
You work with data. Data about your customers. It's likely that your customers' identity could be determined from the data you’ve collected. Starting in May 2018, a new data protection law will be in effect. This means you’re going to have to document which technical measures you’ve implemented to prevent your customers from being identified. That’s tricky, but isn’t everything already pseudonymized or anonymous or something? Won’t the IT department just take care of it? No. They won’t. This blog post gives you a detailed breakdown of what’s possible and where standard software can help with masking data for GDPR.
In the past, compliance has been relatively easy. The data protection officer was sure to take care of everything, documenting the steps taken together with IT and the compliance team. It felt like the powerful data protection law was there to protect people in charge - like you – from the data’s owners out there. Too abstract for you? Here’s an analogy:
Let’s say my car’s inspection is up in May. I have placed my trust in a copy of the traffic regulations that rests in my glove box. I tell the inspector, this is how I’ve always done things! And my perfectly maintained car has been running great for years. Wait a minute, the new mechanic seems to have missed something last time... and now you want my documentation?! Huh? What documentation?
Read part 2 of this series: Beam your customers into invisibility: a data protection masked ball to get you up to speed with the GDPRData protection by design and by default (Art. 25 GDPR)
But let’s go back to (your) data, which you obtained from the data warehouse (DWH), received from generous colleagues’ collections, or harvested fresh from the data lake ... you know, the stuff that self-service big data analytics is made of. Mix it all together, and the computer is able to guess the customer’s behavior. Lawyers are less inclined to wax poetic here, referring instead to “profiling” (GDPR Article 4), which can quickly extend beyond the initial purpose of the processing. The bad part? If the customer doesn’t reasonably expect this kind of processing of their information, they can submit a complaint and even demand their data be deleted at once (Article 22 and Recital 71 GDPR).
What to do? Well, get rid of personally identifiable information right from the start! So, just select fewer data points? Yes. But if you need them for your analytics, write down in advance exactly how the data will be processed ... that’ll give your data scientist a headache. Even fragments with very minimal data could still be traced back to single out the “wife of a dentist, aged 30 to 40, living in Smallsville.” So it’s better to properly “pseudonymize” or anonymize from the start.
In other words, you have to replace all dates with asterisks or a random number or encrypt them or hash them - then, in the best-case scenario, the record is anonymous. But this procedure, unfortunately, also makes it useless for analysis in most cases. Or even worse, completely wrong with respect to segmentation, model development, or scoring. More about that later. Here’s an example of “common” customer data:
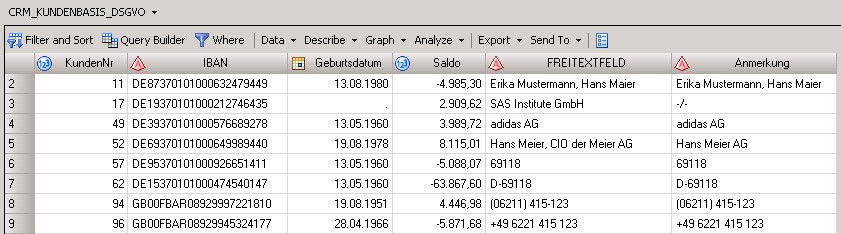
Let’s say we have a file that contains a great deal of personally identifiable information. It could even be lurking in comment fields or notes - without ever being listed in a data dictionary or the records of processing activities. But it’s hiding in there, in unassuming properties, selected out of curiosity or by mistake, and thus stored. And simply storing it brings the GDPR into play. Oops!
Are you ready for the GDPR? Learn how your peers are preparing in this global survey report.Totally anonymous: ensure compliance by making data useless?
So how exactly do you make data unidentifiable without completely destroying all of its value? When masking, you should deploy standard functions that use quality-controlled logic in such a way that users who processes the data are unable to view the algorithmn. In SQL, it may look something like this:
CREATE VIEW pdp_de_demo.Team_Alpha.CRM_CUSTOMERBASE_GDPR_VIEW AS SELECT SYSCAT.DM.MASK ( ‘ENCRYPT’, PUT(A.CustomerNo , 8.), ‘alg’, ‘AES’, ‘key’, ‘12345’ ) AS CustomerNr_encrypt, SYSCAT.DM.MASK ( ‘HASH’, A.IBAN , ‘alg’, ‘SHA256’, ‘key’, ‘12345’ ) AS IBAN_hash, SYSCAT.DM.MASK ( ‘TRANC’,A.”IBAN” , ‘FROM’, ‘1234567890’, ‘TO’, ‘XXXXXXXXXX’, ‘START’, 10 , ‘LENGTH’, 9 ) AS IBAN_tranc, PUT(SYSCAT.DM.MASK ( ‘RANDATE’, A.Bithdate, ‘VARY’, 5, ‘UNITS’, ‘DAY’ ), DDMMYYP10.) AS Birthdate, SYSCAT.DM.MASK ( ‘RANDOM’, A.Balance, ‘VARY’, 100 ) AS Balance, (CASE WHEN ( SYSPROC.DQ.DQUALITY.DQEXTRACT ( A.COMMENTFIELD, ‘PDP - Personal Data (Core)’, ‘Individual’,’DEDEU’ ) ne “) THEN ‘* * *’ ELSE A.COMMENTFIELD END) AS Commentfield_without_name, SYSPROC.DQ.DQUALITY.DQIDENTIFY ( A.ANNOTATION, ‘PDP - Personal Data (Core)’, ‘DEDEU’ ) AS ANNOTATION_IDENTIFY FROM pdp_de_demo.data.CRM_CUSTOMERBASE AS A |
The results look appealing.
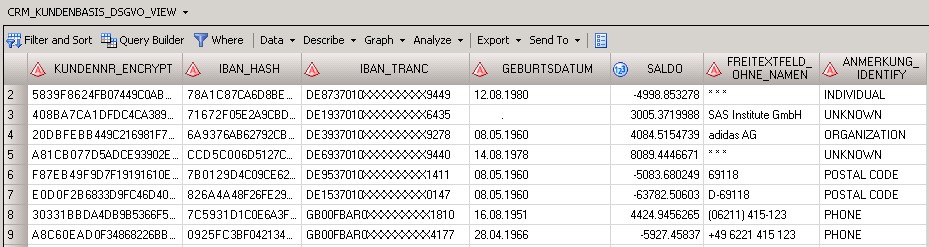
But the following methodological problem quickly arises. Who in the corporate data flow carries out this step, and where should they store the results? Depending on the type of processing, the technician or analytics expert may not be permitted to even view the data in the first place, making it impossible for them to apply masking on top! How about IT (or the application developers) doing a generic anonymization of the entire DWH in one go? Well, that’s a sure way to secure the data, and a sure way to make it useless for a lot of other things, too!
Who’s masking who?
The solution: no one touches those official tables (see note at bottom). The user just no longer (physically) accesses them directly, but rather via dynamic views, which only read specified data. These views handle masking “on-the-fly,” in real time or from the cache – without destroying the original data. In the simplest cases (as in our example code above), the content of the respective fields is modified “for all selectors.” Or depending on a control table, they’re flipped off like a switch the instant a user communicates their opt-out.
The SAS Federation Server hosts these types of views, gently inserting itself between business users, analytics experts, and internal consumers of reports. Once logged in, the server knows the user’s groups, roles, and permissions. This can be elegantly leveraged in the design of the views. The very same view can allow that team with the VIP flag to also see the balance, whereas the fraud team sees everything, while the rest get harmless asterisks in place of sensitive information. All from the same physical data, controlled through a central platform.
New on the inside, proven on the outside: controlled protection for switching on and off
Access to these types of centrally administered views is accomplished via ODBC / JDBC / API. Or, for SAS users, via the trusty libname statement. There, instead of “ORACLE,” “FEDSVR” is your keyword. Everything else looks just like it always has. The tables (some of which are not actual tables) appear, the code is ready to run. Such libref can, of course, also be pre-assigned in the metadata context.
LIBNAME mydwh FEDSVR DSN=dwh1 SERVER=”demo.sas.com” PORT=24141 SCHEMA=Team_Alpha;
A double benefit: the IT team can take its time rebuilding the physical layer (DBMS portings, modifications to the DDL, switching to a different DB, etc.) without the phones ringing off the hook with important departments calling to complain. Plus, every access can be logged. The SAS Federation Server can optionally record queries as well, regardless of whatever sneaky macro data step was used - everything is processed and logged. And users cannot get around it by deleting their SAS logs.
This activity should not be misconstrued as surveillance. The GDPR is what demands proof of who, how, where, and when ... and for data breaches, within 72 hours. Like when someone at the company burns a CD with sensitive tax information or commits other internal fraud. And as with the deletion approach, it’s already a big step in the right direction to be able to say, “yes, that’s how it would work — should we turn it on?”
Summary of the first part
The General Data Protection Regulation requires your company to implement the “appropriate technical and organisational measures” and “taking into consideration the available technology at the time of the processing and technological developments.” This article has given you some suggestions for things you can discuss with colleagues. And what’s more, the software is already out there - there’s no need to patch together a solution yourself. Instead, you can use that valuable time to generate the documentation for compliance instead.
P.S. There’s no time to lose to comply with the GDPR. Learn how to get ready in this global survey report.
Attachment: Legal texts
Profiling GDPR Art. 4, Par. 4:
‘profiling’ means any form of automated processing of personal data consisting of the use of personal data to evaluate certain personal aspects relating to a natural person, in particular to analyze or predict aspects concerning that natural person’s performance at work, economic situation, health, personal preferences, interests, reliability, behavior, location or movements;
The GDPR is more specific with anonymous pseudonymization (Recital 26 and 29):
To ascertain whether means are reasonably likely to be used to identify the natural person, account should be taken of all objective factors, such as the costs of and the amount of time required for identification, taking into consideration the available technology at the time of the processing and technological developments. The principles of data protection should therefore not apply to anonymous information, namely (...) to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable.
In order to create incentives to apply pseudonymization when processing personal data, measures of pseudonymization should, whilst allowing general analysis, be possible within the same controller when that controller has taken technical and organisational measures necessary to ensure, for the processing concerned, that this Regulation is implemented, and that additional information for attributing the personal data to a specific data subject is kept separately. The controller processing the personal data should indicate the authorised persons within the same controller.
A final note: To ensure the separate “right to be forgotten” in the data warehouse (and countless source systems) as per Art. 17 GDPR, special measures must be taken. But this is not what we’re talking about above — deleted records are “gone,” and can no longer be processed or pseudonymized by means of profiling. Note: In the event that they are not intended (or permitted) to disappear from the relevant database immediately, approaches such as the one described could offer a temporary solution.
Disclaimer: The author of this blog is not an attorney. None of the statements in this article can be construed as legal advice nor can they serve as a substitute for professional legal consultation. All code samples are for illustrative purposes only.
