All Posts


Let’s be real: no single language rules the world anymore. It’s all about the right tool for the job. You’ve seen the lists: “Top Programming Languages of 2024.” “Python vs. Rust: The Ultimate Showdown.” “Why Java Refuses to Die.” But you rarely see SAS on these lists. And I get


AI는 비즈니스와 기술 분야에서 여전히 가장 뜨거운 주제이지만, 아직 AI를 효과적으로 활용하여 가치를 창출하는 데에는 어려움이 많습니다. 여기 여러분의 능력을 발휘할 기회가 있습니다. 제 5회 'SAS 해커톤'에 참여하시고 최신 AI 기술을 활용한 가치 창출에 도전해 보세요! *SAS 해커톤 참가등록 : 등록 링크* 지금부터 8월 31일까지 등록할 수 있는 이번 해커톤은


La gestión de riesgos ha evolucionado de ser una función meramente defensiva a convertirse en un motor estratégico clave para el crecimiento sostenible. Ya no se trata solo de proteger el valor existente, sino de identificar y aprovechar nuevas oportunidades que, si se gestionan adecuadamente, pueden afectar a las organizaciones


Agentic AI is more than just the next step in automation. It’s a shift toward systems that don’t just respond to commands – they reason, decide and act with a blend of analytics and embedded governance. This is the second blog post in a series exploring how to design AI

은행업계의 미래는 지금보다 지능화되겠지만 위험도는 더 높아질 것이라는 연구결과가 발표되어 업계의 이목을 끌고 있습니다. SAS의 후원을 받아 이코노미스트 임팩트(Economist Impact)가 진행한 새로운 연구에서는 은행업계가 직면해 있는 선택지와 앞으로 나아갈 방향을 짚어보고, '디지털 인텔리전스 시대'를 선도하기 위한 5가지 필수 요소를 제시합니다. 전 세계 금융 기관은 심화되는 경제적 변동성, 폭발적인 기술 가속화


Existen diversas fechas clave para el retail como fiestas decembrinas, día de las madres, San Valentín, Cyber Monday, Hot Sale, entre otras, que derivan de un importante aumento en el consumo minorista reflejado en los tickets de compra de estas cadenas. Actualmente las soluciones basadas en Inteligencia Artificial (IA) y

SAS가 고객 여러분에게 더 가까이 다가가기 위해 지난 6월 10일 여의도 페어몬트 앰배서더 서울에서 'SAS 이노베이트 온 투어' 행사를 개최했습니다. 이 행사는 지난 5월 미국 플로리다주 올랜도에서 열린 SAS의 연례 컨퍼런스 ‘SAS 이노베이트 2025(SAS Innovate 2025)’의 핵심 내용을 각국의 고객들께 직접 전해드리기 위해 마련된 자리로서, 올해는 서울을 포함한 15개 주요


Many of today’s fraudsters are figuring out how to use AI to automate and structure scams that are unique to each person they target. If fraudsters can analyze your data, learn your patterns, track your interests, and exploit who you trust – how can you combat them? According to SAS
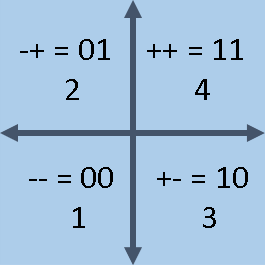

This article shows how to classify a set of high-dimensional data into orthants. An orthant is the d-dimensional generalization of a quadrant. For 2-D Euclidean space, there are four quadrants, often labeled by Roman numerals I-IV. The quadrants are open sets that are defined by the signs of each coordinate


Hyperparameter autotuning intelligently optimizes machine learning model performance by automatically testing parameter combinations, balancing accuracy and generalizability, as demonstrated in a real-world particle physics use case.


Authors: Bahar Biller, Jagdishwar Mankala, and Jinxin Yi Managing spare parts inventory is a critical aspect of asset performance management, especially in industries where equipment downtime is costly. This post, based on a real-world project with a major aircraft manufacturer, explores how to optimize spare parts inventory under uncertainty. We
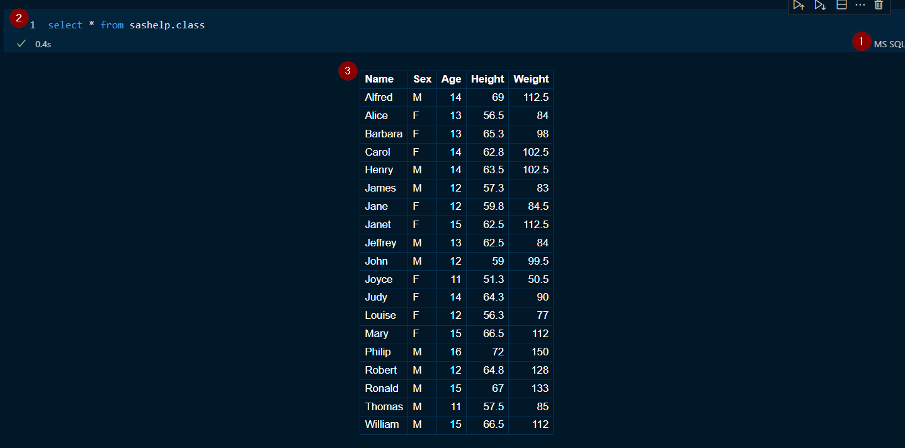

A hands-on introduction to SAS Notebooks in SAS Viya Workbench, showing how to combine code, SQL, and Markdown for a more productive and interactive coding experience.

AI is only as powerful as the data behind it. You’ve probably heard the phrase “garbage in, garbage out.” That’s always been true in analytics, but in today’s AI-driven world, the consequences of poor data are greatly amplified. Flawed models, biased predictions and opaque decision-making all trace back to one


Foi exatamente esse o tema da palestra de Lyse Nogueira, Customer Advisor do SAS, hoje, no Febraban Tech 2025! Segundo a executiva, no setor bancário, entender o cliente como um universo único deixou de ser um diferencial — tornou-se uma exigência. Mas como escalar personalização com inteligência, aumentar a relevância


Hosting can come with many different emotions for each of us. Often, as we plan and prepare to invite people into our homes, it can be stressful. We are tasked with preparing, shopping, cooking, and cleaning — all before anyone even rings the doorbell. If you’re anything like me, these