess.LIFTRegInfo["meanP"] plt.figure(figsize=(12,8)) plt.plot(meant, "r-", label="Target") plt.plot(meanp, "b-", label="Prediction") plt.xlabel("Depth") plt.ylabel("Response") plt.grid(True) plt.legend(loc="best") plt.title("Lift Chart") plt.show() # autotuneアクションセットをロード mysession.loadactionset("autotune") # ランダムフォレストにオートチューニングを適用 bankATRF = mysession.autotune.tuneForest( trainOptions={ 'table' : {'name':'bank_trains'}, # テーブル名を指定 'target':"count_tgt", # ターゲット変数 'inputs':{"cnt_purch_3yr", "cnt_purch_3yr_promo", "mnth_since_last_purch", "cnt_purch_lt", "home_val", # 説明変数 "cnt_purch_lt_promo", "cust_tenure", "cnt_dir_promo", "cust_val_lev", "acc_act_lev", "cnt_tot_promo"}, 'nominals':{"acc_act_lev", "cust_val_lev"}, # 名義尺度となる説明変数 'casOut':{"name":"bank_atrf_model_cnt", "replace":True}, # 出力するスコアリングモデル名 }, tunerOptions={ # オートチューニングの制限時間やチューニングアルゴリズム等々を指定。 'maxEvals': 100, # 最大検証回数 'maxTime': 1200, # 最長検証時間(秒) 'searchMethod': 'GA', # チューニングアルゴリズム。選択肢:GA, Bayesian, LHS, Random 'seed': 123456, # ランダムシード 'objective': 'RASE' # 目的関数。選択肢:'ASE', 'AUC', 'F05', 'F1', 'GAMMA', 'GINI', 'KS', 'MAE', 'MCE', # 'MCLL', 'MISC', 'MSE', 'MSLE', 'RASE', 'RMAE', 'RMSLE', 'TAU' }, # 探索するハイパーパラメータの制限値 tuningParameters=[{ 'namePath': 'maxLevel', # ランダムフォレストを構成する決定木の深さを10から20の間に指定 'lowerBound': 10, 'upperBound': 30 }, { 'namePath': 'nTree', # ランダムフォレストを構成する決定木の数を指定 'lowerBound': 50, # 下限だけ(または上限だけ)を指定することも可能 }] ) # スコアリング atrfScore = mysession.decisionTree.forestScore( # スコアリング対象にbankTestImputedを指定 table={"caslib":"mycaslib", "name":"bank_tests"}, # モデル名 modelTable={"caslib":"mycaslib", "name":"bank_atrf_model_cnt"}, # 出力テーブル名 casOut={"caslib":"mycaslib", "name":"bank_atrf_scored_cnt", "replace":True}, # テーブルにコピーする変数 copyVars={"count_tgt"} ) # テストデータのスコアリング結果をアセスメント atrfAssess = mysession.percentile.assess( table={"name":"bank_atrf_scored_cnt"}, inputs=[{"name":"_RF_PredMean_"}], response="count_tgt", ) # リフトチャートを表示 import matplotlib.pyplot as plt meant = atrfAssess.LIFTRegInfo["meanT"] meanp = atrfAssess.LIFTRegInfo["meanP"] plt.figure(figsize=(12,8)) plt.plot(meant, "r-", label="Target") plt.plot(meanp, "b-", label="Prediction") plt.xlabel("Depth") plt.ylabel("Response") plt.grid(True) plt.legend(loc="best") plt.title("Lift Chart") plt.show() mysession.close() |
