All Posts


This month I have been holding a series of "coffee breaks" on campus to meet with parents and discuss strategies for busy families. The following is a list of tips I pulled together. Daily Organization ☐ Basket by door for each family member to keep things that need to go

Artificial intelligence has great potential to improve the lives of so many people, especially in the health sector. In Holland, for example, the Amsterdam Medical Center uses computer vision to process patient data, and particularly images. With SAS’ help, it is moving closer to a position where it can deliver


Cualquiera que haya visto películas de Iron Man sabe que su creador, Tony Stark, cuenta, y mucho, con la ayuda de Jarvis, un sistema avanzado de Inteligencia Artificial diseñado para administrar casi todo en su vida, especialmente en la lucha contra el crimen. ¿Alguna vez has imaginado que algo así
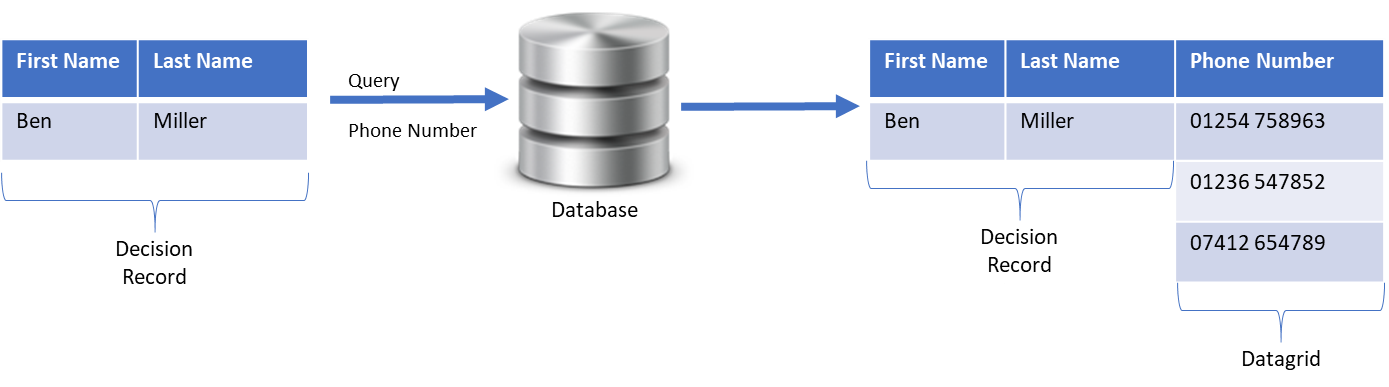

SAS Intelligent Decisioning enables users to create, test, control versioning and trace analytically driven decisions all in one solution.


Jim Harris explains why true transformation requires more than just being data-driven.


Most insurance companies depend on human expertise and business rules-based software to protect themselves from fraud. However, people move on. And the drive for digital transformation and process automation means data and scenarios change faster than you can update the rules. Machine learning has the potential to allow insurers to
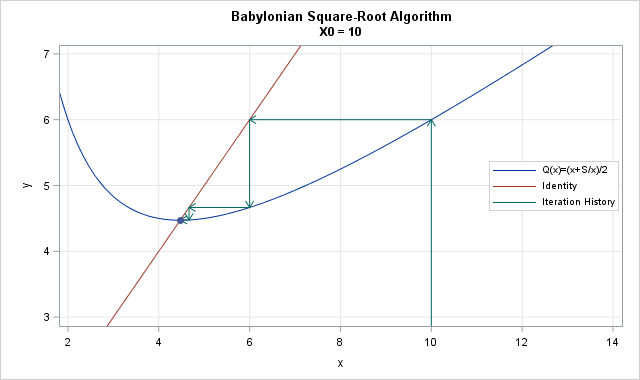

What is this math good for, anyway? –Every student, everywhere I am a professional applied mathematician, yet many of the mathematical and statistical techniques that I use every day are not from advanced university courses but are based on simple ideas taught in high school or even in grade school.


Geocoding is no longer limited to just Base SAS. You can also geocode from within Visual Analytics, thanks to the integration with the Esri geocoding api. This feature is part of the Esri Premium agreement, and became available in VA 8.3.


Each week in August, the Work/Life Team has invited educational experts to address concerns parents have in the process of choosing a school. For our second blogpost in this series, we have invited our experts to respond to the following questions: What questions should I be asking about the school?

データサイエンティストを目指す学生向けのセミナー「データサイエンティストのキャリアと活躍のかたち」の第四回が7/25(木)に開催されました。第一回・第二回・第三回に引き続き、今回も大変多くの学生の皆様に参加していただき、有意義なセミナーとなりました。本記事では、当日の様子についてご紹介します。 本セミナーでは、データサイエンティストのキャリアと活躍の場や、ビジネス上でアナリティクスがどのように活用されるかについて、スピーカーがこれまでの経験をもとに紹介しました。 SHIONOGIにおける開発領域のData Scientistとは? はじめに、データサイエンティストのキャリアについて、塩野義製薬株式会社の木口さんのご講演です。木口さんはSHIONOGIのData Science Groupに所属されている方です。Data Science Groupは主にデータサイエンティストやプログラマーで構成され、生物統計家やデータマネージャーと協業して医薬品開発を行っています。 最初に、医薬品開発におけるデータ活用の様子について紹介していただきました。医薬品開発領域では1つの医薬品が世の中で販売されるまでに、臨床試験を何度も繰り返して仮説を検証します。Data Science Groupは、この過程にデータ活用とデータ駆動型医薬品開発を取り入れています。 医薬品開発で活用されるデータには、生物統計家が仮説の推定・検定を行うための臨床試験データやデータサイエンティストが新たな仮説を設定するためのリアルワールドデータ、仮想臨床試験などをするためのシミュレーションデータがあります。これらのデータを組み合わせて活用して医薬品開発の効率化を行っています。 次にデータサイエンティストに求められる役割とスキルについてです。SHIONOGI医薬品開発領域が考えるデータサイエンティストの役割は、科学的にデータを活用するスペシャリストとして、データ駆動型の業務改善を行い、製品価値最大化のためのデータ駆動型医薬品開発をすることであると伝えていただきました。 また、製品価値最大化のためのデータ駆動型医薬品開発はデータサイエンティストが社内外のデータに基づく仮説の導出をし、その仮説をもとに生物統計家が計画立案をして臨床研究で検証するというサイクルがうまく動くことが理想形であると伝えていただいきました。 この役割を果たすために必要なスキルには、統計理論の知識やプログラミングの技術、ITスキルなどもありますが、木口さんは特にチームの中で自分の思っていることを伝える・相手の意思を受け入れるといった「ビジネススキル」が大切であるとおっしゃっていました。 実際にSHIONOGIの様々な分野の技術を組み合わせた活動事例の紹介をしていただいた最後に、「仕事は、多くの失敗から得たヒントをパズルのように組みあわせ、成功に導くこと」であるというメッセージを学生の皆さんに伝えていただきました。ピースは個人が持つ得意な部分・とがった知識でもあり、それらを組み合わせることで新しい仮説を導くことが役割であるという言葉が印象的でした。 不正・犯罪対策におけるアナリティクスの活用 続いて、不正・犯罪対策の分野おいて活用されるアナリティクスについて、SAS Japanの新村による講演です。 今回の講演では、「不正・犯罪対策」の一例としてマネーミュール(知らずのうちに不正な送金に加担してしまう人)を金融機関とのやり取りから検知する活用例を紹介しました。 怪しいお金のやり取りを不正犯罪の被害者口座から見つけるためには、フィルタリングや異常値検知、機械学習、ネットワーク分析など様々な手段が使われています。それぞれの手段には特徴と難点があるため、SASでは複数の適切な手法を組み合わせて効率的に活用し、高精度な不正検知と新たな不正への対応を実現する(ハイブリットアプローチ)を取り入れています。 後半には、不正検知におけるアナリティクスの特徴をいくつか紹介しました。まず、サービス設計によるモデル・チューニング方針について、 ・本当に不正が起きていて、その不正を予測できる検出率を高める ・本当は不正が起きていないのに、それを不正と予測してしまう誤検知を減らす の両方について考えなければならなりません。また、不正検知はビジネスにおいて対外的な説明を求められるため、誰が見ても検知結果を理解できるような可視化をすることが重要です。さらに、不正対策コストと不正被害額の差を考慮するために経済合理性と理想のバランスが求められることも特徴です。 今回の講演内容はどちらも“データサイエンス”の分野としてイメージが浮かびにくいものだったように思われます。「いい医薬品を開発する」ことや「不正・犯罪を検知する」ためのアナリティクスについて知るきっかけになる、とても貴重な講演でした。 SAS student Data for Good communityの紹介 最後に、学生のデータサイエンスの学びの場としてSAS Student Data for Good communityと Data for Good 勉強会について紹介しました。 Data for Goodとは様々な社会問題に対し、データを用いて解決する取り組みです。今回はData for Goodの具体例としてシアトルの交通事故改善を紹介しました。学生が主体となってこの活動をより推進するため、SASではと「Data for Good勉強会」と「SAS Student
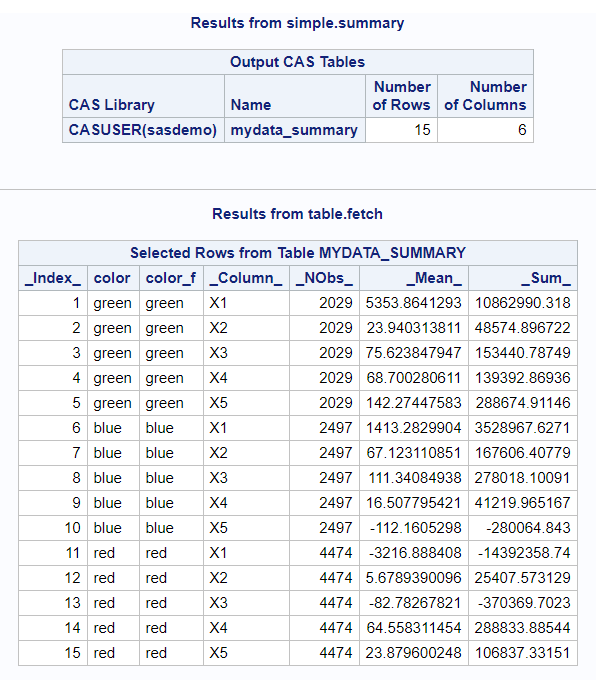

Summarizing numeric data is an important step in analyzing your data. CASL provides multiple actions that generate summary statistics. This blog provides a quick overview of three of those actions: SIMPLE.SUMMARY, AGGREGATION.AGGREGATE, and DATAPREPROCESS.RUSTATS.


What does an analytics platform look like? We might imagine a large server with data and software used for a wide range of operational reporting, BI and data analysis. There may be development and test environments. But typically most users will be working in the same production environment, sharing the


We know the internship search can be stressful, and we want your application and interview experience with us to be a great one! Here’s a complete look at what to expect from our intern hiring process – from application to your first day. 1. Apply! If you’re interested in interning

Flying drones was a new & exciting hobby, and very cool fad a few years ago. In recent years, the drone manufacturers have added some really nice features to make the drones easier to fly and more capable ... but the government also added some new rules that have curbed


Free will is the core of a human being. Free will implies making decisions. But how are decisions defined? Decision making is choosing an alternative from many possibilities. It is a process that results in the selection of a set of actions among several alternative scenarios. But what about business?