All Posts


As we move into the Thanksgiving holiday and celebrate #givingTuesday, it’s a perfect time to reflect on thankfulness. The attitude of gratitude is enriching and has been shown to have many benefits. I use this approach often as I teach a variety of wellness classes. Although I practice what I
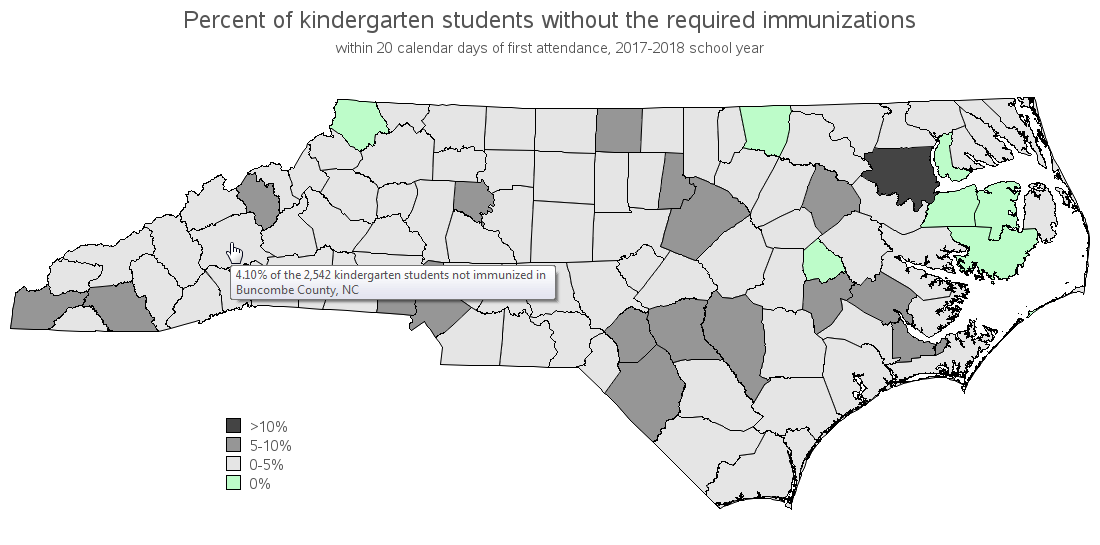

I recently read an article that said a school in Asheville, North Carolina had the worst chickenpox outbreak in the state in 2 decades. The article was interesting, and it also let me know I had a hole in my knowledge ... "What?!? - There's a chickenpox vaccine?!?" When I
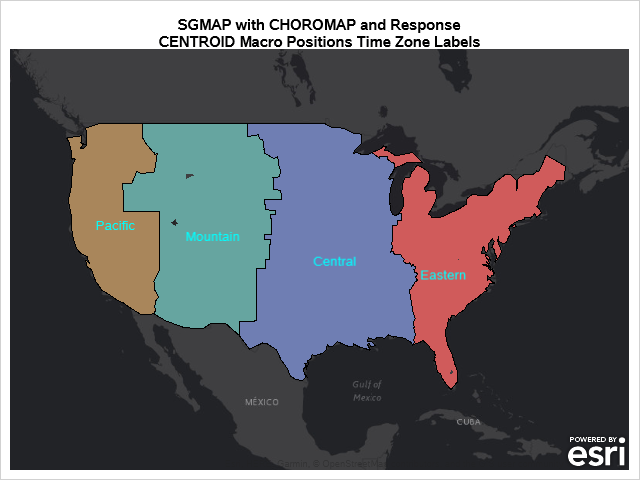

Starting with SAS 9.4M6, procedures that used to be provided with a SAS/GRAPH installation are now available with Base SAS. Using these procedures along with PROC SGMAP can help you create some very nice maps. This blog builds on previous posts and highlights the: MAPSSAS Data Sets GREMOVE procedure %CENTROID


은행은 금융위기와 같은 경제적 충격이 외부에서 발생했을 때 채무 불이행에 따른 손실 규모를 파악하고 보유하고 있는 위험자산에 대한 포트폴리오 변화를 빠르게 확인할 수 있어야 하는데요. 특히 글로벌 금융위기 이후 은행권을 대상으로 글로벌 경제 위기에 견딜 수 있는 재무 건전성 역량을 문서화하는 규제요구가 높아지면서 대형 투자은행들이 경제 상황이 극도로 나빠졌을 때


What is object detection? Object detection, a subset of computer vision, is an automated method for locating interesting objects in an image with respect to the background. For example, Figure 1 shows two images with objects in the foreground. There is a bird in the left image, while there is a dog
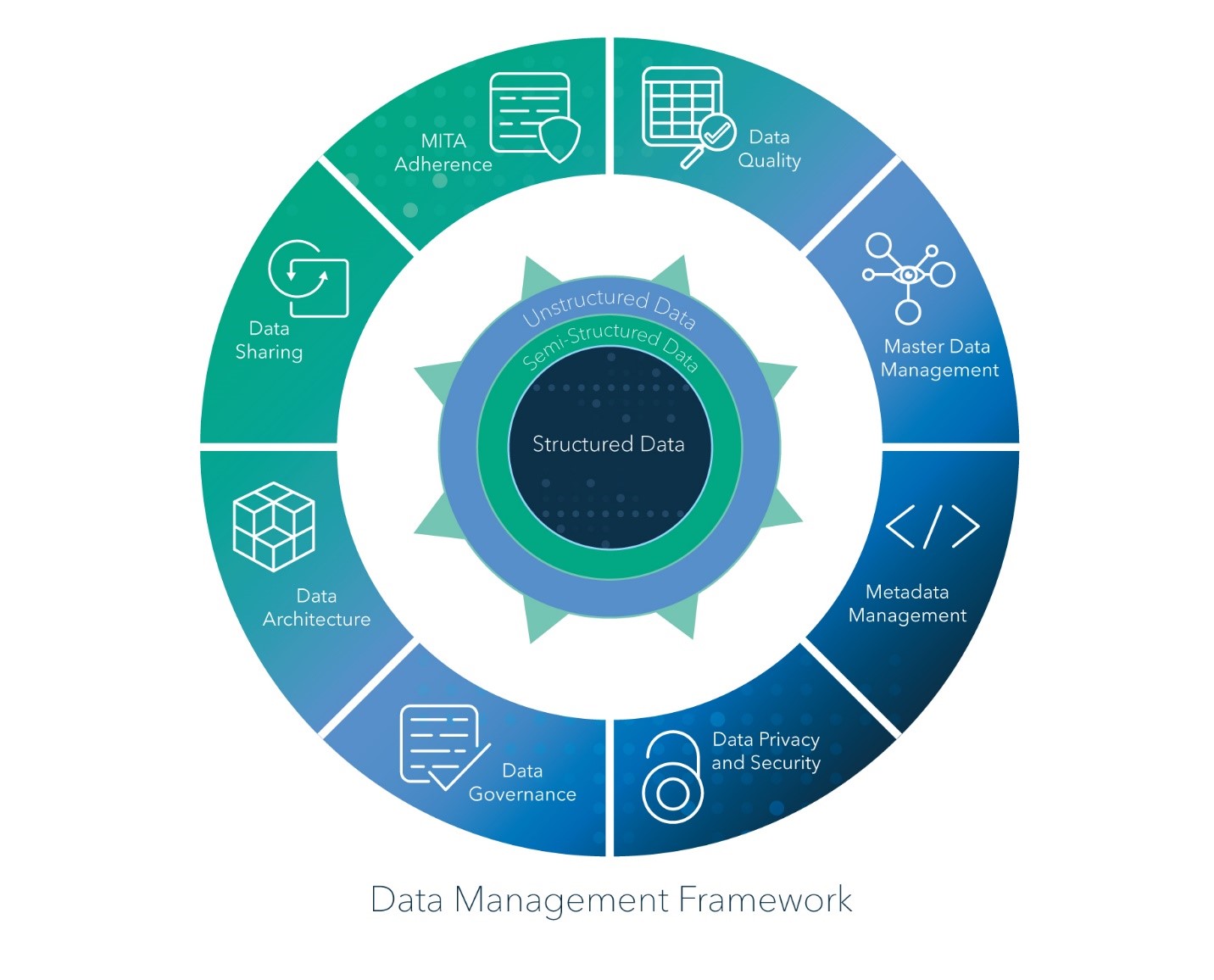

Data management gets lost in the enthusiasm around Artificial intelligence (AI) and machine learning (ML). Not surprising, when it's an algorithm that decides what search results to show you, guides the self-driving cars on the roads, and powers the anti-fraud bots that monitor every credit card transaction we make. Charles


Reconsider conventional assumptions about data governance – three suggestions for chief data officers.

머신러닝이 마케팅 생태계 내에서 지속적으로 발전함에 따라 현대화된 알고리즘 접근법의 해석력이 중요해지고 있습니다. 지난 번 게시했던 머신러닝 해석력 관련 블로그에서 인공지능(AI)과 머신러닝을 신뢰하기 위한 필수 조건, 데이터 세트를 이해하고 해석하는 방법, 그리고 머신러닝 모델의 작동 원리에 대한 인사이트를 도출하는 변수를 표시하는 방법에 대해 설명한 바 있는데요. “우리는 머신러닝에 의해 구동되는 애플리케이션에 둘러싸여 있으며,


SAS was again named a Top 10 Place to Work in the World by Great Places to Work™. This is quite an honor, and one which SAS has enjoyed for the past eight years. SAS has also been a highly ranked work place in the US for the past 20


You might know that you can use the ODS SELECT statement to display only some of the tables and graphs that are created by a SAS procedure. But did you know that you can use a WHERE clause on the ODS SELECT statement to display tables that match a pattern?


La conexión de objetos cotidianos a Internet ha evolucionado tanto en los últimos años, que ahora es posible conectar desde electrodomésticos y equipos de salud, hasta elementos de medición usados en la agricultura, en las redes eléctricas y en empresas de logística y del sector Retail. En 2010, algunas estimaciones


La duda es uno de los nombres de la inteligencia. - Borges Para data scientist/analistas de datos/viejos mineros/lobos de mar. En los comienzos de nuestra carrera de data scientists, el poder de cómputo era muy inferior al que disponemos hoy. Sin embargo, muchas empresas ya veían el enorme potencial de


Healthcare fraud is alive and well. Honesty is dead and gone. There, I’ve said it. What else are we to take from surveys that find that 27% of people would sell their work passwords...44% of them for less than $1,000?* What does it mean that 37% of survey respondents think


Disclaimer: this article does not cover or promote any political views. It’s all about data and REST APIs. I am relieved, thankful, elated, glad, thrilled, joyful (I could go on with more synonyms from my thesaurus.com search for 'happy') November 6, 2018 has come and gone. Election day is over.
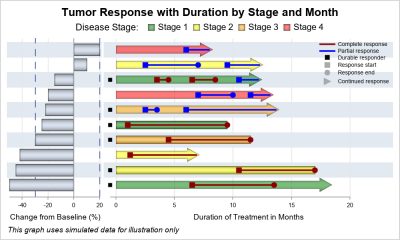

A few days back I published an article on including more subject data in a Waterfall graph. This was motivated by the desire from many users to view more data in the same graph, thus avoiding the need to refer to different graphs for the relevant information. In this case,