All Posts


Speak to almost anyone about artificial intelligence, and you’ll likely be met with either a furrowed brow of concerned cynicism or a wide-eyed smile of enthusiasm. AI seems to have this kind of highly polarising effect, certainly on citizens and many organisations who are still, understandably, evaluating how AI will


To those of you who have not read my previous post, Dividing by zero with SAS, it's not too late to go back and make it up. You missed a lot of fun, deep thought and opportunity to solve an unusual SAS coding challenge. For those who have already read
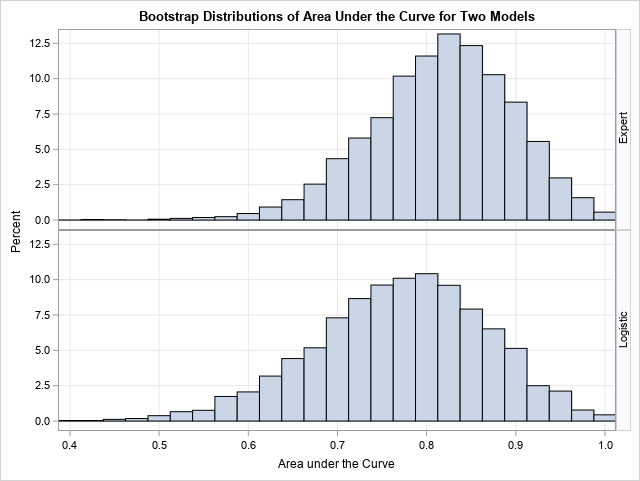

At SAS Global Forum 2019, Daymond Ling presented an interesting discussion of binary classifiers in the financial industry. The discussion is motivated by a practical question: If you deploy a predictive model, how can you assess whether the model is no longer working well and needs to be replaced? Daymond


En un mundo en el que los datos crecen exponencialmente en cantidad –y en variedad y fuentes–, organizarlos y analizarlos para convertirlos en información relevante es el gran desafío para todo tipo de organizaciones, desde gobiernos y multinacionales hasta microempresas El software logró avances gigantescos en este campo y la

El poder de los valores influye en todo lo que hacemos: desde nuestros productos, servicios y soluciones, hasta el trato que damos a nuestros grupos de interés. Toda una empresa exitosa cuenta con sólidos principios que dan forma al tipo de relación profesional que sostenemos con nuestros proveedores, socios, clientes


Leaving home and moving onto a college campus is a point of significant transition for many young adults. Every non-commuting campus I am familiar with requires freshmen students to live on campus and there is good reason for this: students who live on campus have shown to earn a higher


David Loshin reminds us that data protection compliance applies to different individuals in different contexts – and not just GDPR and CCPA.


To say Michio Kaku is smart is an understatement. For a science fair in high school, he built a particle accelerator made of 400 pounds of scrap metal. Have you ever watched the TV show, The Big Bang Theory? Sheldon and Leonard support string theory research on the show. Kaku


From the boardroom to your living room, artificial intelligence (AI) is nearly everywhere today. Tipped as the most disruptive technology of all time, it has already transformed industries across the globe. And companies are racing to understand how to integrate it into their own business processes. AI is not a


“In God we trust, all others must bring data” - Dr. W. Edwards Deming En el mundo de los sommelier se denomina cata a la acción encaminada a examinar, valorar, comparar o identificar vino (te o café, etc.) mediante el empleo de un análisis realizado con nuestros sentidos: es lo


App security is at the top of mind for just about everybody – users, IT folks, business executives. Rightfully so. Mobile apps and the devices on which they reside tend to travel around, without any physical boundaries that encompass the traditional desktop computers. In chatting with folks who are evaluating


Riddled with stress, awkwardness and formalities - it’s no secret that the job search process probably isn’t topping anyone’s list of how they’d like to spend their time. According to Inc.com, 73% of job seekers say that looking for a new job is one of the most stressful things in
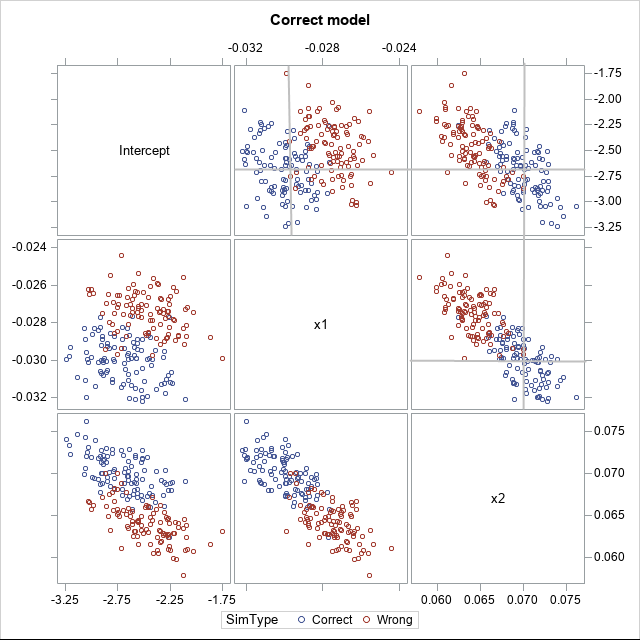
Here's a simulation tip: When you simulate a fixed-effect generalized linear regression model, don't add a random normal error to the linear predictor. Only the response variable should be random. This tip applies to models that apply a link function to a linear predictor, including logistic regression, Poisson regression, and


What if, apart from the new organisation of production assets, the fourth industrial revolution also implies a significant evolution in the knowledge management intrinsic to each domain? What if new digital technologies allow the operational actors to simply access this knowledge, mostly derived from empirical methods, thanks to analytical methods and

SAS Global Forum 2019もいよいよ最終日を迎えました。一日目、二日目、三日目に引き続き、最終日の参加レポートを掲載します。 データサイエンティストに必要な倫理 本日は”The Good, The Bad, and The Creepy: Why Data Scientists Need to Understand Ethics”というセッションに参加してきました。数十年前、データの活用はあくまで統計学の中のみのものであり、扱えるデータの数もごく少数でした。しかし、計算機の発展、理論の進歩、機械学習との交わりにより、近年では膨大かつ複雑なデータも処理することができるようになりました。それに伴い、データ分析の際のごく少数のミスもしくは悪意のある行為によって多くの人々に甚大な被害をもたらしてしまう可能性があると指摘しました。データサイエンスは非常に強力ですが、それを適切に活用するためにデータサイエンティストには倫理観が必要不可欠です。特に「引き起こしうる害」を認識し、「同意」に基づいてデータを使用し、「自分が何を分析しているか」を正確に把握することが必要と指摘し、特に三点目の重要性を強調しました。 分析に用いるアルゴリズムは適切かについて、常に気を配らなくてはありません。アルゴリズムが害を引き起こす例として、あるバイアスの持ち主が書いたプログラムにはそのバイアスが含まれている事例を紹介しました。例えば、Webでの検索結果にジェンダーギャップや人種間格差が見受けられるのは、関連するバイアスも持つ人物が書いたアルゴリズム内にそのバイアスが反映されているからかもしれません。他の例として、アルゴリズムに対する根本的な理解不足が問題を引き起こしうる事例を紹介しました。例えば、二つの要素が明らかに無関係と思われる場合でも、あるアルゴリズムが相関関係を見出したという理由でその二要素に関係があると結論付けてしまうのは、そのアルゴリズムについての理解が足りていないということです。数理統計をブラックボックスとみなしてはならず、背景理論について正確に把握し、何を分析しているかを意識し続けることが必要不可欠だと語りました。 また、これらに基づき、将来データサイエンティスト間にヒエラルキーが生じる可能性を指摘しました。基礎的な数学・統計学の知識があるだけでは不十分。倫理や関連法律を理解しそれをアルゴリズムに照らし合わせ、顧客や無関係な人々に害を与えてしまう可能性がないかを吟味し、必要に応じて手法を変えられるデータサイエンティストがヒエラルキーの頂上に来るはずだと主張し、倫理の重要性を強調しました。 SAS Global Forum 2019 に参加して 今回のSAS Global Forum 2019で最も印象に残ったことは「アナリティクスの可能性」です。本日の基調講演で、理論物理学者のミチオ・カク氏は「将来、すべての業界にAIが導入される。人類にとってロケットは大きな革命だったが、今後、データを燃料、アナリティクスをエンジンとして、さらに大きな革命が起ころうとしている。」と語りました。実際、様々なセッションへの参加を通して、アナリティクスが活躍する分野が非常に多岐にわたっていること、そしてそのインパクトが非常に大きいことを改めて実感し、将来私たちの生活がどのように変わっていくのかと想像して心を躍らせました。また、学生向けセッションへの参加を通じて、「アナリティクスを用いて世界を変えたい」という志を抱く同年代の学生が世界各地で切磋琢磨していることを知りました。近い将来、彼らと力を合わせて社会に大きなインパクトをもたらす”何か”をするため、今後も日々精進します。