앞선 두번의 연재를 통해 자금세탁 방지 기술이 향후 어떤 방식으로 발전되어갈 것인지, 금융기관이 현재 운영중인 자금세탁 환경을 앞으로 어떻게 변화시켜 나가야 하는지를 살펴보았습니다.
이를 위해 SAS는 ‘AML Compliance Analytics Maturity Model’을 제시했고, Maturity Model의 단계를 소개함으로써 현재 각 금융기관이 AML을 위해 내부적으로 어느 정도 데이터 분석을 적용하고 있는지에 대한 자체 평가를 할 수 있도록 하였습니다.
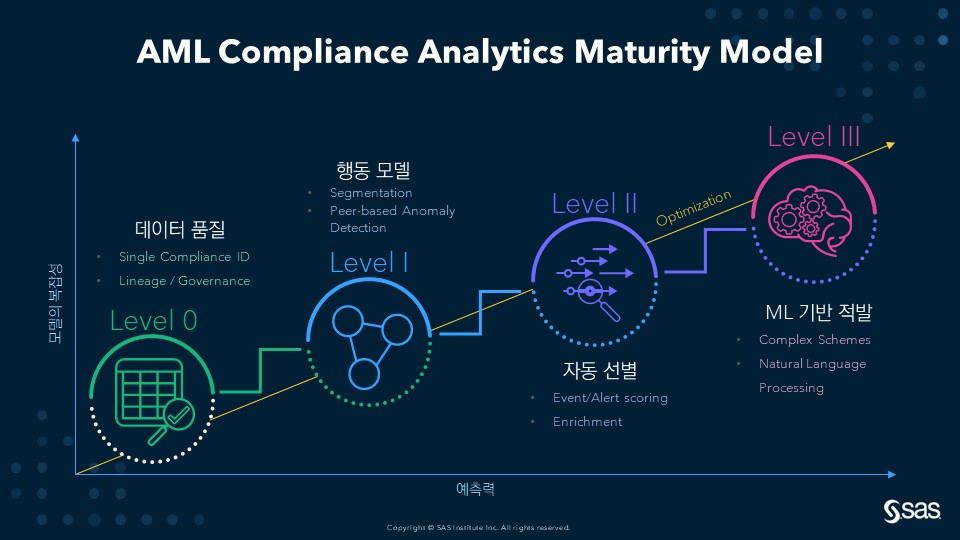
[그림 1] ALM Compliance Analytics Maturity Model
AML 컴플라이언스를 분석 기반으로 운영하기 위해서 반드시 필요한 데이터 품질은 그 근간으로서 Level 0으로 제시하였습니다.
AML 분석 성숙도 레벨의 1 단계인 Level 1은 행동 모델(Behavioral Modeling)로서, 고객과 거래의 자금세탁 위험을 최소화하기 위해 고객의 자금세탁 리스크를 판단할 수 있는 ‘고객 세분화(Segmentation)’가 중요하다는 것과, 동질 집단 기반 이상 징후 포착(Peer-Based Anomaly Detection)을 통해 ‘경보의 오탐(False Positive)’을 줄여야 한다는 것을 언급했습니다.
성숙도 레벨의 다음 단계인 Level 2는 자동 선별(Auto Triage)로서, 자동 선별을 위해서는 경보의 중요도를 판단할 수 있는 스코어링(Event/Alert Scoring) 및 데이터 보강(Enrichment)이 이루어져야 한다고 설명했습니다. 이를 통해 최종적으로는 Level 3를 통해서 ML 기반 적발(ML-Based Detection)을 달성할 수 있습니다.
ML 기반의 시나리오를 사용함으로써 임계값을 사용하지 않고도 자금세탁 유형을 더 정확하게 감지할 수 있게 됨에 따라 1종 오류(Type 1 Error)와 2종 오류(Type 2 Error)를 현저하게 줄일 수 있습니다. 또한, 수많은 Feature를 활용하여 금융 범죄를 탐지할 수 있어, 여러 규칙을 하나의 모델로 대체함으로써 복잡한 자금세탁 유형(Complex Schemes)을 손쉽게 찾아내게 됩니다. 아울러, 고도화된 자연어 처리(Natural Language Processing)를 통해 STR 작성 자동화 등을 달성할 수 있습니다. 특히, 최근 ChatGPT/LLAMA & Alpaca 모델 등을 통해 급격하게 발전되고 있는 Generative AI를 통해 그 가능성과 현실성이 급속도로 증가하고 있어, 곧 해당되는 문제의 해법이 업계에 출현할 것으로 기대하고 있습니다.
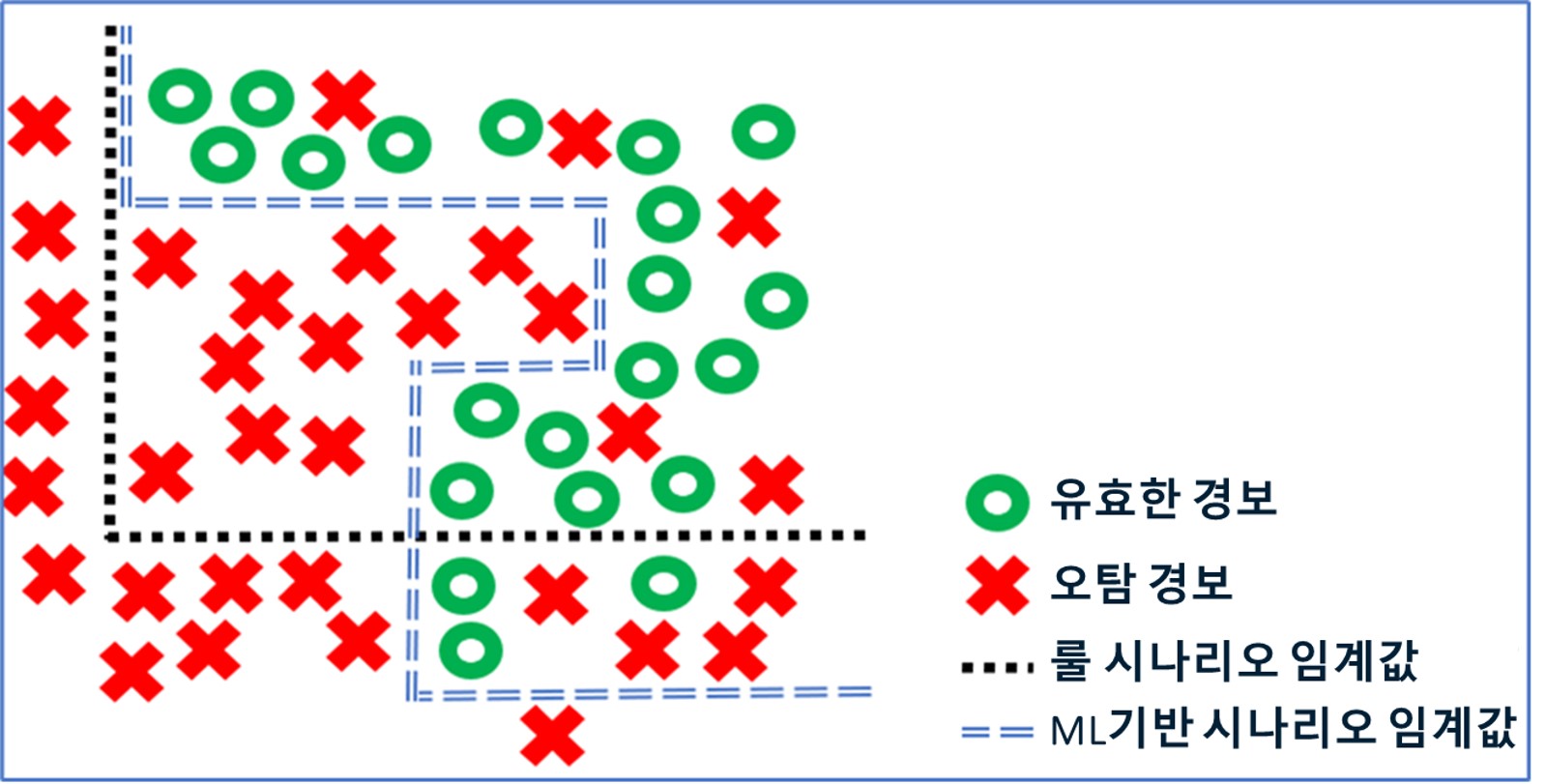
[그림 2] 룰/ML 기반 시나리오 임계값 예시
자금 세탁 방지에 대한 3번째 글인 금번 시리즈에서는 고도화된 자금세탁 방지 운영 환경을 위한 분석 알고리즘이 내장된 SAS AML 최신 버전의 행동 모델과 자동 선별 기능을 살펴보고, 향후 금융 기관이 적용할 수 있는 방법을 설명하고자 합니다.
Level 1 - 행동 모델 기능 제공
SAS AML의 최신 버전인 Anti-Money Laundering 8.3에서는 세분화(Segmentation)를 지원합니다. 세분화를 통해 유사한 특성을 가진 여러 하위 그룹으로 고객을 분류하여 단일 시나리오의 임계값을 각 세그먼트 별로 적용할 수 있게 되며, 동질 집단 내의 이상치를 감지(Peer-based Anomaly Detection)할 수 있는 시나리오 세분화를 제공합니다.
이를 위해, 사전 사용자 정의 세분화를 바탕으로 Machine Learning 기반의 클러스터링 알고리즘을 적용하여 고객을 세분화합니다. 이런, 세분화 작업은 주기적으로 세그먼트를 재할당하는 작업을 통해 고객(Party)의 최신 상태를 반영하여 고객을 위험 기반으로 모니터링하고 추적할 수 있도록 지원합니다.
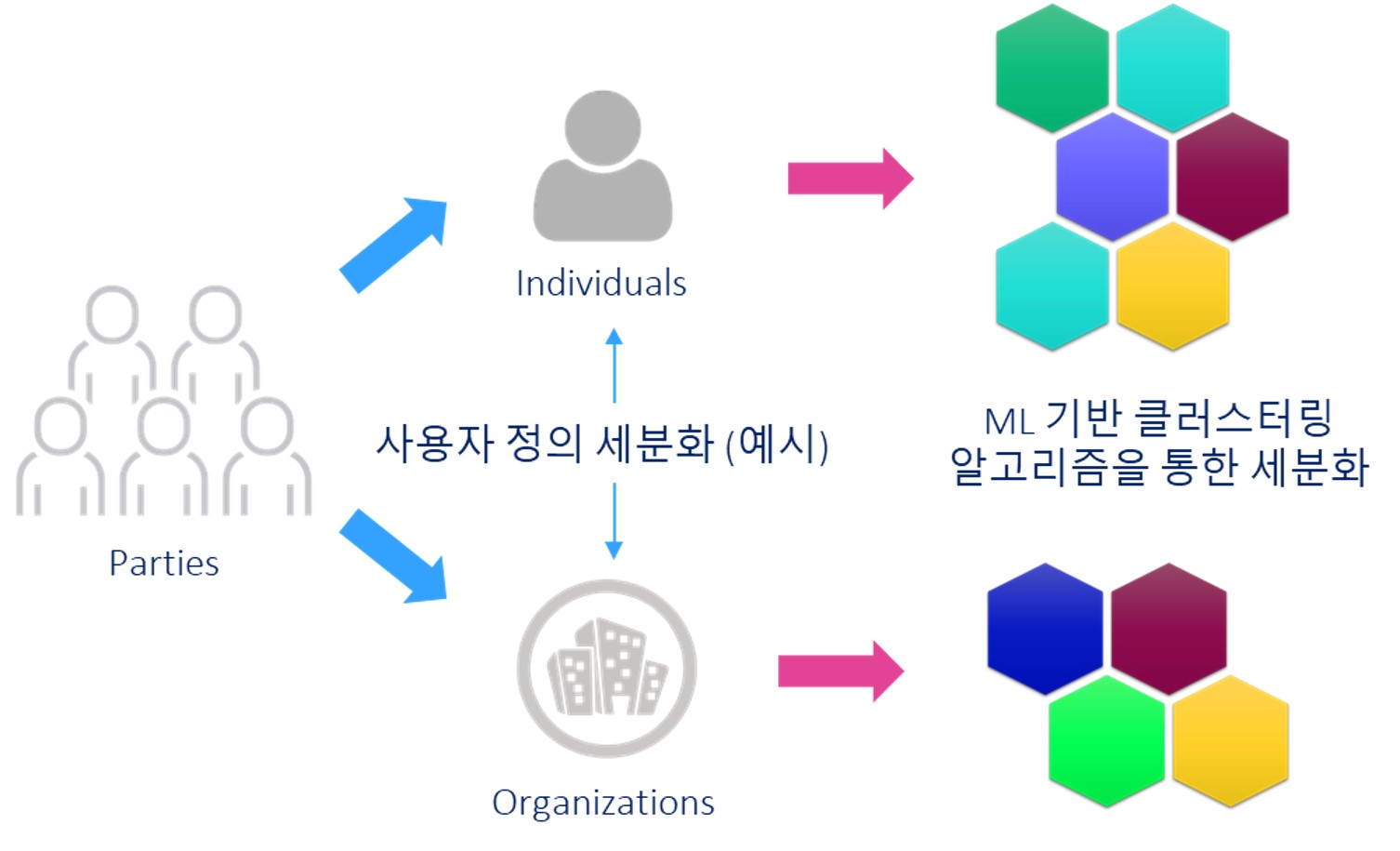
[그림 3] 행동 모델 적용 예시
위 그림 [행동 모델 적용 예시]에서의 Individuals/Organizations은 사전 사용자 정의 세분화로서 고객 세분화를 위한 최초의 수동 세그먼트이고, 이후의 세그먼트는 클러스터링 알고리즘을 적용합니다.
클러스터링 알고리즘은 AML 원천/결과 데이터로부터 고객(파티)의 원천 속성, 거래를 통한 행동 속성, 과거 경보 정보를 추출하고, 행동/특성을 보강할 수 있는 Feature를 레코드에 보강하여, 이를 기반으로 K-Mean 클러스터링 알고리즘 기반의 세그먼트를 생성합니다. 생성된 세그먼트는 AML 시스템을 운영하기 위한 마스터 데이터와 AML 솔루션에 반영됩니다.
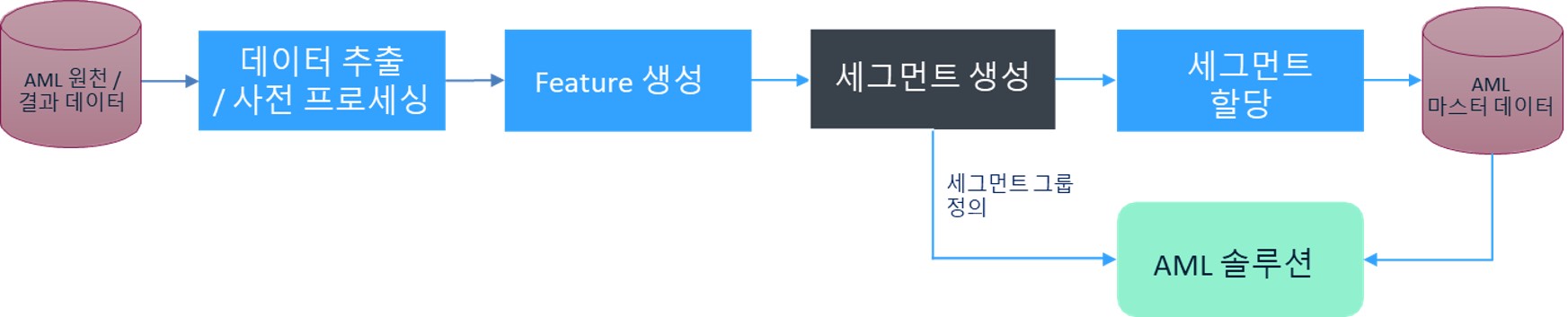
[그림 4] AML 행동 모델 적용 프로세스
AML 시스템 운영 마스터 데이터에 저장된 세그먼트는 운영을 위해 활용될 수 있도록 관리 모듈에 포함되어 시나리오 세분화에 적용될 수 있습니다.
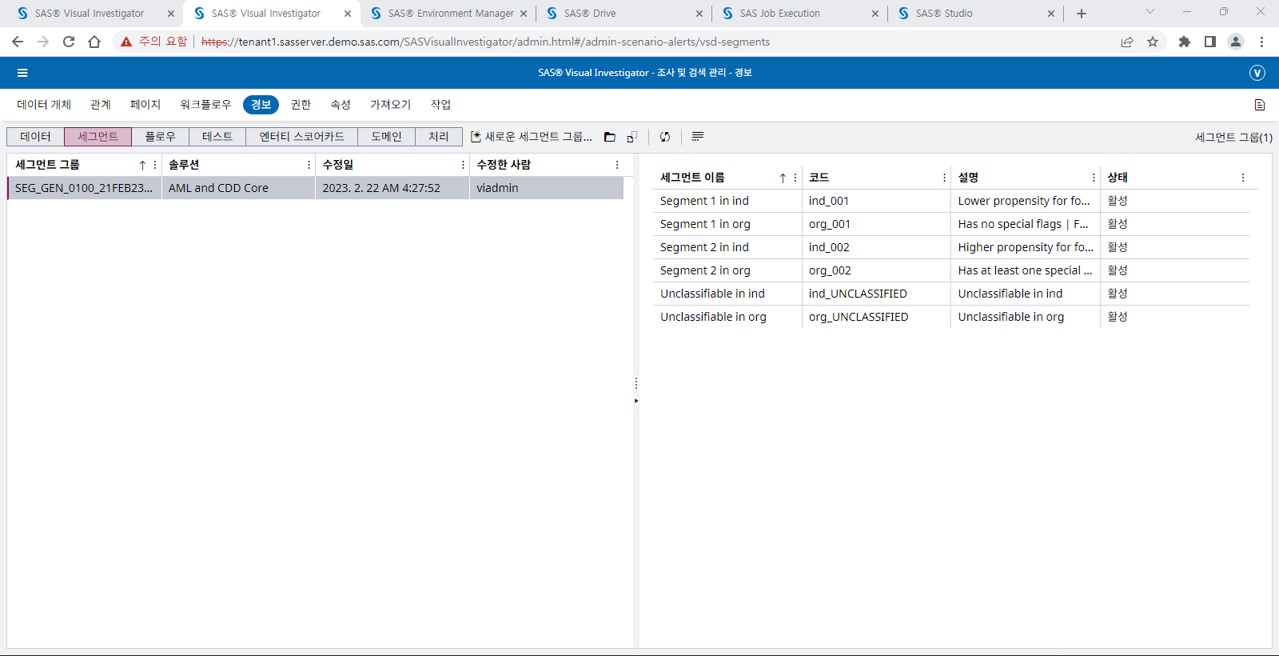
[그림 5] SAS AML 솔루션 내의 세그먼트 결과
행동/특성을 반영한 주제별 세그먼트 그룹에 따라 주기적인 일정으로 세그먼트를 생성하게 됩니다. 사용자가 지정한 행동/특성을 기준으로 SAS AML 8.3에 내장된 알고리즘을 통해 세그먼트가 생성됩니다.
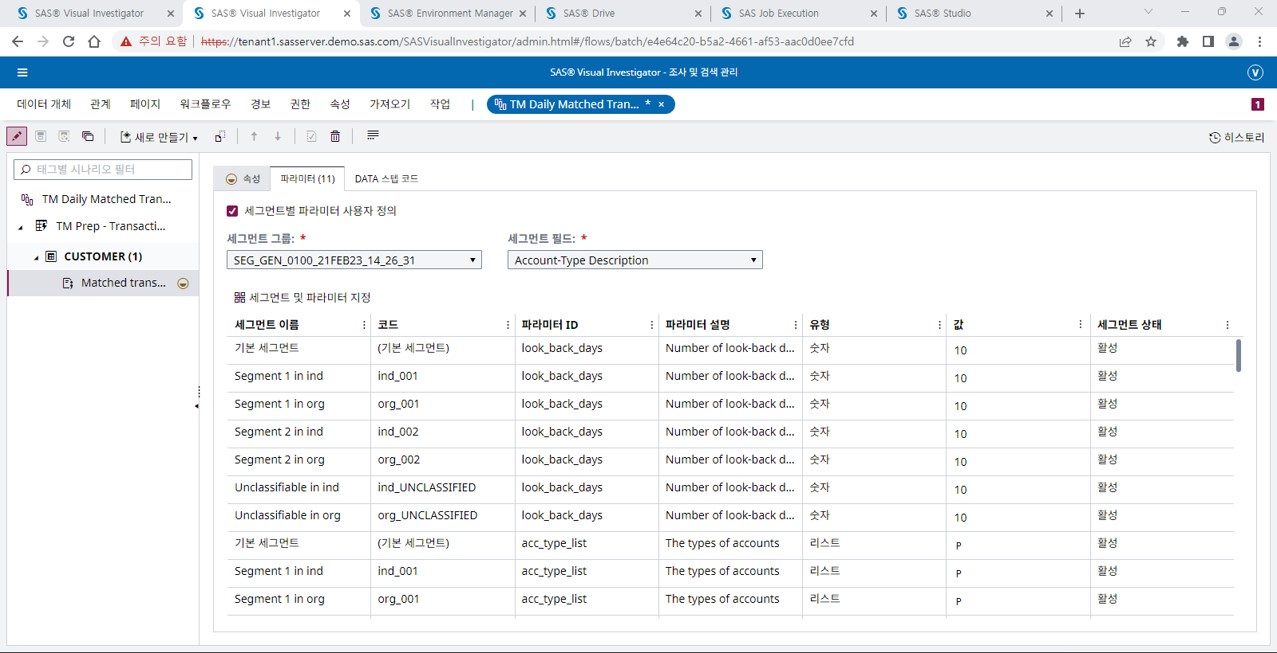
[그림 6] SAS AML 세그먼트 별 시나리오 임계값 설정 예시
생성된 고객 세그먼트는 반영해야 할 필요성이 있는 시나리오에 세그먼트를 적용하여 세그먼트별로 다른 임계값을 적용할 수 있도록 설정합니다.
설정된 세그먼트별 임계값에 의해 경보가 생성되면, 생성된 경보의 상세 정보 내의 고객 정보에 고객이 포함된 세그먼트와 그 세그먼트 히스토리가 제공됩니다.
Level 2 – 자동 선별 기능 제공
SAS AML의 최신 버전인 Anti-Money Laundering 8.3에서는 경보 스코어링(Alert Scoring)을 통해 활성 경보에 대한 우선순위를 부여할 수 있는 스코어를 제공합니다. 이를 위해 시스템 내에 내장되어 있는 ‘즉시 사용 가능한 모델’을 사용하여 스코어링하는 방식과 SAS의 전문 AI 모델링 도구를 활용하여 개발한 ‘사용자 지정 모델’을 사용하는 스코어링 방식을 제공합니다.
시스템에 내장된 모델은 과거 성향과 현재 활성 경보 모집단을 모두 사용하여 경보 데이터에 대한 Enrichment를 수행한 후, 이를 기반으로 Autoencoder를 활용한 Semi-Supervised 모델 생성 매커니즘을 통해 우선 순위를 스코어링합니다.
SAS AML 솔루션은 우선순위 스코어를 활용하여 고위험, 중위험, 저위험에 맞는 자동화된 선별 작업을 수행하고, 해당 위험에 맞는 Workflow를 통해 자금세탁 위험을 기반으로 금융 기관의 리소스를 배분하고 활용할 수 있게 합니다.
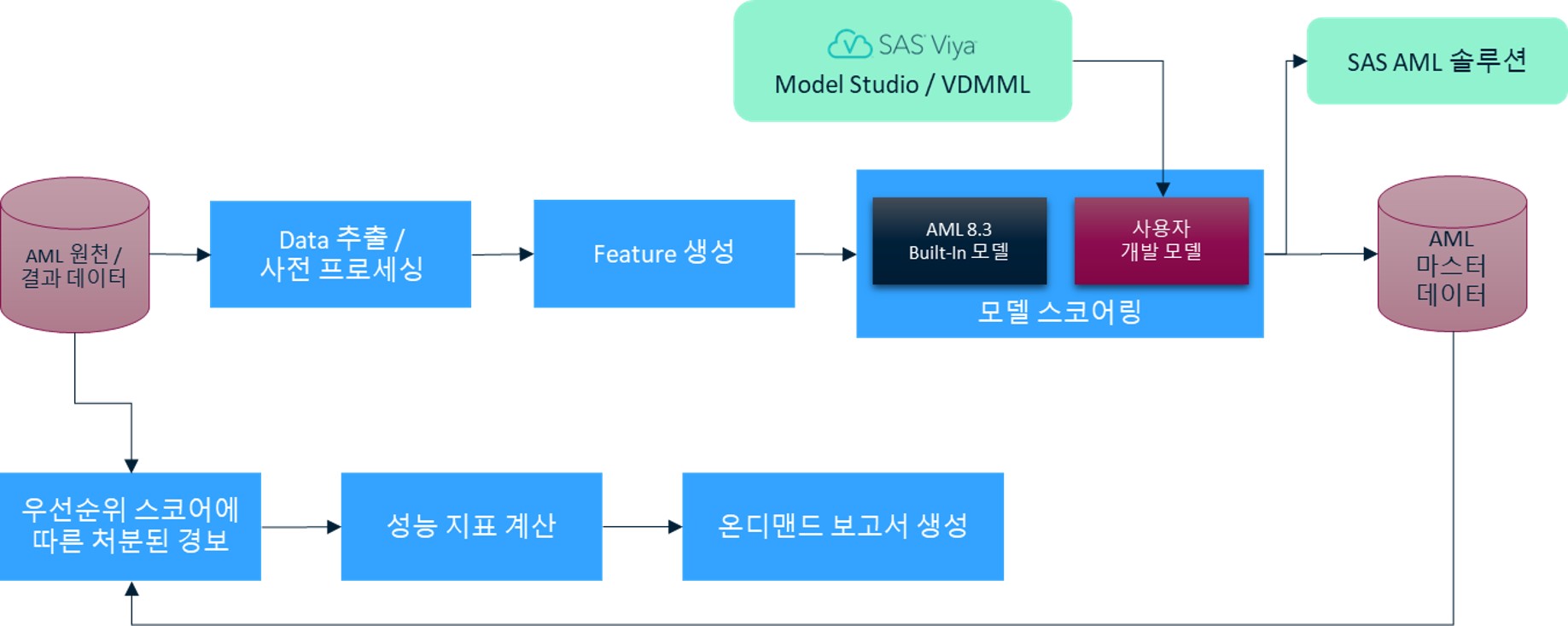
[그림 7] AML 자동 선별 모델 적용 프로세스
데이터 추출 시 활성 경보와 억제 경보, 종료 경보를 모두 추출하고, Feature 생성 단계에서 자금세탁 적발 시나리오에 반영되지는 않았지만 경보의 우선순위에 적용할 수 있는 다양한 Feature를 추가하여 경보 데이터를 강화해야 합니다. 이 기능이 내장된 SAS AML은 Case Deposits, Large Cash Transactions, Structuring Index for Cash Deposit 등 12 개의 Default Feature를 제공합니다.
이렇게 만들어진 Feature를 활용하여 결측값을 보정하고, 데이터를 스케일링한 후, 오토인코더 비지도 학습 신경망 아키텍처를 활용하여 고차원의 Feature를 저차원 Space로 인코딩합니다. 이를 통해 비선형적이며 압축된 저차원 데이터에서 입력 데이터를 재 생성하여 유효성을 검증합니다. 또한 K-Means 클러스터링 알고리즘을 기반으로 우선순위 스코어링을 수행합니다.
이렇게 산출된 스코어는 SAS AML 솔루션 내에 별도의 컬럼으로 표현되고, 산출된 스코어를 기반으로 개별 워크플로우를 활용할 수 있도록 자동 선별용 Queue에 할당합니다.
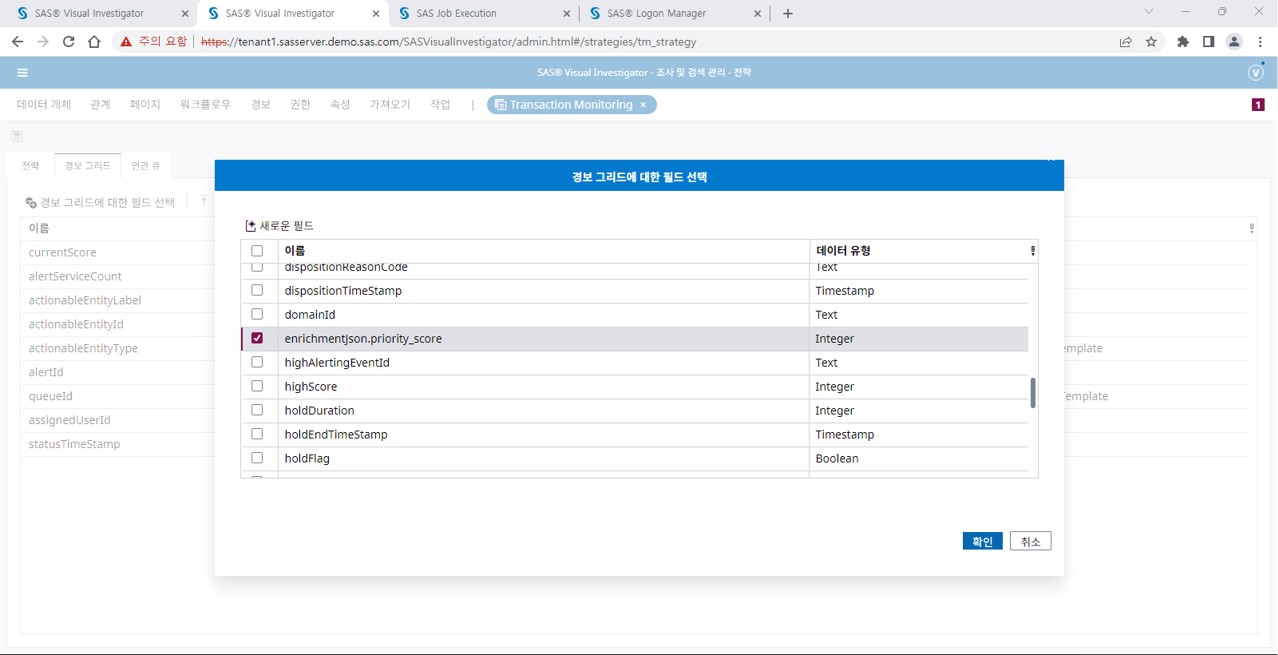
[그림 8] 표현 데이터에 우선순위 스코어 포함
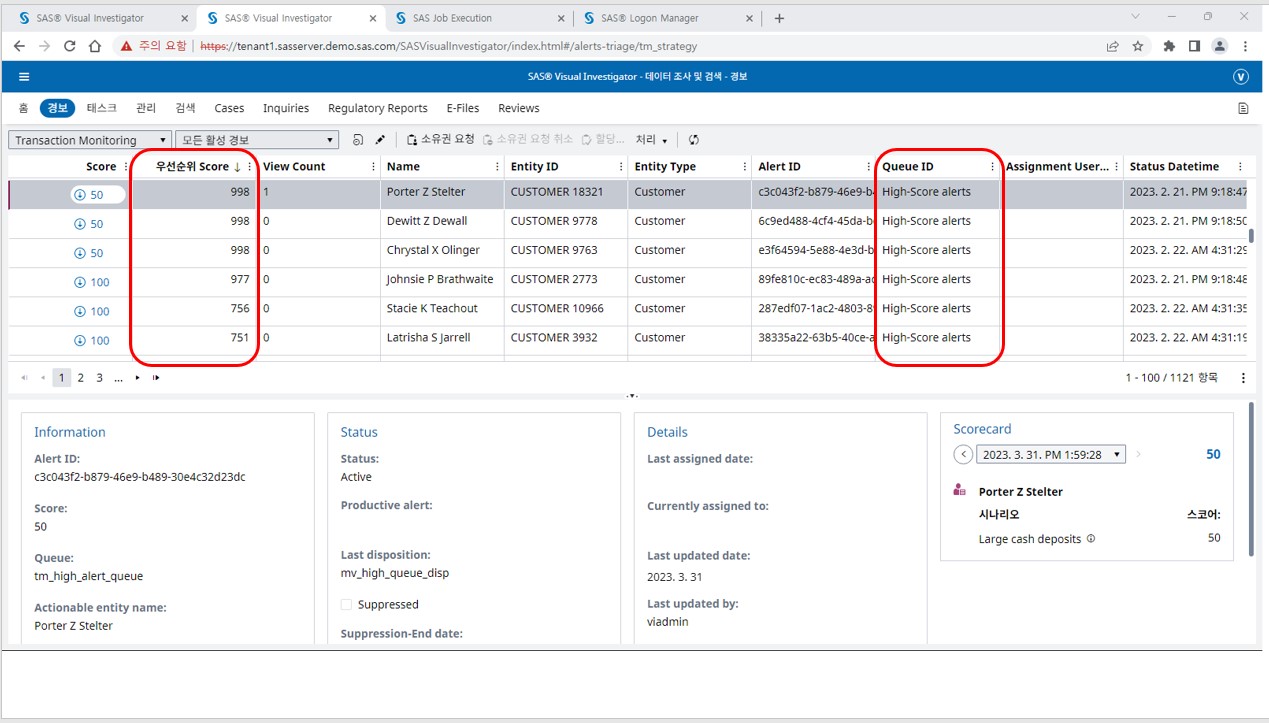
[그림 9] 우선순위 스코어 및 스코어 기반의 자동 선별 Queue 워크플로우 할당
지금까지 3회에 걸쳐 소개한 SAS의 AML Compliance Analytics Maturity Model은 자금세탁 방지 업무를 효율적이고 과학적으로 접근함으로써 위험 기반 접근법(Risk-Based Approach)을 수행할 수 있는 분석 경로를 제공합니다.
데이터로만 확인될 수 있는 자금세탁 위험도를 쉽고 빠르게 식별하고, 위험도에 따른 금융기관의 내부 통제 및 완화 조치를 수행할 수 있도록 지원하는 것이 AML 컴플라이언스를 위한 분석 성숙도 모델의 궁극적인 목적입니다.
금융기관이 AML을 운영하는 실제 업무에서 SAS의 AML Compliance Analytics Maturity Model이 제시하는 Path Away를 참고한다면 데이터 기반으로 보다 과학적이고 즉각적인 의사 결정을 내릴 수 있을 것입니다.
특히, 최근의 AI 열풍은 금융 기관의 AML Analytics에 좀 더 강한 동인을 불어넣을 것이라고 확신합니다.
관련 블로그 :
[AML 시리즈 #2] 거래 모니터링을 보완하는 AI/ML
[AML 시리즈 #1] 자금세탁 방지 고도화를 위한 AI/ML 도입 목적과 범위, AML Compliance Analytics Maturity Model
