머신러닝의 블랙 박스 모델을 소개하는 첫 번째 블로그와 두 번째 블로그를 통해서 머신러닝 모델의 복잡성과 머신러닝의 뛰어난 예측 결과를 활용할 수 있는 해석력이 필요한 이유, 적용 분야에 대해서 소개해드렸는데요.
이번에는 기업 실무자 입장에서 SAS 비주얼 데이터 마이닝 앤드 머신러닝(SAS Visual Data Mining and Machine Learning)을 활용한 SAS 커스터머 인텔리전스 360(SAS Customer Intelligence 360)에서 해석 기법과 프록시 방법(Proxy methods), 그리고 모델링 후의 진단법을 알아보겠습니다.
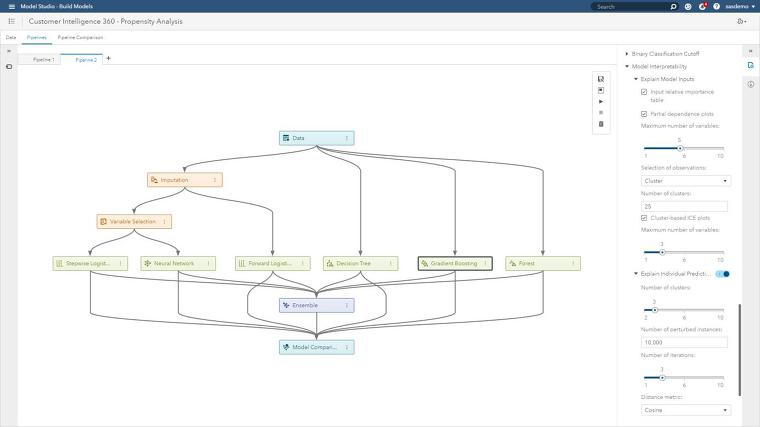
SAS 커스터머 인텔리전스 360에서 해석력 활용하기
먼저 SAS 웹사이트에서 SAS 커스터머 인텔리전스 360으로 도출한 데이터를 해석하는 방법에 대해서 살펴보겠습니다. 실제 애플리케이션에서 머신러닝을 사용해본 경험이 있다면 오분류율(misclassification rate), 평균 제곱 오차(average square error)와 같은 지표나 리프트 곡선(Lift Curve), ROC 차트와 같은 플롯이 매우 유용하기는 하지만 추가적인 진단법 없이 사용할 경우에는 잘못된 정보를 제공한다는 사실을 잘 아실 겁니다.
이는 가끔 사용되어선 안 되는 데이터가 실수로 트레이닝 과정이나 유효 데이터 분석에 포함되기 때문인데요. 이처럼 머신러닝 모델은 가끔씩 비즈니스 과정에서 용납될 수 없는 실수를 하기도 합니다. 때문에 머신러닝 모델의 신뢰성을 판단할 때 기업의 담당자, 즉 실무자가 모델 예측에 대해 이해를 하고 있어야 합니다. 아래에서는 실용적인 접근법을 살펴보겠습니다.

머신러닝 모델의 프록시 방법(Proxy methods) 파악하기
대리 모델(Surrogate Model) 접근법: 대리 모델 접근법은 복잡한 모델을 설명기 위한 대용으로 해석 가능한 모델을 사용하는 접근법입니다. 예를 들어 블랙 박스 모델을 훈련용 데이터에 맞춘 뒤 기존의 훈련용 데이터에 해석 가능한 화이트 박스 모델을 훈련시킵니다. 이때 훈련용 데이터에서 실제 타깃을 사용하는 대신, 보다 복잡한 알고리즘의 예측을 해석 가능한 모델의 타깃으로 사용합니다.
벤치마크 역할의 머신러닝(Machine learning as benchmark): 벤치마크 역할의 머신러닝 방법은 복잡한 모델을 활용해 오분류율과 같은 잠재적인 정확성 지표의 달성 가능한 목표를 설정하는 것인데요. 이 설정한 목표를 기준으로 더 해석하기 쉬운 모델 유형의 출력 값을 비교합니다.
피쳐 생성(feature creation)을 위한 머신러닝: 이 방법은 머신러닝 모델을 통해 피쳐를 추출한 후 변환된 예측변수를 더욱 설명하기 쉬운 모델 유형의 입력 값으로 사용하는 것입니다. 이 방법은 해석력 개선을 위해 SAS에서 지속적으로 연구하는 주제이기도 합니다.
머신러닝 모델링 후 진단은 어떻게 이루어져야 할까요?
모델 예측을 해석하는 능력은 입력 피쳐와 출력 예측 사이의 역학을 점검하는 데 도움이 됩니다. 이 단계에서 해석력은 모델의 가장 중요한 피쳐, 해당 피쳐가 예측에 미치는 영향, 각 피쳐가 예측에 기여하는 방식, 특정 피쳐에 대한 모델의 민감성 등을 파악하는데 도움을 줍니다.
변수 중요도(Variable importance): 모델에서 가장 중요한 입력 값은 무엇일까요? 변수 중요도를 참고하면 이를 쉽게 알 수 있는데요. 아래 시각화 도표에서 중요도는 변수로 분할할 때 나타나는 오류 감소의 합으로 계산됩니다. 피쳐가 더 많은 영향력을 가질수록 중요도 또한 더욱 높아집니다.
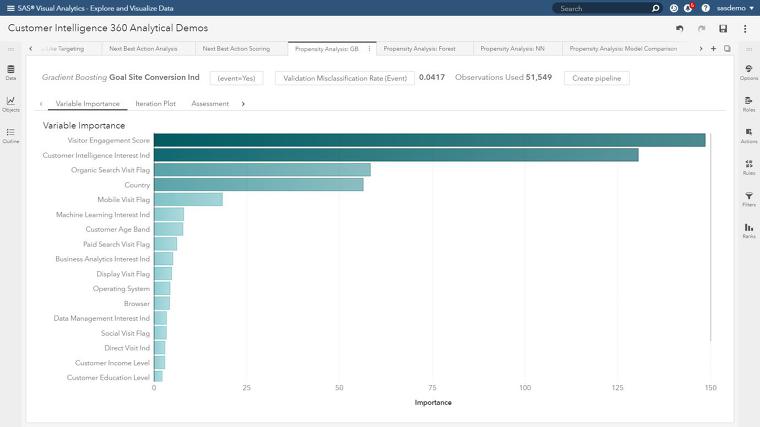
위와 같이 방문자 전환 성향에 중점을 둔 그래디언트 부스팅(Gradient Boosting) 분석의 변수 중요도 플롯은 주의 깊게 살펴봐야 할 부분과 노이즈(Noise)가 무엇인지 신속히 보여줍니다. 방문자 참여, SAS 커스터머 인텔리전스 솔루션 페이지 조회, 자연 검색(Organic Search)에서 발생하는 속성, 방문자 위치 및 모바일 기기의 상호작용과 같은 속성이 리스트 상위에 자리잡고 있습니다.
부분 의존성(PD; Partial Dependence) 플롯: 한 개 이상의 입력 변수와 블랙 박스 모델 예측 간의 관계를 보여주는 이 모델은 모델에 구애 받지 않는 시각적인 기법으로 다양한 머신러닝 알고리즘에 적용할 수 있습니다. PD 플롯은 관심 입력 변수 값에 대한 예측값 의존도 묘사를 통해 지정된 범위 내 관심 변수를 탐색하는데요. 각 변수 값에서 다른 모델 입력의 모든 관측 결과로 모델을 평가한 후 평균값을 출력합니다.
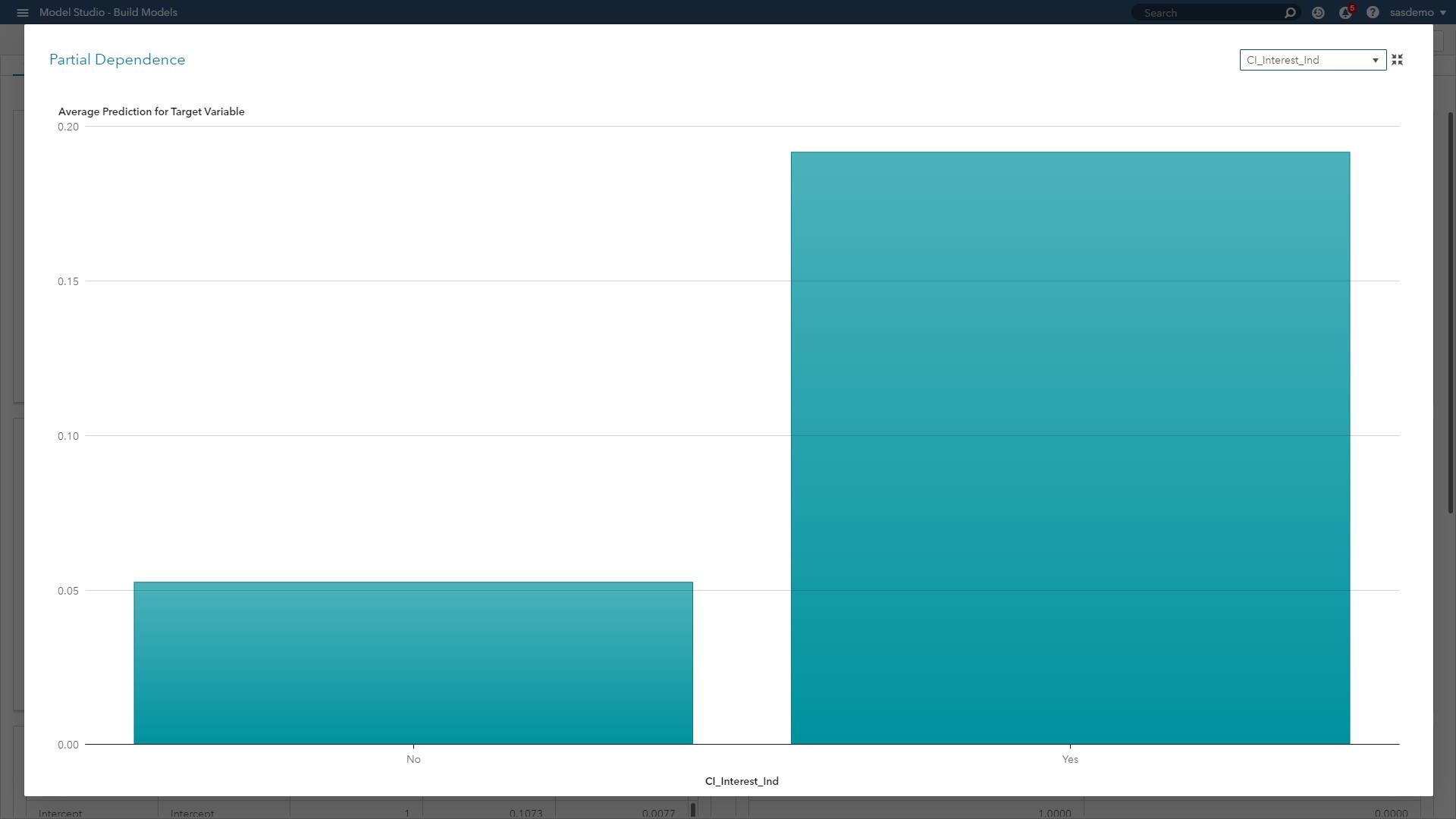
위 그림의 PD 플롯은 SAS 웹사이트 방문자가 SAS 커스터머 인텔리전스 솔루션 페이지를 볼 때 전환 이벤트 개연성 확률이 증가한다는 것을 보여줍니다. 여정 과정에서 방문자가 제품을 보지 않으면 개연성 또한 증가하지 않는다는 것을 알 수 있습니다. 숫자 피쳐의 경우, PD 플롯은 계단 함수(Step Functions), 곡선, 선형 등을 통해 관계 유형을 표시할 수 있습니다.
개별 조건부 기대치(ICE; Individual Conditional Expectation) 플롯: 개별 조건부 기대치는 PD 플롯과 함께 모델에 구애 받지 않는 시각적 기법으로 간주됩니다. ICE 플롯은 개별적인 관측 값 및 세그먼트 수준까지 더욱 세부적으로 들어가 개별 차이 탐색, 하위그룹 확인 및 모델 입력 값 간 상호작용 탐지를 가능하게 합니다. ICE 플롯은 특정 관측 값의 한 특징에 변화를 줬을 때 모델 예측에 일어날 일을 보여주는 일종의 시뮬레이션으로 볼 수 있습니다.
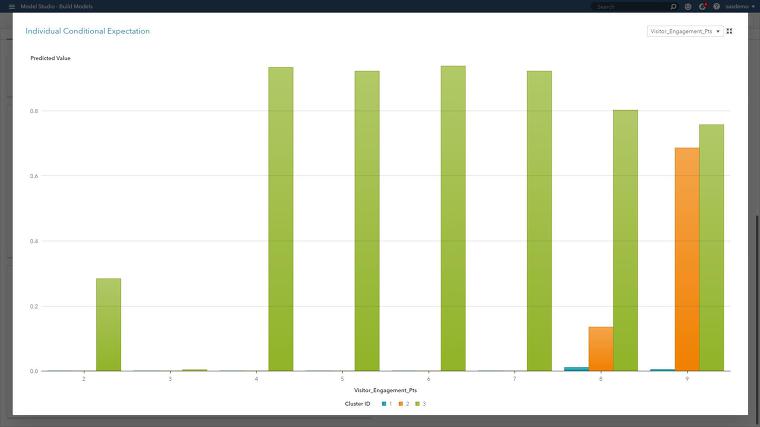
위 ICE 플롯은 SAS 웹사이트 상의 방문자 참여 행동을 3개의 클러스터 세그먼트 관계로 보여주는데요. 참여도 4 이상이 세그먼트 3(연두색)의 강력한 예측 신호, 참여도 9 미만은 세그먼트 2(주황색)의 약한 예측 변수임을 알 수 있고 전체적인 예측 변수로 보았을 때에는 세그먼트 1에는 유용하지 않다는 점을 알 수 있습니다. 결국 ICE 플롯은 평균값인 PD 함수를 분리해 상호작용과 세그먼트 별 고유한 차이를 나타내지요.
ICE 플롯은 시각화 과부하를 피하기 위해 한번에 한 개의 피쳐만 보여줍니다. 대용량의 데이터 세트를 처리해야 할 경우 효율성을 위한 조정 과정이 필요합니다. 예를 들어, 선택한 변수를 삭제하거나 데이터 세트를 샘플링하거나 클러스터링할 수 있는데요. 이러한 기법을 사용해 실제 플롯의 합리적인 근사치를 훨씬 더 빠르게 추정할 수 있습니다.
PD 플롯과 ICE 플롯에 대해 더 자세히 알고 싶다면 레이 라이트(Ray Wright) SAS 수석 머신러닝 개발자(Principal Machine Learning Developer at SAS)의 PD 플롯과 ICE 플롯을 사용해 머신러닝 모델을 비교하고 인사이트를 도출하는 방법에 대한 훌륭한 논문을 추천합니다.
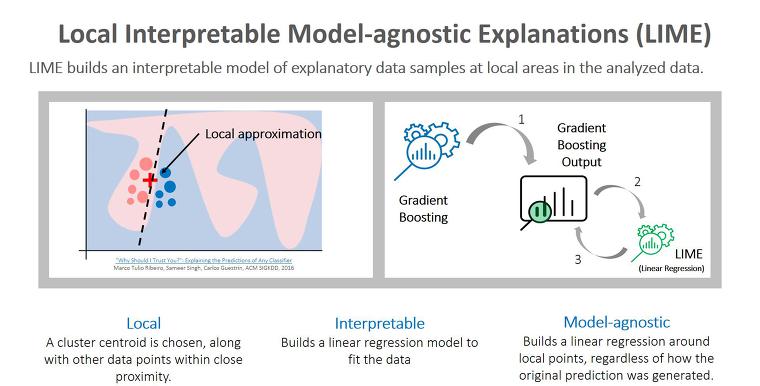
라임(LIME; Local Interpretable Model-agnostic Explanations): 전체적인 시각과 일부 시각은 분석가(Analyst)가 머신러닝 모델이 내린 예측에 대해 더욱 명확한 스토리를 설명하는데 있어 중점을 두어야 하는 중요한 주제인데요. 대리 모델은 합리적인 대안이 될 수 있지만, 동시에 근사화 되어있기 때문에 분석가에게 불안을 야기할 수 있습니다. 하지만 LIME은 분석 데이터의 로컬 영역에서 설명 가능한 데이터 샘플의 해석 가능한 모델을 구축하는데요.
LIME을 사용하는 가장 주된 이유는 모델을 전체적으로 근사하는 것과는 대조적으로 단순한 모델을 이용해 설명하고 싶은 예측 근처에서 블랙 박스 모델을 근사화하는 것이 훨씬 쉽기 때문입니다.
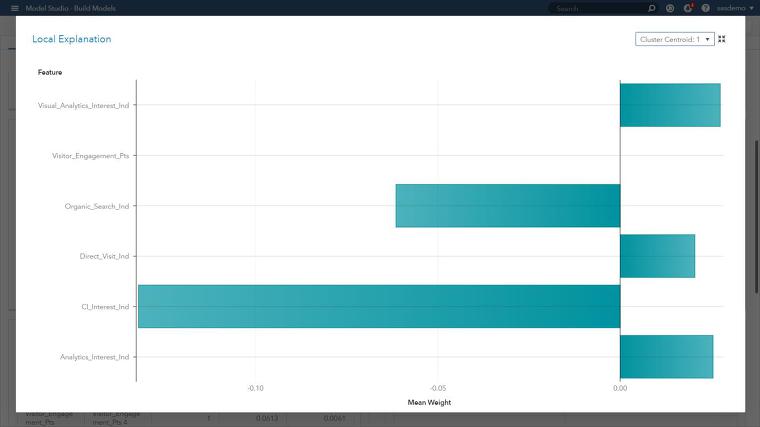
위의 LIME 플롯은 주어진 클러스터 중심(클러스터 1)의 방문자 목표 전환 행동과 관련된 예측변수의 긍정 및 부정적 영향을 요약한 나비 시각 플롯(Butterfly visual plot)을 나타냅니다. LIME 그래프는 로컬 선형 회귀 모델의 모수추정(Parameter Estimates)을 위한 계수를 나타내는데요.
ICE 플롯은 입력 데이터의 교란된(Perturbed) 샘플 세트를 기반으로 특정 관측값에 대한 로컬 모델을 생성합니다. 즉 관심 관측값 근처에서 데이터의 샘플 세트가 생성되는 것인데요. 이 데이터 세트는 원래 입력 데이터의 분포를 기반으로 생성됩니다. 샘플 세트는 원래 모델에 따라 점수가 매겨지고, 샘플 관측값은 관심 관측값의 근접성을 기반으로 가중치가 부여되는데요. 그 후에는 라소(LASSO) 기법을 이용해 변수가 선택되고, 교란된 입력 데이터와 교란된 타깃 변수 간의 관계를 설명하기 위해 선형 회귀가 생성됩니다.
최종 결과물은 관심 관측값 근처에서 유효한 쉽게 해석할 수 있는 선형 회귀 모델인데요. 그림 5의 핵심 메시지는 로컬 샘플 내에서 어떤 예측변수가 플러스 또는 마이너스 추정 값을 갖는지 보여줍니다. 이제 모델 내 또 다른 클러스터에 대한 두 번째 LIME 플롯을 살펴볼까요?
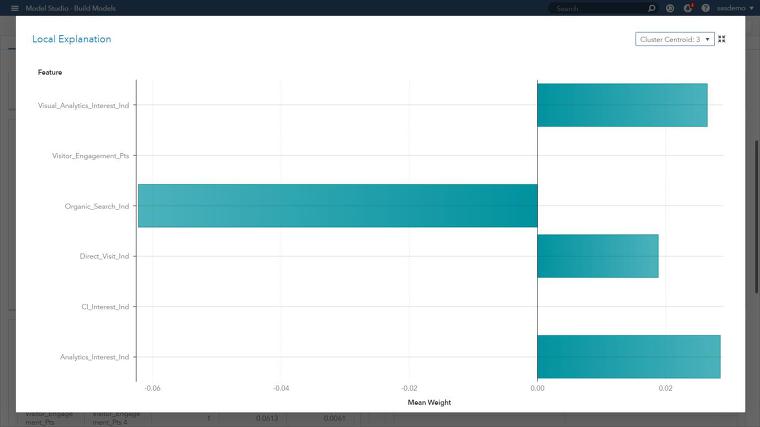
그림 5와 비교했을 때, 그림 7의 새로운 LIME 플롯을 통해 아래의 사항을 알 수 있습니다.
- 한 개의 피쳐를 제외하고 세그멘트 별로 모수추정 전반에 비슷한 예측 트렌드가 발생하고 있다는 확신을 가질 수 있습니다.
- 방문자의 SAS 웹사이트 여정 전반에 걸친 SAS 커스터머 인텔리전스 웹페이지 조회는 클러스터 3이 아닌 클러스터 1에서 마이너스 가중치를 갖습니다.
- 분석가로서 이러한 피쳐를 조사하고 그 영향력에 대한 더욱 깊은 이해를 모색하는 것은 평가, 모델의 신뢰성 형성 및 정확한 인사이트 전달에 도움이 됩니다.
머신러닝 블랙 박스 이해는 향후 모든 산업의 머신러닝 활용 사례를 중심으로 지속적으로 연구하는 분야가 될 전망입니다. 소비자의 디지털 경험이 중요해지면서 방대한 데이터와 분석을 통해 인공지능의 잠재력을 극대화하는 기술도 함께 중요해지고 있는데요. SAS 바이야(SAS Viya)와 SAS 커스터머 인텔리전스 360은 이러한 문제를 해결하는데 도움이 되는 메커니즘과 시각적 진단 기능을 제공합니다.