SAS 바이야(Viya)의 자동 머신 러닝으로 현업 담당자도 손쉽게 데이터 분석 가능
인공지능(AI)과 머신 러닝(ML)이 등장하기 시작한 약 10 여 년 전부터 Data Science 영역이 많은 주목을 받게 되었고, 이에 따라 급여가 높고 장래성이 있는 매력적인 직업으로서 Data Scientist의 인기가 한층 높아지고 있습니다. Data Scientist의 역할을 제대로 수행하기 위해서는 컴퓨터 프로그램 및 IT에 대한 지식과 기술, 알고리즘 및 수학과 관련된 지식, 그리고 업무 지식과 능력 등 많은 영역의 전문성이 필요한 반면, 이러한 역량을 갖춘 인력은 시장에 많지 않은 상황입니다. 일부 기업에서는 해당 인력을 양성하기 위해 적지 않은 시간과 노력을 들였으나, 만족할 만한 결과를 얻지 못하고 있고, 이로 인해 인공지능과 머신 러닝의 도입 및 적용에 어려움을 겪고 있습니다.
분석의 대중화와 Citizen Data Scientist
이러한 문제의 해결 방안 중 하나로 최근 5~6년 전부터 분석의 민주화 (Analytic Democratization) 또는 분석의 대중화에 대한 방안이 모색되기 시작되었고, 그 결과 중 하나로 자동 머신 러닝(이하 Auto ML)이라는 솔루션이 출현했습니다. 이러한 솔루션을 기반으로 새로운 분석가 영역, 즉 Citizen Data Scientist(이하 CDS)가 등장하게 되었습니다.
지금부터 Data Scientist, Auto ML과 CDS에 대해 알아보고 마지막으로 SAS 바이야(Viya)에서 이러한 기능들이 어떻게 제공되는지 알아보도록 하겠습니다.
앞서 언급했듯이 Data Scientist는 알고리즘 구현 및 데이터 처리를 위한 Python, R 및 Java 등의 프로그램 언어와, 데이터 구조 등을 위한 컴퓨터 공학, 마케팅 및 고객 이탈 방지 등에 대한 업무 전문 지식, 그리고 AI/ML의 알고리즘을 이해하고 선택하고 결과를 해석하기 위한 수학 및 통계 지식이 필요합니다. (그림 1 참조)
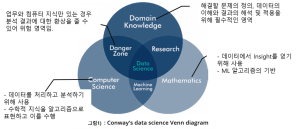
Data Scientist를 양성하기 위해 최근 일부 기업에서는 외부에서 능력 있는 전문가를 고용하거나, 업무 지식이 있는 전문 현업에게 프로그램을 교육하여 필요 인력을 양성하고 내부 역량을 강화하는 시도를 해왔고, 지금도 이러한 노력은 계속되고 있습니다. 그러나 이러한 방법은 기업에서 원하는 결과나 효과를 제공하기에는 한계가 있습니다.
프로그램 언어 자체의 습득은 오래 걸리지 않습니다. 하지만 업무 전문가들이 객체지향 개념 및 설계, 프로그램 패턴 및 데이터 구조 등을 이해하고 적용하는 데에는 적지 않은 시간이 필요하고, 작업의 효율성도 떨어질 수 있습니다. 또한 추가로 필요한 영역인 수학 및 통계에 대한 지식은 프로그램 영역보다 더욱 어렵고 오랜 시간이 소요되기도 합니다. 그 반면, 수학 및 통계 지식이 있는 전문가는 프로그램 영역의 습득은 용이 할 수 있으나 업무 지식의 습득에는 많은 시간과 노력이 요구될 것입니다. 이러한 요인들이 기업이 요구하는 Data Scientist를 시장에 충분히 공급하지 못하고, 기업에서 Data Scientist를 양성하는 데에 많은 시간이 소요되는 원인이라 할 수 있겠습니다.
그럼 이를 해결하기 위한 방안은 무엇이 있을까요? 결국 기업은 분석 그 자체로부터 자유로워져야 합니다. 이를 분석의 민주화 또는 대중화로 표현하기도 합니다. 분석은 특정 전문가의 영역으로 분류되어서는 안 됩니다. 물론 Computer Vision 등의 일부 영역에서는 분석 전문가 및 Data Scientist가 필요하지만, 기본적으로 기업 내의 많은 인력이 프로그램이나 수학과 통계에 대한 전문적 지식 없이 분석을 할 수 있어야 하고 그 결과를 쉽게 이해할 수 있어야 합니다.
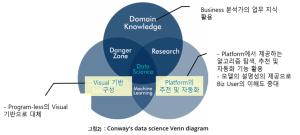
이런 문제 해결의 과정 중 프로그램에 대한 필요성을 줄이기 위해, 분석 플랫폼 및 도구 공급 업체들이 시각화 기반의 Self Service XX (XX = BI, Data Preparation, Visualization 등)를 지향하여, Drag & Drop, 파라메터 설정 등의 기능을 이용한 데이터 탐색 및 분석을 가능하게 하고 있습니다. 또한, AI/ML 관점에서 자동 머신 러닝(Auto ML)을 이용하여 수학 및 통계의 전문 지식이 없더라도 효율적인 모델을 쉽게 생성할 수 있도록 도모하고 있습니다. 최근, 이러한 영역의 발전으로 5 ~ 6년 전에 시작된 분석의 민주화를 지향하는 Citizen Data Scientist(이하 CDS)라는 역할이 형성된 것입니다. (그림 2 참조)
분석의 대중화를 여는 핵심 기술, Auto ML
그럼 Auto ML의 필요성과 이것이 무엇인지에 대해서도 알아보겠습니다. Data Scientist 중심의 전통적인 머신 러닝 과정 중 모델 최적화 단계에서 전문가 요구, 직관 및 경험에 따른 학습, 알고리즘의 복잡성 증가에 따른 투명성 부족, 마지막으로 문제 해결 중심보다는 방법 중심의 접근 등이 난제로 떠오르게 되었지요. 이에 따라, 기업에서는 Data Scientist의 필요성과 함께 모델 개발 기간 및 비용의 증가, 그리고 모델의 투명성과 신뢰성에 대한 위험 등 여러 장애물에 부딪히게 되었습니다.
이를 해결하기 위해서는 모델 전 과정의 자동화를 이루고, 전문 지식이 없어도 모델을 생성하고 모델에 대한 해석 및 설명을 제공하여 업무 전문가가 분석의 결과를 이해하고 필요한 의사 결정 및 업무로의 적용을 할 수 있도록 해야 합니다. 또한 알고리즘 및 언어 등의 방법 중심이 아닌 문제 중심으로 접근해야 합니다. 이를 위해 필요한 기능을 제공하는 것이 광의의 Auto ML이라고 하겠습니다.
Auto ML을 통해 학습한 내용을 다시 학습하여 이를 기반으로 데이터를 이해하고 모델을 선택하는 과정 자체도 점차 진화하게 됩니다. 일부 시장에서는 자동 피처 엔지니어링 및 선택, 학습할 알고리즘의 선택 및 알고리즘과 관련된 하이퍼파라메터의 자동 조율 기능을 제공하는 것을 Auto ML이라고 정의하는 데 필자는 이를 협의의 Auto ML이라고 생각합니다.
분석 플랫폼에서 제공하는 광의 또는 협의의 Auto ML 기능을 이용하여 여러 모델을 학습하고, 최적의 모델을 자동적으로 선택하고, 이 결과에 대한 모델의 해석 정보를 이해하여, 의사결정 또는 업무에 적용하는 새로운 역할의 분석가를 CDS라고 정의할 수 있습니다. 기업 내의 업무와 데이터에 대한 이해도가 높은 업무 전문가에게 약간의 기초 통계 및 수학 지식에 대한 교육을 제공하는 과정을 통해 CDS를 양성할 수 있는데, 이를 통해 Visual을 이용한 도구의 활용과 생성된 모델에 대한 이해도를 높이고 데이터의 인사이트를 도출해 낼 수 있게 됩니다. CDS에게 있어서 업무 기능에서 생성된 데이터에 대한 구조 및 문맥적 정보에 대한 이해가 매우 중요한데, 이러한 역량을 Data Literacy라고 하며 최근 기업 내에서 많은 주목을 받고 있습니다.
SAS 바이야로 현업 담당자도 분석 데이터 해석 가능
그럼 이제, SAS 바이야(Viya)에서 CDS를 위해 어떠한 기능을 제공하는지 알아보겠습니다. SAS 바이야에서 제공하는 Auto ML은 광의의 Auto ML 기능을 의미합니다. 즉 분석의 전 과정인 전 처리, 시각화 탐색, 피처 엔지니어링 및 선택, 자동 튜닝, 모델의 해석력 제공, 모델 생애 주기의 전과정에 Auto ML을 적용하여 업무 분석가가 쉽게 AI/ML을 활용할 수 있게 해 줍니다. (그림 3 참조)
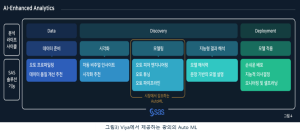
데이터의 준비 단계에서 자동 데이터 프로파일링을 통해 데이터에 대한 기초통계와 분포에 기반한 데이터의 품질 및 변수로서의 활용 가능성에 대한 이해도를 얻을 수 있으며, 내장된 ML 기능을 이용하여 데이터 변수 간의 시각화 추천을 통해 문맥적인 이해도를 증가시킬 수 있습니다. 또한 데이터의 변환 추천, 자동 피처 엔지니어링, 자동 피처 선택과 자동 조율 등의 기능을 제공하여 전문 지식이 없어도 모델 학습을 위한 작업을 할 수 있게 됩니다. 이 점이 일반 시장에서 언급되는 협의의 Auto ML과의 큰 차이점이라고 볼 수 있습니다.
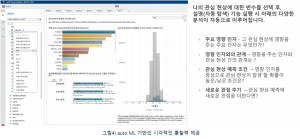
의료 정보를 예로 들어 보면, 사전 모델 생성 전에 One-Click으로 관심사항(예. 당뇨병)의 주요 요인을 내장된 최신의 ML 알고리즘에 의해 시각적인 분석 및 설명으로 제공하여 관련 전문 지식이 없더라도 모델 생성 전에 데이터와 분석의 결과 예측에 대한 사전 통찰력을 얻을 수 있습니다. (그림 4 참조)
SAS 바이야의 모델 개발 환경은 Data Scientist를 위한 프로그램 환경과 CDS(SAS에서는 ‘일반 분석가’와 ‘업무 전문가’로 구분)를 위한 시각적 UI 기반의 Pipeline 생성 및 Auto ML 기능을 이용한 자동 Pipeline 생성 기능을 제공합니다. 프로그램 환경은 SAS Code를 이용하는 방법과 Python 또는 R등을 사용하여 바이야에서 제공하는 서비스 및 기능을 이용하는 방법이 있습니다.
또한 모델 생성의 과정을 pipeline을 이용하여 시각적으로 구성할 수 있는데, pipeline은 전문가가 자주 사용하는 패턴을 Template으로 구성 및 저장하여 ‘일반 분석가’가 사용하는 방식과, 데이터만 준비되면 전 처리, 피처 엔지니어링 및 선택, 학습 모델 선택 및 학습, 그리고 챔피언 모델까지 선정하는 전과정을 내장된 Auto ML 기능을 이용하여 구성 및 실행할 수 있는 ‘업무 전문가’ 환경을 함께 제공합니다. (그림 5 참조)

전통적인 예측 모델에 사용되었던 단순 의사결정 트리 또는 회귀 함수 기반의 모델은 생성된 프로그램의 로직 또는 공식의 파라메터의 값을 보면 예측 결과(예를 들어 고객 이탈 또는 예상 매출액 등)에 대한 근거를 쉽게 찾을 수 있었고 이해가 가능했습니다. 하지만 최근의 예측모델에 사용하고 있는 Deep Learning 및 그레디안 부스팅 같은 알고리즘은 생성된 모델의 프로그램을 분석하여 예측의 근거를 찾는 것이 거의 불가능합니다. 전자를 화이트 박스 모델이라고 하고 후자를 블랙 박스 모델이라고도 합니다.
특히 의료 및 금융 등의 여러 분야에 최신 알고리즘 기반의 AI/ML 활용이 확대됨에 따라, 이 산업에서 잘못된 예측 결과가 발생할 경우 많은 금전적 손해와 생명의 위험을 초래하는 피해가 발생됩니다. 따라서, 잘못된 예측 결과에 따른 피해를 최소화하고, 업무 전문가가 의사결정 및 업무 적용 여부에 대한 판단을 안전하게 하기 위해 블랙 박스 모델에 대한 설명력, 즉 예측 근거에 대한 설명이 필요합니다.
폐암 여부의 진단 모델을 예로 들어 보겠습니다. 진단에 필요한 X-ray, MRI, 혈액 및 조직 검사 데이터로부터 모델을 생성했을 경우, 의사는 증상 및 데이터 등의 업무적인 지식을 Data Scientist 또는 CDS의 분석가에게 제공하게 됩니다. 분석가는 학습을 통해 알고리즘을 생성하고 예측하고 그 결과를 의사에게 전달합니다. 이 과정에서 분석가는 예측의 근거를 쉽게 제시할 수 없으며, 만일 진단이 잘못된 경우 환자에게 매우 위험한 결과를 초래하게 됩니다. 따라서, 이러한 근거는 모델의 설명성 기능을 통해 의사에게 제시되어 의사의 전문지식을 통해 검증되어야 합니다. SAS 바이야에서는 LIME, PD, SHAP Value 및 ICE 등의 다양한 기법에 근거한 모델의 설명성을 제공하고 있습니다. (그림 6 참조)
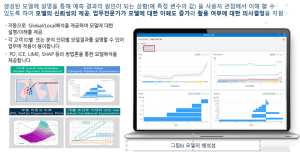
SAS 바이야(Viya)에서는 이 외에도 CDS를 위한 다양한 기능 및 서비스를 제공하지만 여기서는 가장 중요한 Programless를 위한 Visual 작업 환경과 수학 및 통계 전문 지식의 필요성을 최소화할 수 있는 Auto ML 기능에 대해서 알아 보았습니다. SAS 바이야가 제공하는 자동 머신러닝을 활용한다면 데이터 전문가가 아니더라도 쉽게 CDS의 역량을 갖출 수 있다는 것을 꼭 기억하시기 바랍니다.
SAS 바이야는 Data Scientist 전문가 없이도 기업에서 AI/ML 기술을 이용한 손쉬운 예측 모델을 적용하여 신속한 의사결정을 가능하게 하고, 이를 통해 기업의 이익을 극대화할 수 있는 효율적인 솔루션으로서 IDC, 가트너, 그리고 Forrester 등으로부터 그 성능을 인정받은 글로벌 리더 솔루션입니다. 이제부터 SAS의 바이야를 통해 분석으로부터 자유로워지는 환경에서 기업의 이익 극대화를 경험하시길 바랍니다.