지난 딥러닝 시리즈에서는 SAS Visual Data Mining and Machine Learning을 활용한 딥 러닝 모델 생성에 대한 내용 중 <기본 심층 신경망(DNN) 모델 아키텍처와 배치 정규화를 사용한 DNN 모델 구축>에 대해 소개해 드렸습니다. 이번 시리즈에서는 딥 러닝 성능을 개선할 수 있는 하이퍼파라미터를 조정에 대해 소개해 드립니다.

일정 기간에 걸쳐 성능이 향상되고 학습과 검증 데이터 세트에 대한 성능 곡선이 서로 비슷하게 유지되는 것으로 보아 모델의 최종 성능을 살펴보는 것은 타당한 것으로 보입니다. 그러나 하이퍼파라미터를 조정하면 모델 성능이 향상될 수 있습니다. SAS는 딥 러닝 모델을 개선하기 위해 사용하기 쉬운 튜닝 알고리즘과 하이퍼파라미터에 대한 검색 밴드 구간을 지정할 수 있는 dlTune 액션을 제공합니다. 특히 dlTune 액션은 하이퍼파라미터 검색에 대한 상한 및 하한을 지정할 수 있다는 점을 제외하면 dlTrain 액션과 코딩 옵션 등에 있어 매우 유사합니다. (참고: SAS는 하이퍼파라미터 공간을 샘플링하는 것과 관련하여 원래의 하이퍼밴드 방법을 개선했습니다.) 본 예제 코드에서는 learningrate, gamma, regl1, regl2에 대하여 튜닝을 하였습니다.

DlTune의 결과에서는 여러 하이퍼파라미터 값 조합에서의 모델 성능표를 제공합니다.
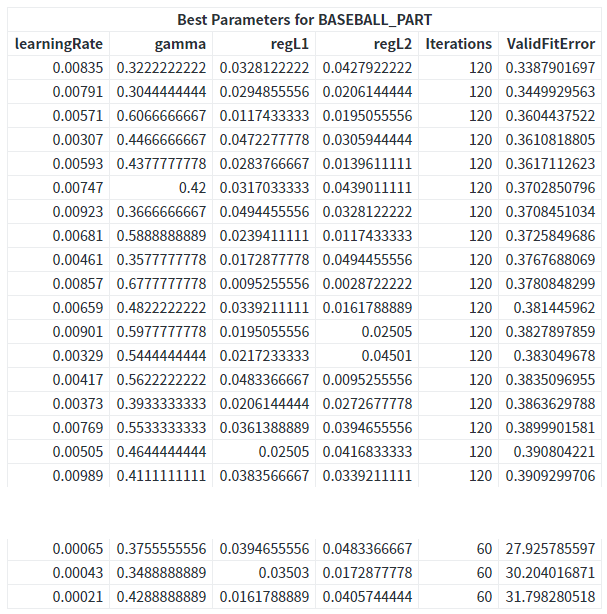
검증용 데이터에 대한 오차에서 최고 (0.339) 조합과 최악 (31.798) 조합 사이에 큰 차이가 있음을 볼 수 있습니다. 이제 dlTune에서 발견한 최고 성능의 하이퍼파라미터 값 조합을 dlTrain 코드에 삽입하여 모델을 재학습합니다.
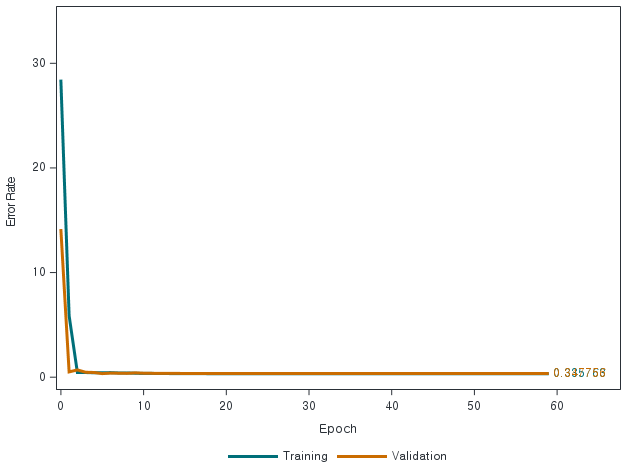
오차 그래프에서 보듯이 튜닝된 딥 러닝 모델 결과는 원래 모델과 비교할 때 훨씬 더 나은 것으로 보입니다.
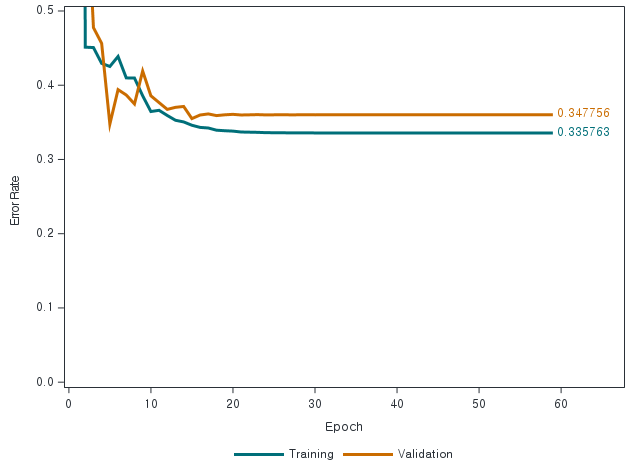
그래프의 y 축 스케일을 조정하여 보면 모델의 성능을 더 명확하게 이해할 수 있습니다.
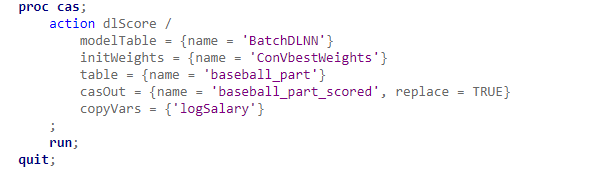
새로운 데이터 스코어링
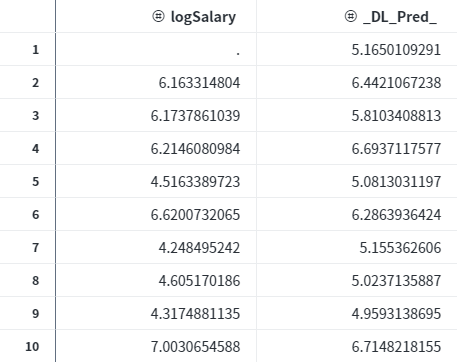
구축된 모형을 이용하여 새로운 데이터를 스코어링하여 예측값을 구할 수 있습니다. dlScore 액션을 통해 계산된 예측값은 결과 테이블의 _DL_Pred_ 컬럼에 저장됩니다.
요약하면 SAS 언어를 사용하여 딥 러닝 모델을 쉽게 구축하고 튜닝할 수 있습니다. 그러나 훌륭한 모델을 구축하는 것이 항상 쉬운 것은 아닙니다. 특히 많은 양의 데이터에 대해 수백만 개의 파라미터가 있는 모델을 학습하는 경우에는 더욱 그렇습니다.
부록: 딥러닝 최적화 알고리즘 및 하이퍼파라미터 자동 튜닝
SAS에서 제공하는 딥 러닝 최적화 알고리즘은 다음과 같으며 다수의 하이퍼파라미터에 대한 자동 튜닝 기능을 지원합니다.
- 최적화 알고리즘
| - Stochastic Gradient Descent
- TRish with Momentum - Layer-wise Adaptive Rate Scaling - Limited-Memory BFGS - Natural Gradient Descent |
- 자동 튜닝 하이퍼파라미터
| - learningRate
- momentum - gamma - power - regL1 - regL2 - dropout - alpha (alphaelastic) |
- damping
- beta1 - beta2 - gradientNoise - miniBatchSize - stepSize - syncFreq (elasticSyncFreq) |
기타 사용법 및 기능에 대한 자세한 사항은 SAS 온라인 도움말을 참조하십시오.
좋은 딥러닝 모델을 구축하는 데 도움이 되는 몇 가지 추가 팁을 가이드 비디오를 통해 더 알아보십시오.





