前回に引き続き、SASのオンライン学習コース、「Machine Learning Using SAS Viya」についてご紹介します。これはGUI上で機械学習理論を学習できる無料のプログラムです。ご登録方法やWeek1・2に関しては前回の記事をご参照ください。本記事ではWeek3・4の内容をご紹介します。Week3ではDecision Treeについて、Week4ではNeural Networkについて取り扱います。
Week3:Decision Tree and Ensemble of Trees
Week1・2と同様に、通信事業会社の顧客解約率をテーマに機械学習の具体的手法について学習します。Week3では、ディシジョンツリーという手法を用いて、解約しそうな顧客を分類するモデルを作成します。
・Building a Default Decision Tree Model
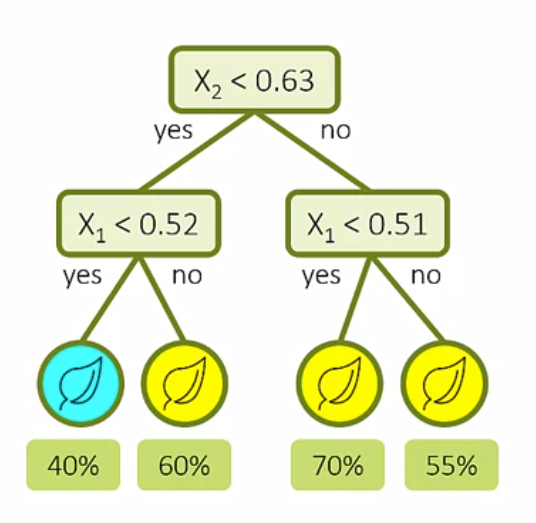
Week3は右図のようなディシジョンツリーについて学習します。これは、図のように各ノードに与えらえた条件式に基づき入力データを分類するモデルです。結果の解釈が容易である点が大きな特徴ですが、オーバーフィッティングに陥りやすいという欠点もあります。デモを参考に基本的なディシジョンツリーを作成しましょう。
・Modifying the Model Tree Structure
ディシジョンツリーはパラメータとして木の構造を変更する事ができます。最大の深さや子ノードの数を変えると木の大きさが変わり、葉の最大要素数を減らすと分割が細かくなります。データの複雑さや過学習などの観点から各パラメータの及ぼす影響を学習し、実際に条件を変更して結果を比べてみましょう。
・Modifying the Model Recursive Partitioning
ディシジョンツリーの作成手順について学習します。まず、ある一つの集合を複数の集合へ分割する基準(不等式など)を作成します。この際、すべての分割方法を考え、その中から要素を最も適切にグループ化できる基準を選択します。例えば動物をグループ化する下の例については、多くの動物が混じっている上の状態よりも、シマウマの比率が高い下の状態のほうが適切とみなせます。ジニ係数やエントロピーを用いると、このような複数のグループの純度を数値的に比較できます。以上のようなグループ化手順を順々に繰り返し、最終的に一つの木構造を作成します。再帰的分割と言われるこの手法の詳細や、分割選択基準となるエントロピー・ジニ係数について学習し、ディシジョンツリーの理論的構造を把握しましょう。

・Modifying the Model Pruning

ディシジョンツリーは、サイズが過度に大きいとオーバーフィッティングを引き起こし、逆に過度に小さいと十分な汎化性能が得られません。そこで、まず最大のツリーを作成した後、重要でないノードを切り落としていくことでサイズを段階的に小さくし、最終的にバリデーションデータに対するスコアが最大となるサイズのツリーを採用します。プルーニングと言われるこの手法を実践しましょう。ツリーの大きさなどモデルに対して外部から設定する条件はハイパーパラメータと言われ、モデルの性能を高めるにはその最適化(チューニング)が不可欠ですが、本セクションではそれを自動的に行う手法も学習します。
・Building and Modifying Ensembles of Trees
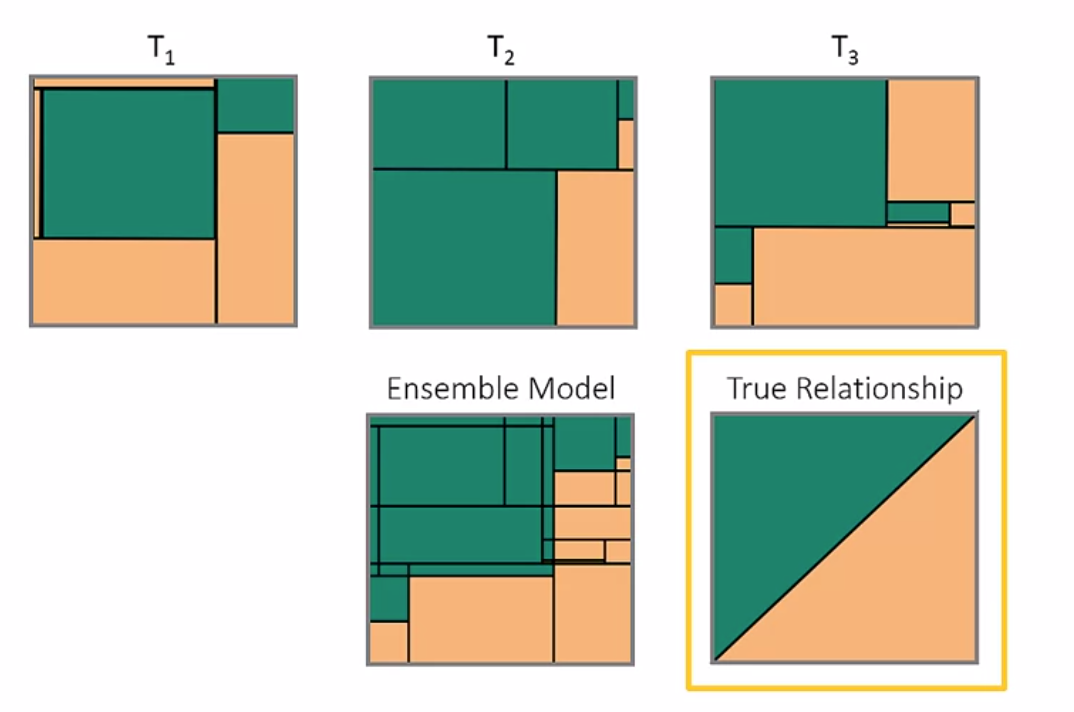
ディシジョンツリーは入力データの影響を受けやすく、微小な変化に対しても大きく構造を変化させるため、安定した構造を取りません。しかし、一般にツリーの構造が変わったとしてもモデルの性能に大きな差が生じないという特徴があります。この性質を活用して、複数の構造のツリーを作成し、その結果を合わせて予測を行うアンサンブルという手法が用いられます。本セクションでは、その代表的手法であるバギング・ブースティング・勾配ブースティング・フォレストについて学習します。また、これらのモデルを実装し、チューニング後のスコアの比較を行います。
Week4: Neural Network
Week4は、Week3と同様に顧客の解約を予測するモデルを、新たにニューラルネットワークという手法を用いて作成する方法を学習します。
・Building a Default Neural Network Model
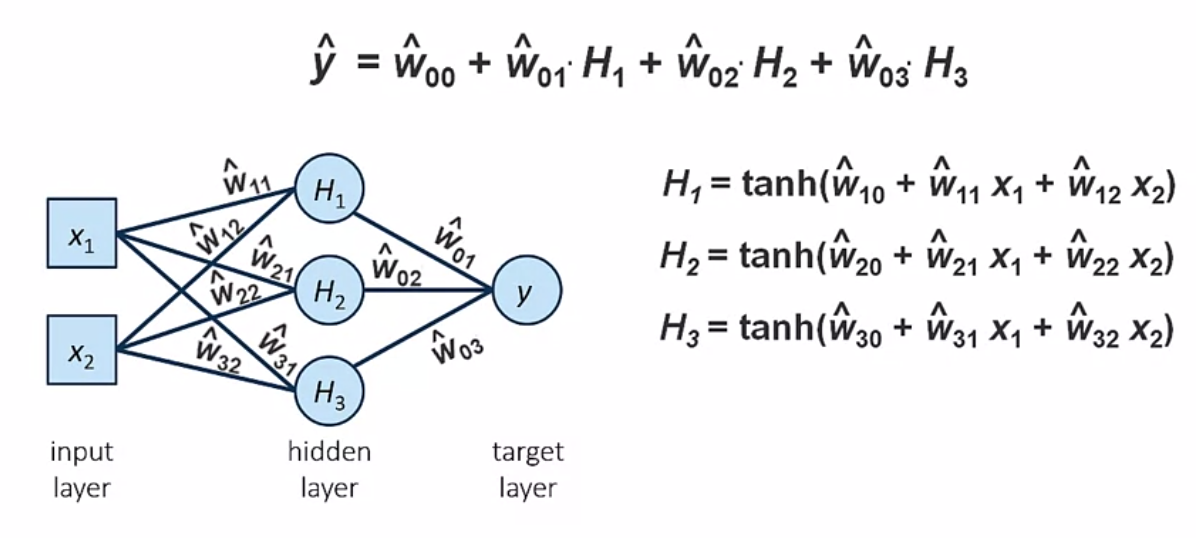
Week4 では人の脳の構造を模したモデルであるニューラルネットワークについて学習します。複雑な関係も表現できることが特徴ですが、結果の解釈が困難であることや、強いパターンのないデータには上手く働きにくいことなどの欠点もあります。右の図は基本的なニューラルネットワークモデルの構造を表しています。入力層・隠れ層・出力層からなり、重みと言われる係数(w)と活性化関数(ここではtanh関数)により各層が接続されています。本セクションでは、モデルの基本的構造・重みの推定方法・結果の予測方法などについて学習します。
・Modifying the Model: Network Architecture
モデルの構造はその性能を左右します。ここでは、隠れ層の数や一つの層当たりのユニット数を変えることで、精度が改善するかを確認します。関連して、Deep Learning の基礎や、活性化関数の特徴についても学習します。
・Modifying the Model: Network Learning and Optimization
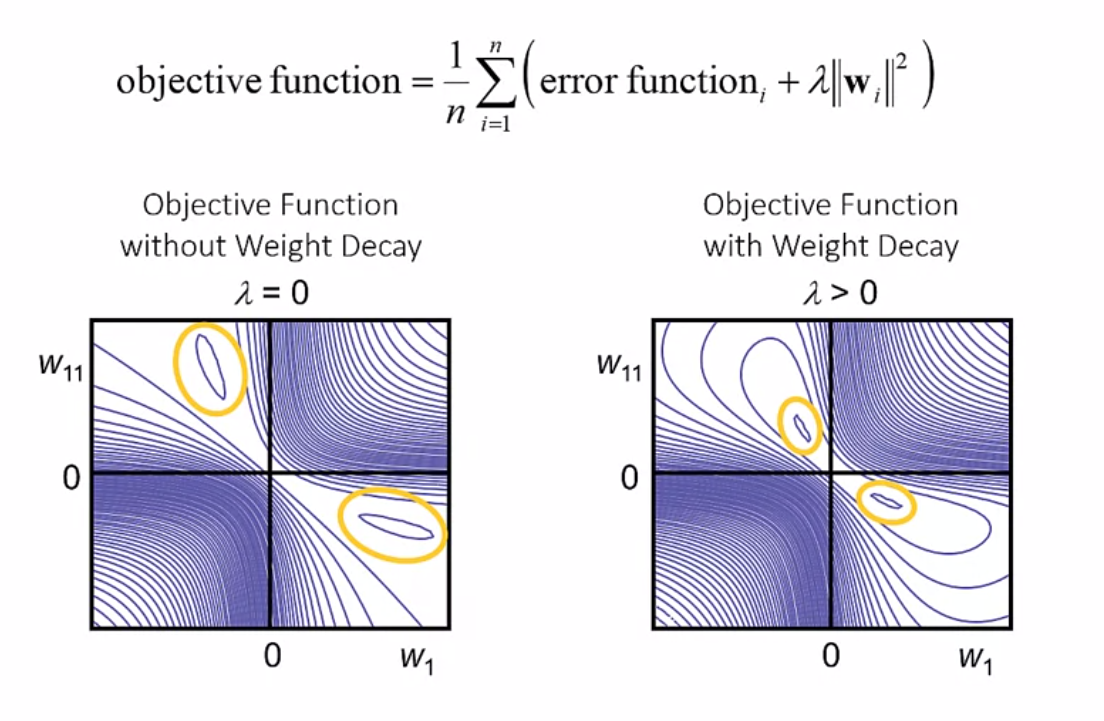
本セクションではオーバーフィッティングを避けるための手法について学習します。一つ目はWeight Decay(重み減衰)です。絶対値の大きな重みを採用した場合、入力の微小変化が重みにより増幅され誤りの原因となりえます。L2正則化という手法では、重みにペナルティを付加しその大きさを制限します。二つ目はEarly Stopping です。学習のエポック数が増大するにつれ過学習が進み、未知データに対する予測能力が低下する可能性があります。Early Stoppingは学習回数を制限し、過学習し始める前に終了させることで、オーバーフィッティングを回避する手法です。これらの手法を学習し、ハイパーパラメータを適当に変更することでモデルの性能がどう変化するか確認してみましょう。
Week3・4の内容は以上となります。Week1・2については前回の記事で、Week5・6については次回の記事でご紹介しておりますので、併せてご参照ください。Machine Learning Using SAS Viyaにはこちらからアクセスできますので、どうぞご活用ください。