지난 텍스트 분석 시리즈 2편에서는 보험사의 데이터를 이용하여 예측 모델을 개발하고, 모델의 성능을 개선하여 고객 행동에 대한 예측도를 높이는 방법을 살펴봤습니다. 이번에는 영화 리뷰 데이터를 사용하여 분류 규칙을 개발하는 과정을 SAS Visual Text Analytics를 중심으로 알아보겠습니다.

SAS Visual Text Analytics(이하, VTA)는 대용량의 비정형 데이터로부터 쉽게 인사이트를 추출할 수 있도록 설계된 솔루션입니다. SAS Viya 아키텍처에서 제공되며, 자연어 처리(NLP), 머신러닝, 언어 규칙 등의 기능이 포함되어 있습니다. 또한 전 세계 33 개 언어를 지원하며, 오픈소스를 포함한 다양한 프로그래밍 언어의 인터페이스를 지원하는 개방형 아키텍처를 가지고 있습니다.
SAS VTA에서는 LITI 규칙(language interpretation for textual information Rule)과 부울 규칙(Boolean Rule)을 사용하여 컨셉(Concept) 및 범주(Category) 규칙을 생성할 수 있습니다. 이 기능을 활용하여 분석가는 사용자 텍스트 모델(Customized Text Model)을 개발할 수 있습니다.
지금부터 제목, 리뷰, 등급(MPAA Ratings), 장르 정보를 포함한 1,527개의 영화 리뷰 데이터를 사용하여, 두개의 카테고리(어린이 영화, 스포츠 영화) 분류 규칙을 개발하는 과정을 보여드리겠습니다.
SAS VA를 이용한 텍스트 탐색
SAS VTA에 통합하여 제공하고 있는 SAS의 탐색 전용 솔루션인 SAS VA(Visual Analytics)를 통해 <그림1>과 같이 텍스트 데이터를 탐색할 수 있습니다. 사용자 옵션으로 토픽 개수를 7개로 선택했습니다.
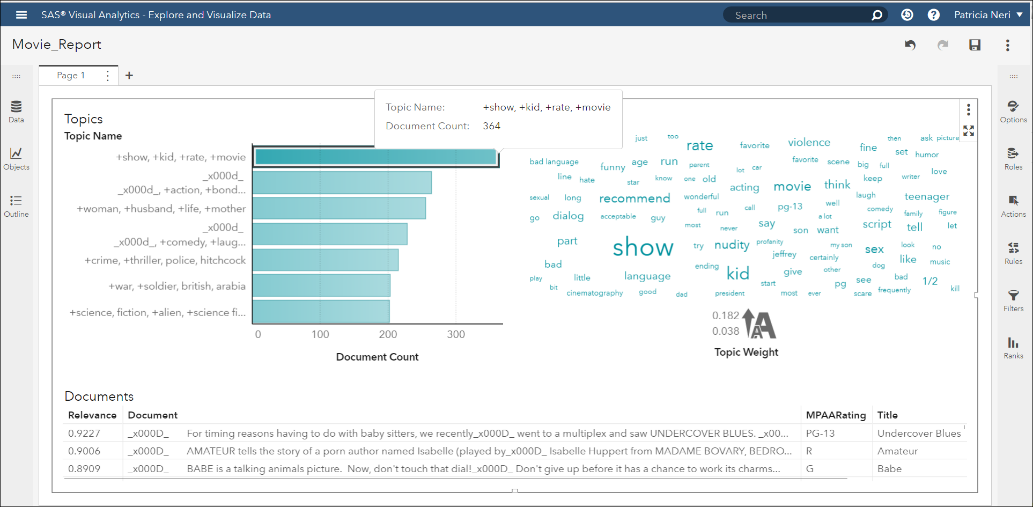
<그림1>은 전체 1,527개의 영화 리뷰 중에 ‘+ show, + kid, + rate, + movie’라는 토픽에 포함되는 영화가 364 개라는 것을 보여줍니다. 이는 첫 번째 카테고리인 어린이 영화를 분류하는 기준을 만드는데 참고할 수 있는 정보입니다. 두 번째 카테고리인 스포츠 영화에 대한 토픽은 분류되지 않은 것을 확인할 수 있습니다.
VTA Project 생성하기
파이프 라인은 VTA에서 각 분석 노드를 이용하여 텍스트 분석 프로세스의 작업을 진행하는 프로세스 흐름도 형식의 작업 단위입니다.

<그림2>는 데이터 탭에서 데이터 역할 설정 내역을 보여줍니다. 각 문서에 대한 고유 행 식별자가 있고, 분석할 텍스트 변수명은 ‘Review’이며, 범주로 MPAARating과 mainGenre라는 두 가지 변수가 사용됩니다. 나중에 VTA는이 두 변수를 사용하여 범주와 부울 규칙을 자동으로 생성합니다. ‘Title’ 변수는 분석을 위한 역할은 없지만 데이터 파악을 용이하게 하기 위해 표시(Display)했습니다.
영화는 mainGenre에 따라 분류되어 있으며, VTA가 해당 장르 카테고리에 대해 자동으로 생성하는 부울 규칙을 확인하고, 해당 규칙을 개선하는 방식과 새로운 카테고리를 만들어 보고자 합니다. 예를 들면 다음과 같습니다.
- 폭력이 포함되지 않은 어린이 영화 분류
- 스포츠와 관련된 영화 분류
- 내가 좋아하는 영화 분류
- 내가 좋아하는 감독을 언급한 리뷰 분류
개발방법
파이프 라인을 실행하여 첫 번째는 컨셉 노드에서 작업을 수행합니다. 목표는 '스포츠', '애니메이션', '가족' 장르와 관련된 규칙을 찾고, 이러한 규칙과 일치하는 영화를 확인하는 것입니다. 두 번째 파이프 라인에서는 첫 번째 파이프 라인에서 자동으로 생성되는 기본 분류를 개선하기 위한 목적으로 LITI 및 부울 규칙을 수정합니다.
다음 섹션에서는 새로운 카테고리가 어떻게 만들어지는지 보겠습니다. 이를 통해 실제 비즈니스 상황에서 사전 정의된 카테고리를 사용할 수 있고, 다른 경우에는 많은 문서를 분석한 후 비즈니스 목표를 충족하는 카테고리를 찾을 수 있다는 점도 확인해보겠습니다.
컨셉 노드에서 사용자 컨셉 개발
두 번째 파이프 라인에서는 세 개의 사용자 정의 컨셉을 개발했으며, 그 중 하나를 ‘MySports’를 사용하여 나중에 카테고리로 지정하여 카테고리 분류 룰을 개발해보겠습니다. 기본 부울 연산자는 새로운 컨셉과 카테고리 정의에 사용됩니다. AND/NOT 연산자는 전체 문서에 적용됩니다. 동일한 문장(SENT), 동일한 단락(PARA) 또는 여러 용어 내에서 거리(DIST)를 검색하는 다른 연산자가 있습니다.
▶ MySports Concept 생성
아래 규칙은 98 개의 문서와 일치하는 컨셉 규칙이며, 대부분은 스포츠 영화와 관련이 있고 오 탐지가 거의 없습니다. 이 규칙은 sport, baseball, tennis, football, basketball, racetrack이라는 용어가 문서(영화 리뷰)의 아무 곳에나 표시되지만 gambling, buddy 또는 sporting이란 용어가 문서의 어디에도 나타나지 않는 경우 문서를 추출합니다.

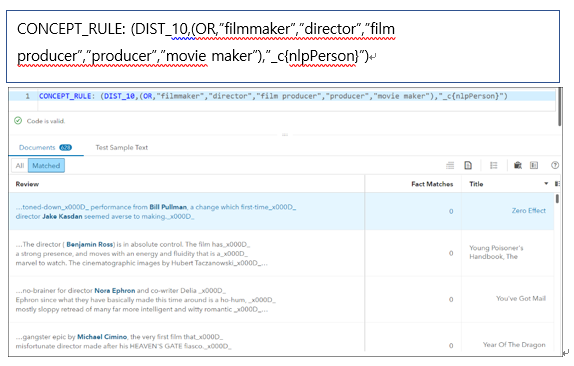
▶ filmmakersInReview 컨셉 생성
이 컨셉은 사전에 정의된 컨셉(이 경우, nlpPerson)을 사용하는 방법을 설명하기 위해 아래 <그림3>과 같이 작성했습니다.
▶ favoriteMovies Concept 생성
제가 가장 좋아하는 영화 한 편과 제가 가장 좋아하는 감독이 포함되는 리뷰를 찾아내는 컨셉을 만들었습니다. 첫 번째 CONCEPT_RULE은 동일한 문장에 Stanley Kubrick 및 2001이라는 용어가 포함된 문서를 추출합니다. 두 번째 CONCEPT_RULE은 문서의 어느 위치 에나 두 용어가 포함된 문서를 추출합니다. 두 CONCEPT_RULE 모두 첫 번째 용어 ‘Stanley Kubrick’만 추출합니다. 아래와 같습니다.

▶ Parsing Text Node에서 생성된 컨셉 확인
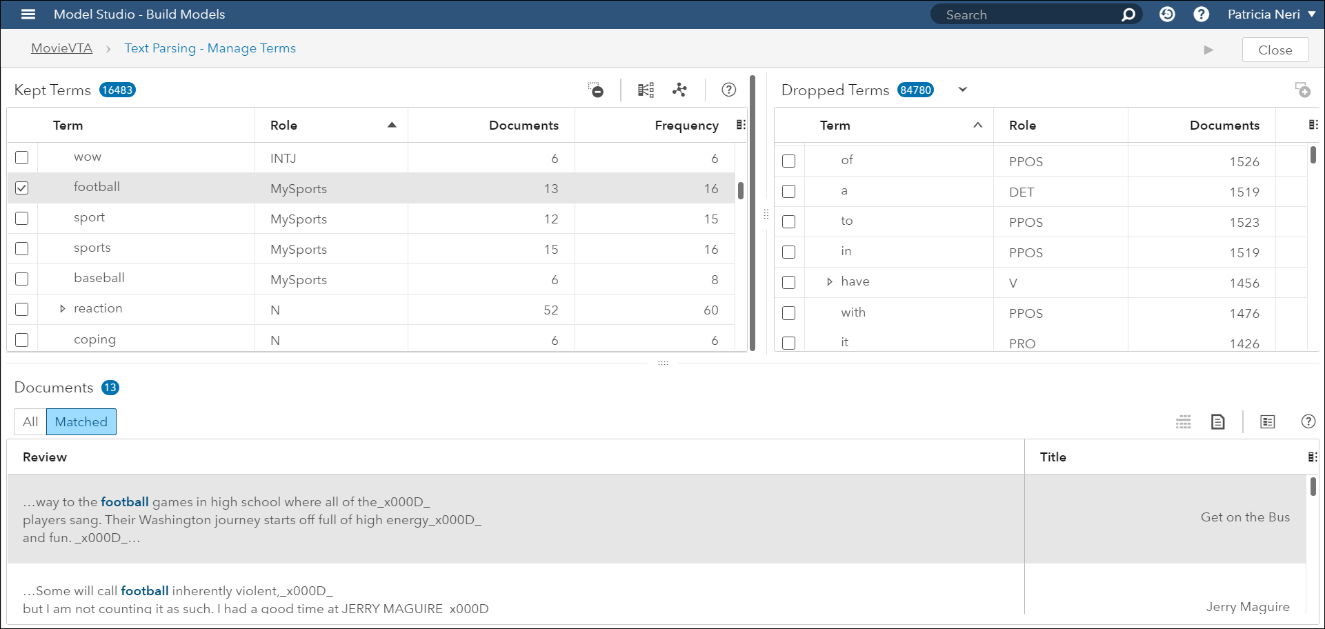
컨셉 노드에서 개발된 사용자 컨셉은 텍스트 파싱 노드로 전달됩니다. 유지한 용어(Kept terms) 창에서 football, sport, sports, baseball에 해당하는 단어들의 Role이 MySports로 매핑되어 있음을 <그림4>에서 확인할 수 있습니다.
카테고리 노드에서 사용자 카테고리 개발
두 번째 파이프 라인에서는 ‘스포츠’, ‘애니메이션’, ‘가족’ 장르와 관련된 규칙을 시작점으로 사용하여 새로운 카테고리를 개발했습니다.
▶ Sports Category
입력 데이터에는 스포츠 카테고리에 영화가 3개여서 의미 있는 규칙을 생성하기가 어렵습니다. 첫 번째 파이프 라인이 실행되면 원본 영화 3편을 포함한 총 8편과 스포츠와 관련 없는 영화 5편이 있습니다. 자동으로 생성된 규칙은 다음과 같습니다
|
추가적으로 컨셉 노드에서 개발된 MySports 규칙 Categories 노드의 카테고리 룰에 반영했습니다.
|
새로운 규칙은 90편의 영화와 일치하며 대부분은 스포츠와 관련이 있습니다. 다음 반복에서는 스포츠와 관련이 없는 영화, 스포츠와 관련이 있지만 일치하지 않는 영화를 보고 위의 규칙을 개선했습니다.
▶ ChildrenMovies Category 개발
첫 번째 파이프 라인에서 자동으로 생성된 Family장르와 Animation장르 카테고리의 규칙을 결합했습니다. Family장르 카테고리의 경우, 이 규칙과 일치하는 영화가 6 개 있습니다.
|
‘People vs Larry Flynt’이라는 영화와 일치하여 컨셉 규칙에서 ‘murder’과 ‘obscenity’라는 용어를 사용했습니다.
애니메이션 카테고리에는 66개의 일치되는 영화가 있으며 자동으로 생성된 규칙은 다음과 같습니다.

자동으로 생성된 위의 규칙의 정확도를 높이기 위해 아래와 같은 새로운 규칙을 개발했습니다.

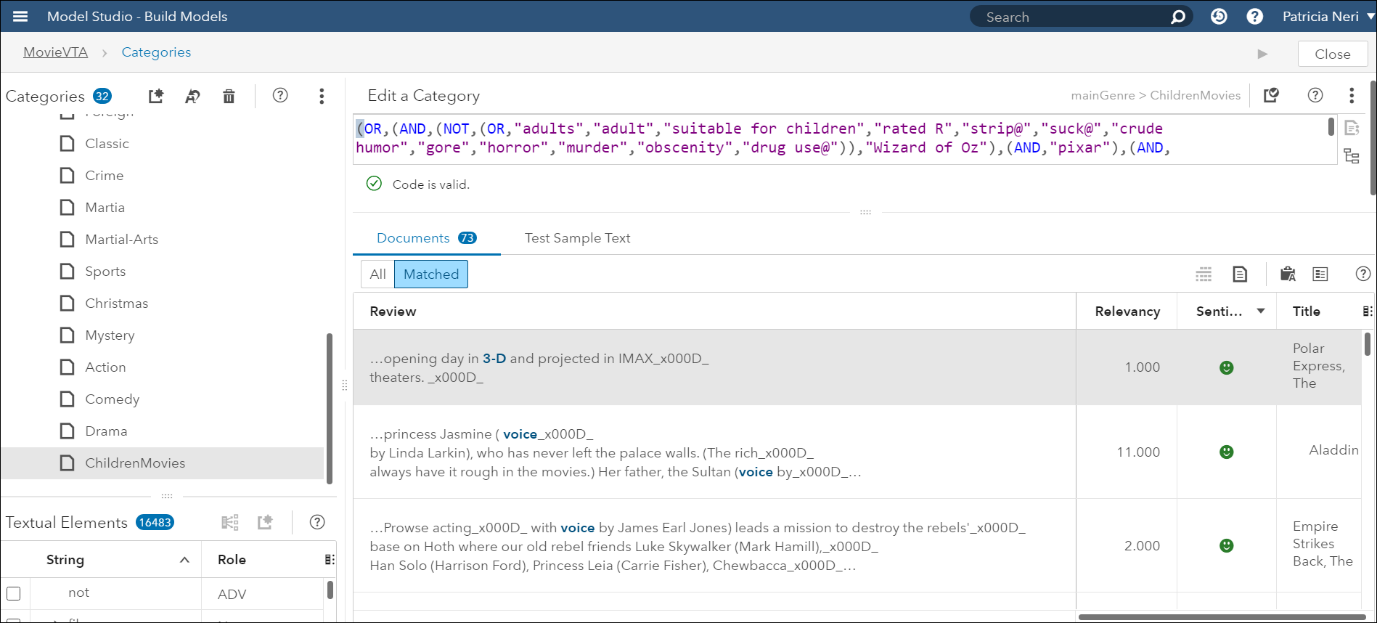
이로 인해 73 편의 영화가 분류되었으며 ‘R’등급(성인 등급)은 2개뿐입니다. 따라서 이 규칙을 이용하여 애니메이션과 가족 카테고리를 모두 제거하고, 새로운 카테고리 childrenMovies를 <그림5>와 같이 만들었습니다.
이와 같이 텍스트 모델을 생성할 때는 항상 새 규칙이 이전 규칙보다 개선되었는지 확인합니다. 또한 새 규칙이 얼마나 많은 참 양성(true positives)과 거짓 양성(false positives)이 일치하는지 확인하고, 필요한 정밀도(precision)를 얻을 때까지 프로세스를 반복해야 합니다.
여러 차례 반복하며 정밀도 개선
SAS VTA에서 자동으로 생성된 컨셉과 카테고리는 LITI 및 부울 규칙을 사용하여 수정하고 개선할 수 있으므로, VTA에서 우수한 성능의 사용자 모델을 개발할 수 있습니다. 모든 분석 프로젝트와 마찬가지로 텍스트 분석 프로젝트의 프로세스에서는 한번의 작업에서 찾은 통찰력이 이후 반복 작업에서 사용될 수 있도록 여러 차례 계속해서 분석해야 합니다. 언어 규칙과 관련한 새로운 규칙이 이전 작업에서 사용된 규칙보다 개선되었는지 확인하고, 필요한 정밀도(precision)를 얻을 때까지 이 과정을 반복해야 합니다.
지금까지 텍스트 데이터에서 인사이트를 얻는 주요 방법과 이를 위한 SAS 솔루션을 텍스트 분석 시리즈로 소개해 드렸습니다. 인류가 생성하는 가장 큰 데이터인 비정형 텍스트 데이터 분석을 통해 더 나은 비즈니스 결정을 내릴 수 있는 인사이트를 확보하시기 바랍니다.
SAS VTA 관련 내용은 홈페이지를 통해서 더 자세히 알아보십시오.






