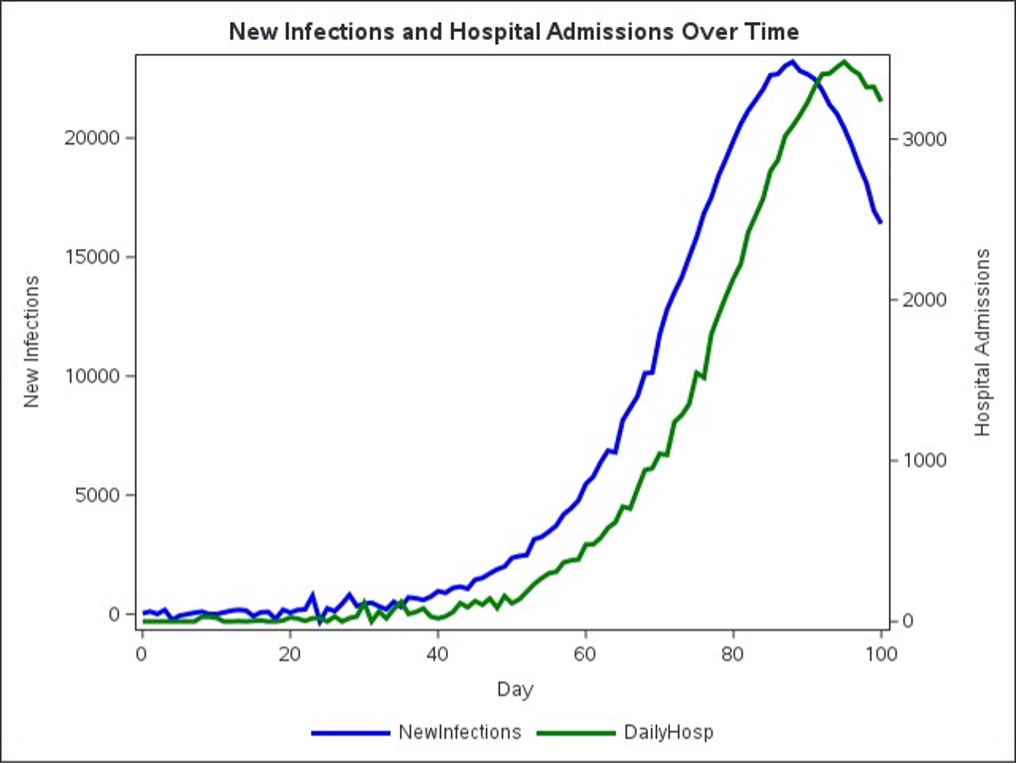
Accurately identifying lags between related time series is crucial in forecasting, especially in public health, where delays between events, such as infections and hospital admissions, significantly impact decision-making. Consider a realistic scenario where you must plan hospital resources based on infection data. In an epidemic, new infections today typically result in hospitalizations days later, creating a lagged relationship that you must precisely identify for effective preparedness and response. To illustrate this challenge, you will simulate a 100-day epidemic using an SEIR (Susceptible, Exposed, Infectious, Recovered) epidemiological model. The SEIR model captures infectious disease progression through distinct stages. In this simulation, you will explicitly encode a realistic seven-day lag between new infections and resulting daily hospital admissions, including epidemiological parameters—such as infection rate (β = 0.30), incubation period (average five days), recovery rate (average ten days), and hospitalization proportion (15%)—plus random variability to mimic real-world reporting fluctuations.
Figure 1 visually confirms the intended seven-day lag, clearly showing hospital admissions consistently trailing the new infections curve by about a week.
While visually intuitive, systematically identifying this lag poses significant challenges. Traditional correlation measures—such as Pearson correlation—are designed primarily for linear relationships and can mislead you in cases involving nonlinear dynamics common in epidemic scenarios. To robustly detect both linear and nonlinear relationships, you will use distance correlation, available in SAS Viya through PROC TSSELECTLAG. Distance correlation captures complex nonlinear dependencies, ensuring more accurate detection of lag structures. Distance correlation mathematically evaluates dependency via pairwise Euclidean distance matrices. For n observations on 2 random variables {(Xk,Yk) : k = 1,...,n}, compute pairwise distances and double-center them into matrices aij and bij, yielding empirical distance covariance Vn2(X,Y ) and correlation Rn(X,Y ):
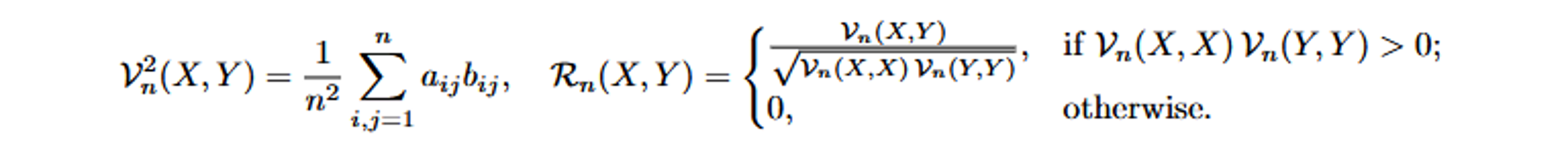
Distance correlation reliably detects independence and nonlinear associations.
To demonstrate this practically, you will create a CAS session and generate simulated data:
cas mysess; libname mylib cas sessref=mysess; data mylib.epi(keep=Time NewInfections DailyHosp); call streaminit(12345); N=1e6; beta=0.30; sigma=1/5; gamma=1/10; p=0.15; lagH=7; days=100; S=N-200; E=100; I=100; R=0; array NI[0:1000] _temporary_; do Time = 0 to days; NewInfections = sigma*E + rand("t",3)*105; NI[Time]=NewInfections; DailyHosp=0; if Time>=lagH then do; DailyHosp=p*NI[Time-lagH]+rand("t",3)*15; if DailyHosp<0 then DailyHosp=0; end; dS=-beta*S*I/N; dE=beta*S*I/N - sigma*E; dI=sigma*E - gamma*I; dR=gamma*I; S+dS; E+dE; I+dI; R+dR; output; end; run; ods output Results=pearTbl; proc tsselectlag data=mylib.epi minlag=1 maxlag=14 correlationtype=pearson; id Time; yvar DailyHosp; xvar NewInfections; run; |
Applying PROC TSSELECTLAG with Pearson correlation mistakenly identifies the strongest correlation at lag 2 due to linear assumptions of Pearson correlation.

The following call to PROC TSSELECTLAG computes the distance correlation between the lags of new infections and daily hospitalizations.
ods output Results=distTbl; proc tsselectlag data=mylib.epi minlag=1 maxlag=14 correlationtype=distance; id Time; yvar DailyHosp; xvar NewInfections; run; |
Distance correlation correctly identifies the maximum correlation at lag 7.
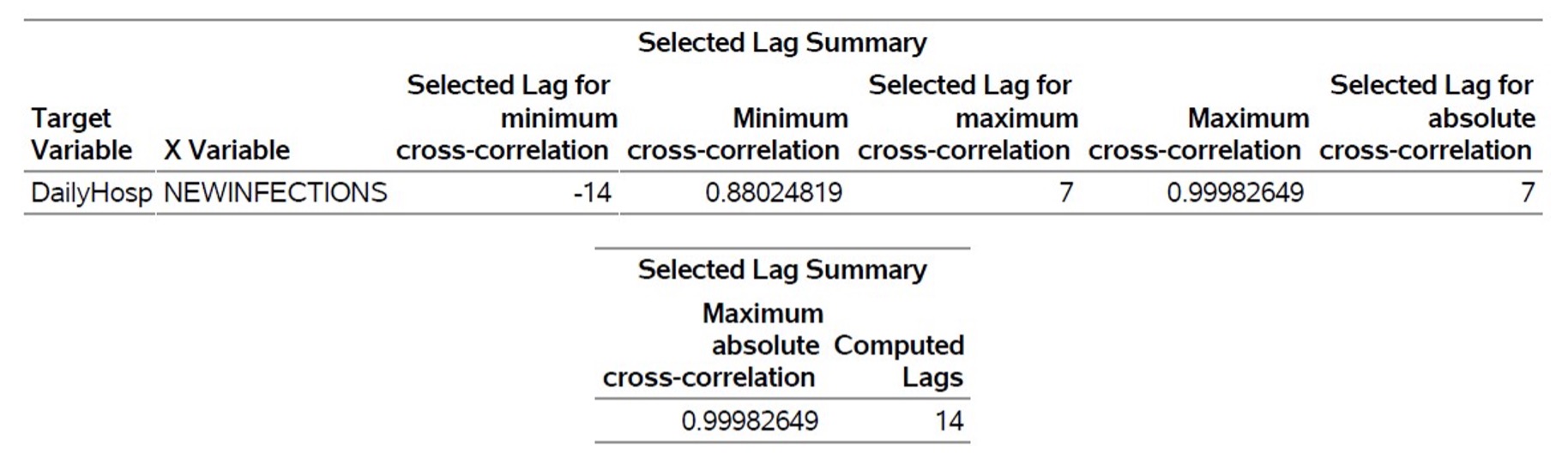
By using distance correlation via PROC TSSELECTLAG, you will overcome limitations of Pearson correlation, accurately capturing nonlinear lag structures essential for reliable forecasting. Capturing the correct lag structure improves forecast accuracy.