本記事では、SASのオンライン学習コース「Machine Learning Using SAS Viya」について引き続きご紹介します。このコースはGUI上で機械学習理論を学習できる無料のプログラムです。ご登録方法やWeek1・2については前々回の記事を、Week3・4については前回の記事をご参照ください。最終回となる本記事では、Support Vector Machineを扱うWeek5と、Model Deploymentを扱うWeek6をご紹介します。
Week5:Support Vector Machines
Week1・2、Week3・4と同様に、通信事業会社の顧客解約率をテーマに機械学習の具体的手法について学習します。Week5ではサポートベクターマシンという手法を用い、解約可能性に基づき顧客を分類するモデルを作成します。
・Building a Default Support Vector Machine Model
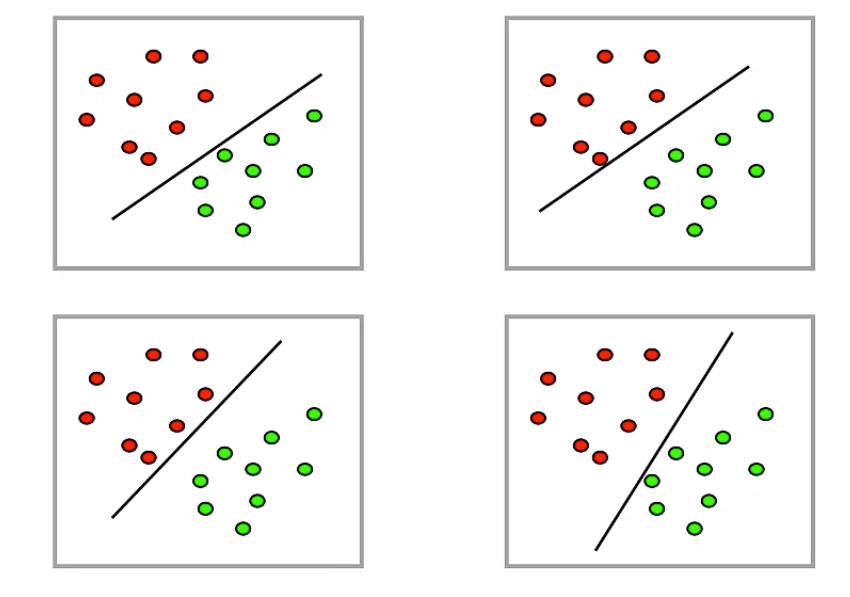
Week5で扱うトピックはサポートベクターマシン(SVM)です。画像認識や文字認識、テキストマイニングで用いられることが多い手法で、複雑なパターンもフレキシブルに表現できるものの、結果の解釈が難しいという特徴を持ちます。分類問題に用いられることが多く、最も簡単な例としては、下の画像のように二種類の出力を分ける直線が挙げられます。この例では分類可能な直線は何通りも考えられますが、マージン最大化という手法を用いて最適な分類線を選択します。本セクションではこれらのSVMの基礎を学習しましょう。
・Modifying the Model Methods of Solution
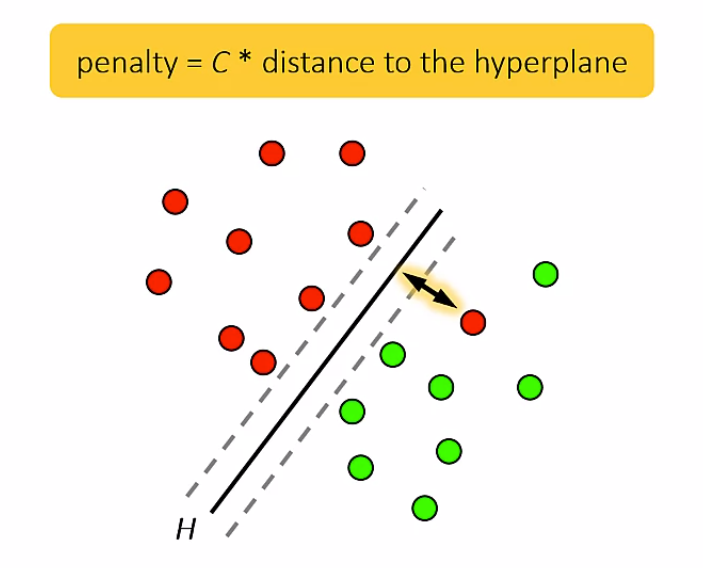
本セクションでは、あるデータセットが通常のSVMで分類できない場合に用いるソフトマージンという手法を学習します。通常のSVMとは異なり、この手法は分類の誤りをある範囲内で許容しますが、それぞれの誤りに対しペナルティを課します。合計のペナルティを最小化する境界を最適な分離平面とみなし、ラグランジュの未定係数法を用いて所望の境界を推定します。ペナルティに関するパラメータを変更しながら、モデルの性能を確認しましょう。
・Modifying the Model Kernel Function
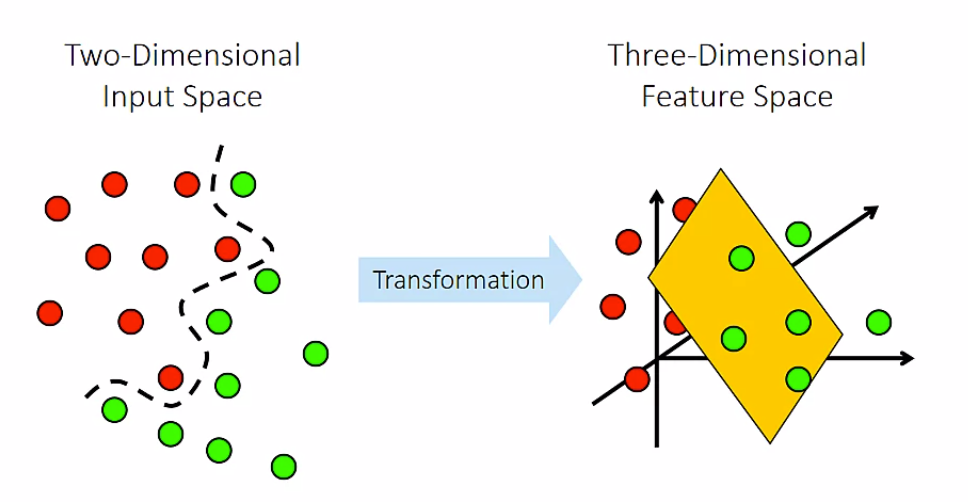
線形分離不可能なデータでも、ある写像により超平面での分離可能な高次元の特徴空間上の点に変換することでSVMが適用可能になります。この際、その特徴空間内における内積は、カーネル関数と呼ばれるものの評価に置き換えられる(カーネルトリック)という性質を用いると、計算量の爆発を防ぎSVMが実装可能です。このカーネル法を用いて、モデルの性能を改善してみましょう。SVMで扱うのはあくまで超平面であるため幾何的な解釈可能性があると言われるものの、多くの場合、依然として十分に複雑で結果の解釈が困難です。そこで解釈を助ける指標としてICEプロットや変数の重要度について学習します。
Week6:Model Deployment
 Week1~5ではデータの前処理やモデルの作成について学習してきました。最終回となるWeek6では、Analytics LifecycleのDeploymentの段階を学習します。
Week1~5ではデータの前処理やモデルの作成について学習してきました。最終回となるWeek6では、Analytics LifecycleのDeploymentの段階を学習します。
・Model Comparison and Selection
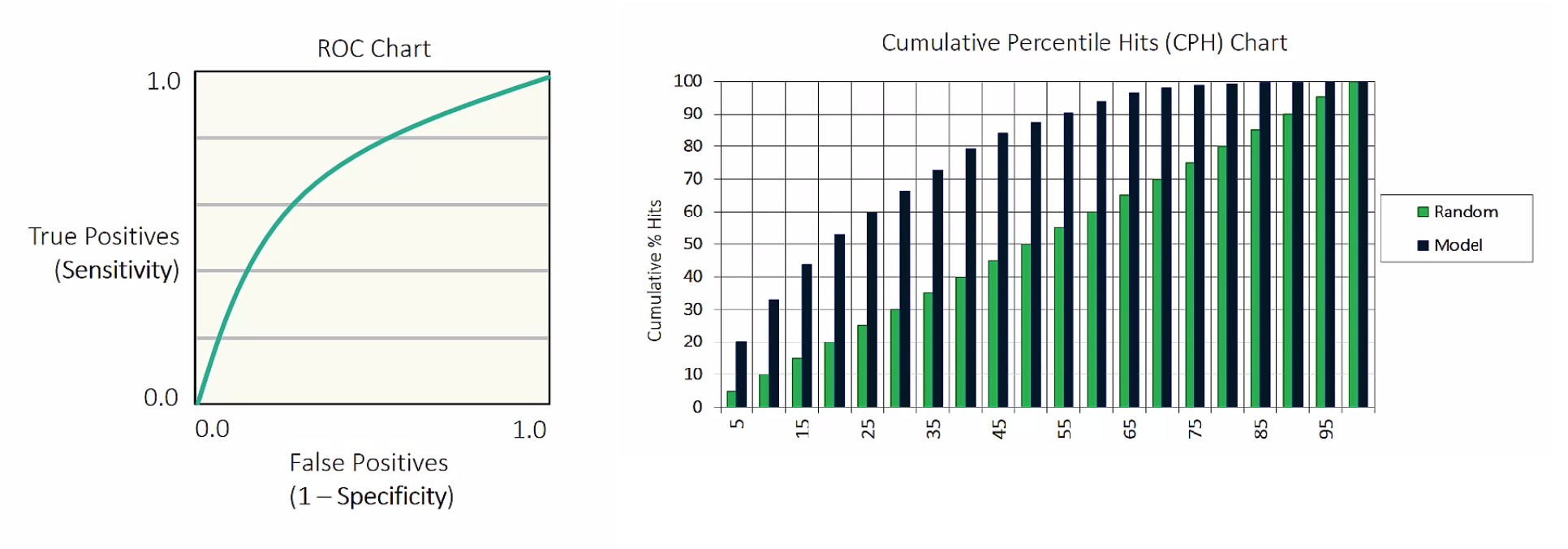
今まで複数のモデルを学習してきましたが、すべての状況において最適なモデルは存在しません。様々な観点でモデル間比較を行い最も高性能なモデルをチャンピオンモデルとして採用します。主に数値的スコアに基づく比較が行われますが、その際、ROC曲線・AUC値を用いたモデル間性能比較や、ゲインチャート(CPHチャート)・LIFTチャートを用いたモデルの採用・不採用の間での比較などが行われます。これらの指標に加えて、ビジネスの文脈に応じ、学習や評価のスピード・実装可能性・ノイズへの頑健性・解釈可能性などを判断基準にすることも考えられます。
・Model Scoring and Governance
 Week1ではData, Discovery, DeploymentからなるAnalytics Lifecycleの概要を学習しました。これまで顧客の解約予測モデルを作成してきましたが、Analyticsはそのモデルを使用して終わりではありません。ビジネスの状況は刻一刻と変化し、それに伴って新たなデータが蓄積されていきます。先ほど決定したチャンピオンモデルがいかに高性能であっても、一定期間後に同様の性能を持つかは決して自明ではなく、モデルのモニタリングを通して性能を逐一確認する必要があります。並行して、新たな状況に関してDataの段階から分析します。その際、新たなチャレンジャーモデルを作成し、現行のチャンピオンモデルとの性能比較によりモデルを改善する手法や、新たに入手したデータを用いて逐一モデルのパラメータを調整するオンラインアップデートという手法が用いて、モデルを高性能に維持します。モデル作成後も継続してDataやDiscoveryの作業を行うことが、Analytics Lifecycleと言われる所以です。
Week1ではData, Discovery, DeploymentからなるAnalytics Lifecycleの概要を学習しました。これまで顧客の解約予測モデルを作成してきましたが、Analyticsはそのモデルを使用して終わりではありません。ビジネスの状況は刻一刻と変化し、それに伴って新たなデータが蓄積されていきます。先ほど決定したチャンピオンモデルがいかに高性能であっても、一定期間後に同様の性能を持つかは決して自明ではなく、モデルのモニタリングを通して性能を逐一確認する必要があります。並行して、新たな状況に関してDataの段階から分析します。その際、新たなチャレンジャーモデルを作成し、現行のチャンピオンモデルとの性能比較によりモデルを改善する手法や、新たに入手したデータを用いて逐一モデルのパラメータを調整するオンラインアップデートという手法が用いて、モデルを高性能に維持します。モデル作成後も継続してDataやDiscoveryの作業を行うことが、Analytics Lifecycleと言われる所以です。
本コースの内容のご紹介は以上になります。Week1・2は前々回の記事、Week3・4は前回の記事にて扱っておりますので、併せてご参照ください。Machine Learning Using SAS Viyaにはこちらからアクセスできます。どうぞご活用ください。
さらに学習を深めるために、実践は有効な手段です。SASでは、学んだ理論を実践に移す場として、SAS Japan Student Data for Good Community という学生コミュニティを支援しています。データを用いた社会問題へのアプローチを通して、データサイエンティストの役割である「課題の設定」から「データを用いた解決法の提示」までの一連の流れを経験できます。本コミュニティは引き続き学生の参加者を募集しておりますので、ご興味がおありでしたら、下記の事項をご記入の上JPNStudentD4G@sas.comまでご連絡ください。
- 大学名 / 高校名
- 名前
- メールアドレス