최근 ChatGPT에 대한 관심이 대단합니다. 2022년 12월 공개된 지 5일만에 사용자100만 명을 기록했고, 지난 2023년 2월 기준, 월 사용자 1억 명이 넘는 서비스가 되었습니다. 마치 2016년 이세돌을 이긴 알파고 출현 당시와 같이 세간의 관심이 쏟아지고 있습니다.
사람들이 이렇게 열광하는 이유는 ChatGPT가 생성하는 답변이나 글의 수준이 사람이 생성하는 것 이상으로 훌륭하기 때문입니다. ChatGPT는 대부분의 질문에 대해서 누가 보아도 손색이 없을 정도의 답변을 하고 있습니다. 아래는 몇 가지 한글 예시입니다.
분석용 SAS 소프트웨어의 오픈소스 대비 장단점에 대한 설명을 요청했을 때 ChatGPT의 답변입니다.
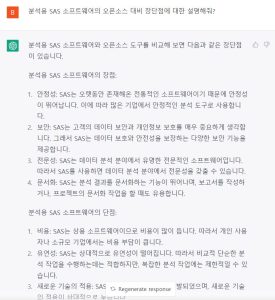
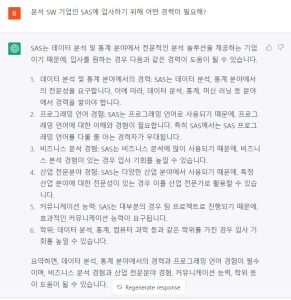
또 다른 질문으로, SAS에 입사하기 위해서 어떤 경력이 필요한 지에 대한 답변입니다.
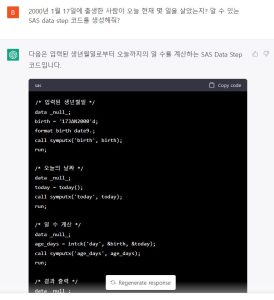
ChatGPT가 코딩도 가능하다고 하여 특정일에 태어난 사람이 오늘 현재까지 살아온 날 수를 계산하는 SAS코드를 요청해보았습니다.
이처럼 ChatGPT가 현재의 똑똑한 위치에 도달할 수 있게 된 것은 하루 아침에 이루어진 것이 아닙니다. 지난 50 여 년 동안 NLP(Natural Language Processing) 기술의 발전이 있어 왔기 때문에 가능한 것입니다. 이에 NLP기술의 주요 발전 역사를 살펴보고자 합니다.
1966: ELIZA
1966년에 ELIZA라는 챗봇이 MIT 인공지능 연구소에서 Joseph Weizenbaum에 의해 만들어졌습니다. ELIZA는 Rogerian 성격 심리치료사를 모방하기 위해 디자인되었습니다. ELIZA는 패턴 매칭(정규 표현식과 문자열 치환 등)을 사용하였습니다.
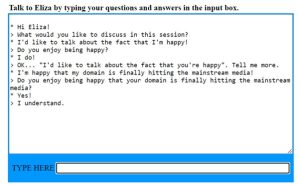
ELIZA는 사람들이 신뢰할 만한 결과를 제공했고, 챗봇 분야는 큰 발전을 이룩했습니다. 최초로 개발된 챗봇 중 하나였기 때문에 Turing Test를 시도할 수 있는 최초의 프로그램 중 하나였습니다. 참고로 Turing Test는 기계가 인간과 같은 지능적 행동을 나타낼 수 있는지 그 능력을 테스트하는 모의 실험입니다.
1970년대 - 1990년대
비정형 텍스트 데이터를 분석하는 방법들은 계속해서 발전해왔습니다. 1970년대에는 bell bottoms과 case grammars, semantic networks, conceptual dependency theory등이 소개되었습니다. 1980년대에는 forth big hair, glam, ontologies 및 전문가 시스템(화학 분석용 DENDRAL과 같은)이 등장했습니다. 1990년대에는 grunge, statistical models, recurrent neural networks 및 LSTM(Long Short-Term Memory) 모델이 나왔습니다.
2000년 - 2015년
이 시기에는 단어 임베딩(word embeddings) 및 Google 번역에서 큰 발전이 있었으며 자연어 처리 분야에서 놀라운 마법이 일어난 때입니다. Word2Vec, 인코더-디코더 모델(encoder-decoder models), 어텐션 및 트랜스포머(attention and transformers), 사전 훈련된 모델(pre-trained models) 및 트랜스퍼 모델(transfer models) 등이 지금 우리가 경험하고 있는 기술 수준의 선구자 역할을 했습니다. 이러한 기술들로 GPT와 같은 수십억 개의 파라미터를 가진 거대 언어 모델을 구현할 수 있게 된 것입니다.
2015년 이후 : Word2vec, GloVe 및 FASTTEXT
Word2vec, GloVe, 그리고 FASTTEXT는 단어 임베딩 또는 단어 벡터화에 초점을 맞추고 있습니다. 단어 임베딩은 어휘에서 단어나 구를 해당하는 벡터에 매핑하여 단어 예측 및 단어 유사성 또는 의미를 찾는 데 사용되는 NLP 방법론입니다. 단어 벡터화의 기본 아이디어는 유사한 의미를 가진 단어는 비슷한 벡터 표현을 갖게 될 것이라는 것입니다.
Word2vec은 가장 일반적인 단어 벡터화 방법 중 하나입니다. 대규모 텍스트 말뭉치에서 단어의 벡터 표현을 학습하기 위해 신경망을 사용합니다. 단어 벡터는 유사한 맥락에서 사용되는 단어들이 비슷한 벡터 표현을 갖는 것으로 학습됩니다. 예를 들어, 고양이(cat)와 개(dog)의 벡터는 다르지만, 고양이(cat)와 새끼고양이(kitten)의 벡터는 비슷하게 학습됩니다.
다른 단어 벡터 생성 기술로는 GloVe(Global Vectors for Word Representation)가 있습니다. GloVe는 word2vec과는 다른 방식을 사용하는데, 공존 행렬을 학습함으로써 단어 벡터를 익히는 방식입니다.
단어 벡터 집합이 학습되면 텍스트 분류, 언어 번역 및 질문 응답과 같은 다양한 자연어 처리(NLP) 작업에 사용될 수 있습니다.
2017년 : 트랜스포머 모델(Transformer models)
트랜스포머 모델은 "Attention Is All You Need"라는 2017년 논문에서 처음 소개되어, 비구조화된 데이터의 분석에 있어 기계 학습 사용 방식을 혁신적으로 변화시켰습니다. 트랜스포머 모델의 주요한 혁신 중 하나는 self-attention 메커니즘을 사용하는 것입니다. 이를 통해 모델은 예측을 할 때 입력의 다른 부분의 중요성을 가중치로 조절할 수 있습니다. 이는 특히 언어 번역과 같은 작업에서 유용합니다. 단어의 의미는 문장 앞에서 나온 많은 단어들에 따라 결정될 수 있기 때문입니다. 또한, 트랜스포머 모델의 다른 중요한 기능 중 하나는 multi-head attention을 사용하는 것입니다. 이를 통해 모델은 입력을 순차적으로 처리하는 대신 병렬로 처리할 수 있어, 한 번에 하나씩 입력 처리하는 방식보다 효율적인 작업이 가능해졌습니다.
엘모(ELMO, Embeddings from Language Model)
ELMo는 양방향 LSTM으로 입력 시퀀스를 앞뒤 방향 모두에서 처리하여 시퀀스 내 과거와 미래 단어에서의 문맥 정보를 캡처합니다. ELMo에서 양방향 LSTM 네트워크는 많은 양의 텍스트 데이터로 훈련되어, 문맥에 대한 풍부한 의미론적 구문 정보를 캡처하는 문맥 단어 임베딩을 생성합니다. 이는 다의성(다른 의미), 특히 동음 이의어를 관리하는 데 도움이 됩니다. 동음 이의어란 문맥에 따라 하나의 단어가 여러 가지 의미를 가지는 것을 말합니다. BANK는 이러한 다의성의 예입니다. BANK는 강의 둑을 뜻하거나 돈을 보관하는 은행을 의미할 수 있습니다.
ELMo는 문맥에서 단어를 더 잘 관리할 수 있기 때문에 의도된 의미가 무엇인지 해독하는 데 도움이 됩니다. 이러한 단어 관리 능력은 문맥을 고려하지 않는 단어 벡터 모델인 word2vec 및 GloVe와 같은 벡터 의미 모델과 비교하여 극적인 개선을 제공합니다.
버트(BERT, Bidirectional Encoder Representations from Transformers)
BERT는 트랜스포머 기반 아키텍처를 사용하여 입력 시퀀스를 효과적으로 처리하고, 토큰 또는 단어의 왼쪽과 오른쪽에서 컨텍스트를 캡처할 수 있습니다 (BERT의 B는 양방향을 의미합니다). 반면에 ELMo는 순환 신경망(RNN) 아키텍처를 사용하기 때문에 긴 입력 시퀀스를 처리하는 데 효과적이지 않습니다. BERT는 방대한 양의 텍스트 데이터에서 사전 학습되며, 질문 응답 및 감성 분석과 같은 특정 작업에 맞게 미세 조정될 수 있습니다. 반면 ELMo는 작은 양의 텍스트 데이터에서만 사전 학습되며 미세 조정이 되지 않습니다. BERT는 또한 입력의 일부 토큰을 무작위로 마스킹한 다음 마스킹된 토큰의 원래 값을 예측하도록 훈련시키는 ‘마스킹된 언어 모델링’을 목표로 학습합니다. 이를 통해 BERT는 단어가 나타나는 컨텍스트에 대한 더 깊은 의미를 학습할 수 있습니다. 반면에 ELMo는 다음 순번의 단어만을 예측하는 방식으로 학습합니다.

GPT(Generative Pre-trained Transformer)
GPT 또는 생성형 사전 학습 모델은 BERT와 함께 출시되었으며, 서로 다른 목적을 가지고 디자인되었습니다. BERT는 문장의 의미를 이해하는 데 사용되는 반면, GPT 모델은 텍스트를 생성하기 위해 설계되었습니다. GPT 모델은 대규모 텍스트 데이터로 학습된 일반적인 언어 모델로, 텍스트 생성, 번역, 요약 등 다양한 NLP 작업을 수행할 수 있습니다.
① GPT-1(2018)
이것은 첫 번째 GPT 모델로, 인터넷에서 수집한 대규모 텍스트 데이터를 기반으로 학습되었습니다. 1억 1700만 개의 매개변수를 가졌으며, 학습 데이터와 매우 유사한 스타일과 내용의 텍스트를 생성할 수 있었습니다.
② GPT-2(2019)
이 모델은 GPT-1보다 더 방대한 15억 개의 매개변수를 가지고 있으며, 더 큰 양의 텍스트 데이터를 기반으로 학습되었습니다. 이 모델은 이전 버전보다 훨씬 더 일관된 텍스트를 생성할 수 있었으며, 인간과 같은 자연스러운 문장을 만들어냈습니다.
③ GPT-3(2020)
이것은 가장 최근에 개발되어 일반적으로 사용되는 GPT 모델로, 1750억 개의 매개변수를 가지고 있습니다. 이 모델은 더 큰 양의 텍스트 데이터를 기반으로 학습되었으며, 번역, 질문-답변, 요약 등과 같은 다양한 자연어 처리 작업을 인간 수준의 성능으로 수행할 수 있습니다.
④ GPT-3.5 / ChatGPT(2022)
ChatGPT는 GPT-3.5로도 알려져 있으며, GPT 모델의 약간 다른 버전입니다. 이는 대화형 AI 모델로, 질문에 답변하는 등 대화형 AI 관련 작업을 잘 수행하도록 최적화되어 있습니다. 때로는 정확하지 않은 답변을 제공하기도 합니다. ChatGPT는 대화형 데이터에 더 중점을 둔 작은 데이터셋에서 학습되었기 때문에, GPT-3보다 더 관련성 높고 문맥에 맞는 응답을 생성할 수 있습니다.
구글 바드(Bard)
2023년 2월 6일, 구글은 바드(Bard)라는 대화형 검색 방법을 발표했으며, 이어서 마이크로소프트는 ChatGPT를 빙(Bing)에 통합할 것이라고 발표했습니다. 미래의 검색 형태는 대화형이 될 것이며, 사람들은 전통적인 검색 엔진 최적화보다는 답변 엔진 최적화를 개선하려고 할 것입니다. OpenAI는 2023년 1분기에 GPT-4를 출시할 계획으로 끊임없이 진화하고 있습니다.
지금까지 지난 50 여 년 동안 NLP 기술의 발전을 돌아보며 최신 ChatGPT나 구글 바드까지 진화해 온 역사를 살펴보았습니다. ChatGPT가 나오기까지 NLP 기술은 수십 년 동안 여러 단계를 거치면서 각 알고리즘마다 단점을 지속적으로 보완해 왔습니다. 그 결과, ChatGPT처럼 인터넷 상의 거대한 데이터를 학습하여 인간에 가까운 답변을 제공하기에 이르렀습니다. 앞으로도 NLP기술은 더욱 발전할 것이고 수십 년 동안 사용했던 검색 방법은 지금보다 더욱 편한 형태로 바뀔 것이라고 봅니다. 놀라운 기술 발전이 가져다 주는 혜택을 보다 현명하게 활용하기 위해서는 이러한 검색 결과가 가져다 줄 오류와 편견을 판단할 수 있는 인간의 지혜가 그 어느 때보다 필요하다는 점도 중요하게 생각해야 할 것입니다.
*편집자 주: 위의 글은 SAS US Mary Osborn 님의 글을 참고하여 SAS KOREA 구방본 이사가 번역 및 작성한 것입니다. Original Article