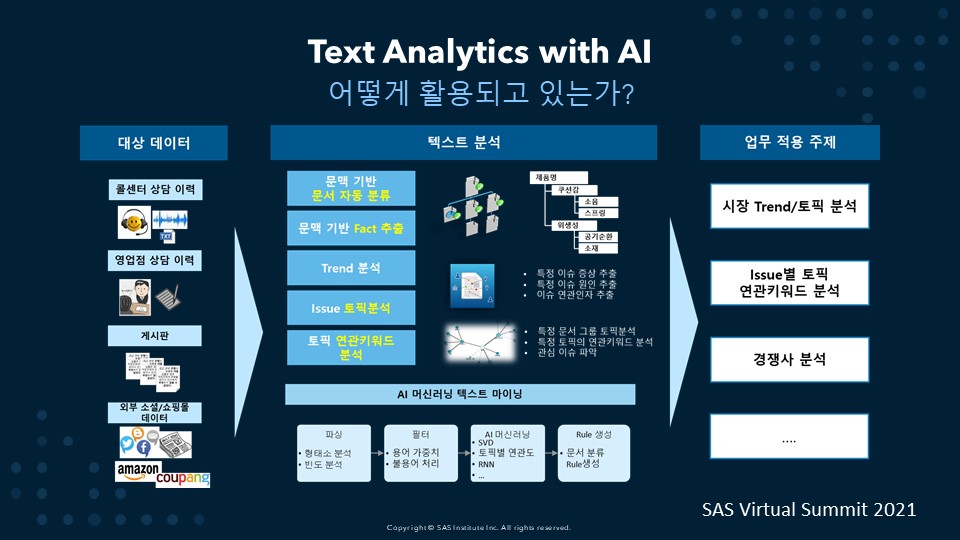
모든 비즈니스 영역으로 확대되는 텍스트 분석
그동안 소셜 미디어 분석에 국한되었던 텍스트 분석은 이제, 콜센터, 마케팅, 품질 영역으로 확장은 물론 최근 들어 전통적인 수작업 영역(발주처 요구사항 분석, AI기반 안전사고 예방 등)까지 확대하고 있습니다. 텍스트 분석을 하기 위해서는 텍스트와 함께, AI 기반의 NLP 머신러닝 엔진이 필수입니다. 이 엔진 내에서 문맥 기반의 문서 자동 분류, 문맥 기반 팩트 추출, 트렌드 분석, 이슈 토픽 분석, 토픽 연관 키워드 분석 등의 작업을 하게 됩니다. 이러한 분석 결과가 데이터 마트에 쌓이고, 이를 시장 트렌드와 토픽 분석, 이슈별 토픽 연관 키워드 분석, 경쟁사 분석 등 업무에 활용할 수 있습니다.
SAS의 텍스트 분석은 AI 기반의 머신러닝 자연어 처리 엔진과 함께, 한국어를 포함한 31개 언어 자체의 형태소 분석기를 보유하고 있습니다. 이 외에도 하이브리드 머신러닝을 기반으로 계층 분류 모형을 만들 수 있으며, 머신러닝을 기반으로 사용자 사전을 확장할 수 있습니다. 그리고 머신러닝을 기반으로 핵심 문장을 찾아줍니다.
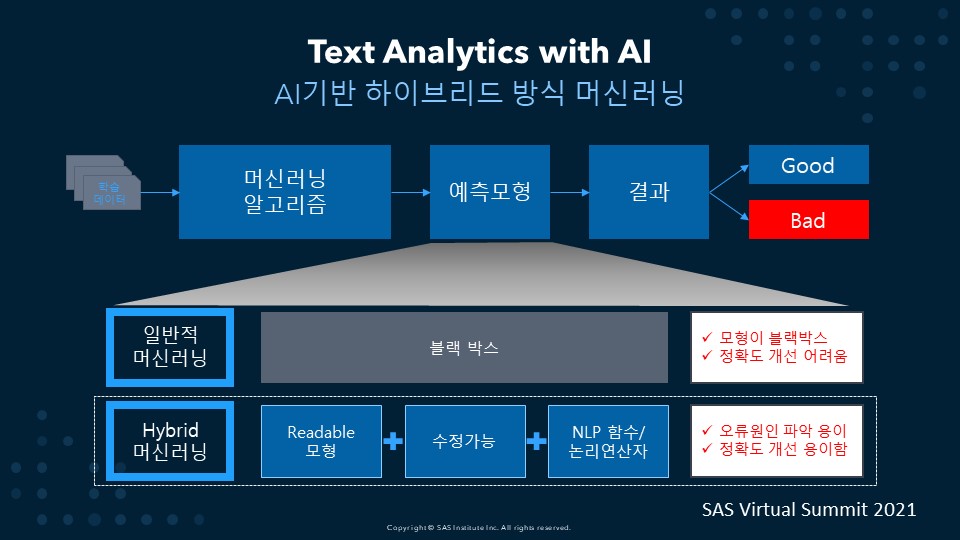
AI 기반 하이브리드 방식 머신러닝
예측 모형은 학습 데이터에 머신러닝 알고리즘을 적용하여 만듭니다. 이렇게 만든 예측 모형의 결과물이 좋지 않을 경우, 머신러닝 알고리즘에만 의존하는 제품에서는 이를 해결하기 위해 일반적으로 학습 데이터를 늘립니다. 그런데 이 데이터를 늘리는 일이 생각보다 어렵습니다.
사용자가 컨트롤할 수 없는 히든 레이어(블랙박스)도 너무 많습니다. 단순한 학습 데이터 추가나 파라미터 수정 정도만 컨트롤할 수 있기 때문에 정확도를 개선하기 어렵습니다. 이렇게 하고도 결과가 좋지 않다면 더 이상 방법이 없습니다.
이에 반해 SAS 하이브리드 머신러닝은 머신러닝을 기반으로 모형을 만들지만 해당 머신러닝은 Readable한 모형입니다. 또 NLP 함수와 논리연산자를 통해 수정할 수 있으므로 빠른 시간 안에 모형의 정확도를 높일 수 있습니다.
국내 많은 기업이 하이브리드 머신러닝을 기반으로 텍스트 분석을 진행하고 있습니다. 한 전자회사는 빅데이터 기반의 리스크 조기 경보에 텍스트 분석을 적용했습니다. 소셜 분석, 회사 게시판 VoC 데이터, 매출 실적 등 정형+비정형 분석을 통해 인사이트를 도출하고 있습니다. 건설사에서는 발주처에서 배포하는 수만 페이지에 이르는 PDF 형태의 ITB 문서를 일일이 읽고 수작업으로 입찰 문서로 만드는 작업에 텍스트 분석을 도입하여 보다 경쟁력 있게 문서를 작성합니다. 이 외에도 병원, 제철회사, 보험사, 은행, 유통 등 거의 모든 산업 분야에서 하이브리드 머신러닝 기반의 텍스트 분석을 활발히 사용하고 있습니다.
하이브리드 모형 만드는 방법
# 머신 러닝 기반으로 분류 모형 만들기
N 포털의 기사 분석을 시나리오로 간단히 소개해보겠습니다. SAS Viya 메뉴에서 ‘모델 생성’을 클릭하여 새로운 프로젝트의 이름, 유형 등을 입력 또는 선택한 다음, 데이터(엑셀에 저장한 N포털에서 추출한 크롤링 데이터)를 가져오면, N포털에 기사를 올리는 분류 모형을 만드는 프로젝트 환경이 만들어집니다. 기사의 바디가 되는 콘텐츠의 역할을 텍스트로 선택하고, 해당 기사의 카테고리 역할을 범주로 선택합니다. 2가지 변수를 정해주는 것입니다.
이후 파이프라인 탭을 눌러 파이프라인으로 넘어갑니다. 컨셉에서 ‘사전 정의된 컨셉 포함’을 클릭하면 사람 이름, 회사 이름 등을 추출할 수 있습니다. 형태소 분석 단계에서는 단어가 4개 문서 이하 제거, 불용어 등을 정의할 수 있습니다. 토픽의 개수를 정의하고, ‘범주 및 규칙 자동 생성’을 적용한 다음, ‘파이프라인 실행’을 클릭하면 자동으로 3~4분 내에 머신러닝을 기반으로 모형이 만들어집니다.
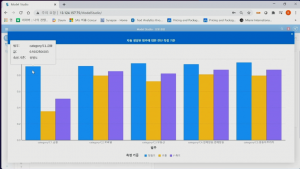
그 결과에서 자동 생성된 범주에 대한 진단 측정 기준을 자세히 보면 각 카테고리별 정밀도를 확인할 수 있습니다. 첫 번째 카테고리(금융)의 정밀도가 89%입니다. 이 정밀도를 높이고자 한다면 이때, 하이브리드 방식을 적용합니다.
‘범주’를 열어 머신러닝이 만든 모형에서 해당 카테고리의 범주를 살펴봅니다. 의문이 되는 부분을 직접 리더블한 모형으로 수정한 후 다시 노드를 실행합니다. 결과를 확인하면 정밀도가 향상된 것을 확인할 수 있습니다. 이처럼 하이브리드로 모델의 정확도를 빠르게 개선할 수 있습니다.
# 머신러닝 기반 키워드 확장
‘사용자 정의 사전’에서 대표 키워드를 입력하여 컨셉을 정의한 다음 노드를 실행하면 학습 데이터 안에서 유사한 키워드를 찾아줍니다. 만일 해당 키워드 내용과 다른 기사가 있다면 ‘샌드박스 실행’을 눌러 해당 룰을 제거하는 방식으로 보다 정확한 사용자 사전의 컨셉을 만들 수 있습니다.
# 머신러닝 기반 핵심 문장 추출
가령 알고자 하는 문제가 가장 잘 표현된 4,000개의 글에서 기사를 찾아보라는 설정을 하고 노드를 실행하면, 컨셉과 해당 문제가 가장 잘 표현된 기사를 찾는 모형을 자동으로 만듭니다. 이처럼 텍스트 분석에서 여러 가지 노드를 확장하고, 속성을 추가하여 분석할 수 있습니다.
SAS를 선택해야 하는 이유
텍스트 분석에서는 텍스트 데이터 전처리 노하우가 굉장히 중요합니다. 최근에는 PDF 문서도 정보계 대상이 되고 있습니다. SAS는 꼭 필요한 텍스트를 만드는 클린징 기술과 함께, PDF 문서의 바디를 일일이 레코드처럼 나눠 테스트 분석에서 원활히 사용할 수 있도록 PDF를 DB화하는 기술을 보유하고 있습니다.
이외에도 SAS는 글로벌하게 검증된 AI 기반의 NLP 자연어 처리 엔진을 보유하고 있으며, AI 머신러닝 하이브리드 방식으로 단시간에 높은 정확도를 만드는 기능을 제공합니다. 그리고 프로젝트가 끝나더라도 현업에서 해당 모형을 쉽게 유지 및 보수할 수 있는 UI를 제공하기 때문에 현업에서 직접 모형을 유지 개선해갈 수 있습니다.