딥 러닝은 인공 지능과 함께 유비쿼터스가 된 머신 러닝의 한 영역입니다. 딥 러닝 모델의 복잡하고 뇌와 유사한 구조는 대량의 데이터에서 복잡한 패턴을 찾는 데 사용됩니다. 이러한 모델은 일반 지도 학습 모델, 시계열, 음성 인식, 객체 탐지 및 분류, 감성 분석의 성능을 크게 향상시켰습니다. 사전 정의된 방정식을 실행하도록 데이터를 구성하는 대신 딥 러닝은 데이터에 대한 기본 매개 변수를 설정하고 신경망의 여러 처리 계층을 사용하여 패턴을 인식하여 컴퓨터가 스스로 학습하도록 학습시킵니다.
SAS는 딥 러닝과 관련하여 잘 설계되고 고유한 기능을 풍부히 제공합니다. 이번 블로그 시리즈를 통해 SAS Visual Data Mining and Machine Learning을 활용한 딥 러닝 모델 생성에 대한 내용을 2편으로- (1)기본 심층 신경망(DNN) 모델 아키텍처와 배치 정규화를 사용한 DNN 모델 구축 (2) 하이퍼파라미터 튜닝과 새로운 데이터 스코어링- 소개합니다. 사용된 예제 스크립트를 직접 실행해 결과를 확인할 수 있습니다.

SAS에서 제공하는 풍부한 딥 러닝 기능은 Python, R, Java, Lua 및 SAS를 비롯한 다양한 프로그래밍 언어와 REST API를 통해 사용할 수 있습니다. SAS에서 제공하는 딥 러닝 모델은 크게 다음과 같습니다.
1) 심층 신경망 (Deep Neural Networks, DNN)
2) 컨볼루션 신경망 (Convolutional Neural Networks, CNN)
3) 순환 신경망 Recurrent Neural Networks, RNN)
4) LSTM (Long Short-Term Memory)
5) GRU (Gated Recurrent Unit)
각 모델에는 고유한 기능이 있는데 이번 블로그 칼럼에서는 이중 가장 기본이 되는 심층 신경망을 SAS 언어를 사용하여 학습하고 SAS가 지원하는 다양한 유형의 모델링 기법을 예제를 통하여 설명할 것입니다.
신경망 내 은닉 계층의 수가 증가함에 따라 딥(deep) 네트워크가 형성됩니다. 기존 신경망에는 2 ~ 3 개의 은닉 계층을 포함하는 반면, 심층 신경망에는 100개 이상 다수의 은닉 계층이 포함될 수 있습니다.
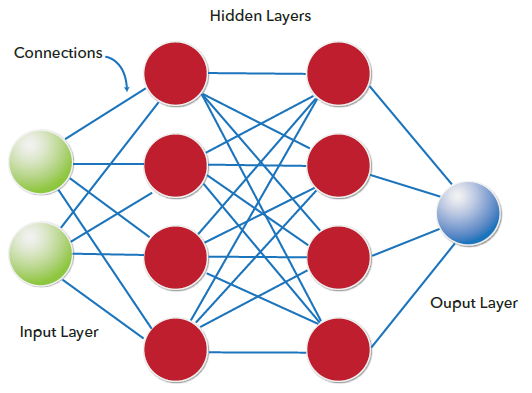
다음에 사용된 예제에서는 CAS 프로시저를 사용하여 호출되는 SAS CASL (Cloud Analytic Services Language)을 사용합니다. CASL은 생소해 보일 수 있지만 실제로 언어를 배우고 사용하기 쉽습니다.
첫 번째 예에서는 가장 기본적인 딥 러닝 모델 유형인 심층 신경망을 학습하고, 두 번째 예에서는 배치 정규화(batch normalization)를 사용하여 동일한 심층 신경망을 학습한 후 결과를 비교합니다.
예제 1: 기본 심층신경망(DNN) 모델 아키텍처
이 예제에서는 딥 러닝 모델 아키텍처를 처음부터 수동으로 구축하는 방법을 설명합니다. 우선 CAS (Cloud Analytic Services) 세션을 시작하고 라이브러리 mycaslib을 할당합니다. 이후 분석에 사용할 SASHELP.BASEBALL 데이터셋을 메모리 내 테이블로 로드한 다음 모델링을 위해 학습용 데이터와 검증용 데이터로 분할합니다.
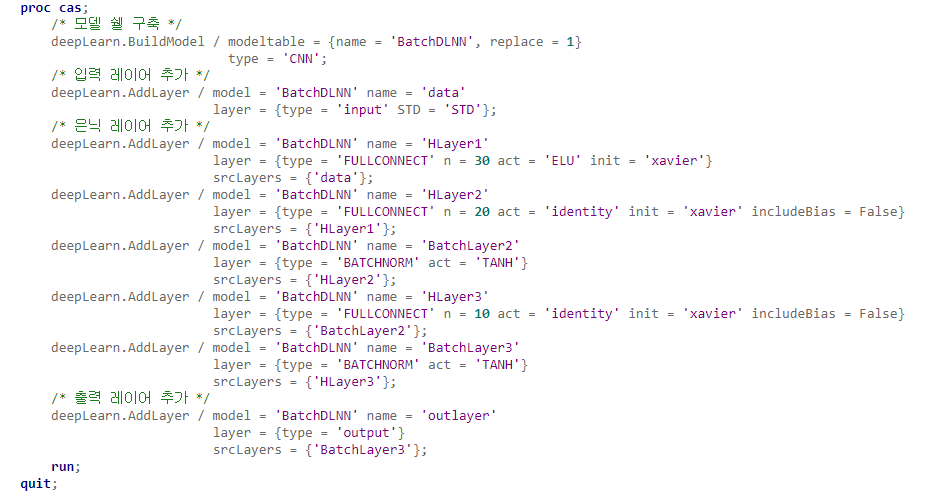
다음으로 PROC CAS를 사용하여 CAS 액션을 호출합니다. 우선 딥 러닝 액션셋인 deepLearn을 로드하고 이후 단계에서는 이 액션셋에 있는 다양한 액션들을 사용할 것입니다. 먼저 비어 있는 심층 신경망을 생성한 다음 이 모델에 각 계층(layer)을 추가하여 네트워크 아키텍처를 정의합니다. 계층을 추가할 때마다 해당 계층의 이름과 유형을 지정하고 이 계층을 추가할 모델의 이름도 지정합니다. 활성화 함수(activation function)나 은닉 유닛의 수와 같은 계층과 관련된 하이퍼파라미터를 지정할 수도 있습니다.
예제 2: 배치 정규화를 사용하는 DNN 모델 구축
이 예에서는 배치 정규화 계층을 포함하는 심층 신경망을 생성합니다. 배치 정규화 계층을 사용하려면 buildModel 액션에서 모델 유형을 CNN (convolutional neural networks)으로 지정해야 합니다. 참고로 CNN은 이미지 분류 모델을 구축하는데 사용되는 유형이지만 완전 연결(fully connected) 계층도 지원하므로 DNN 모델 구축에도 사용될 수 있습니다.
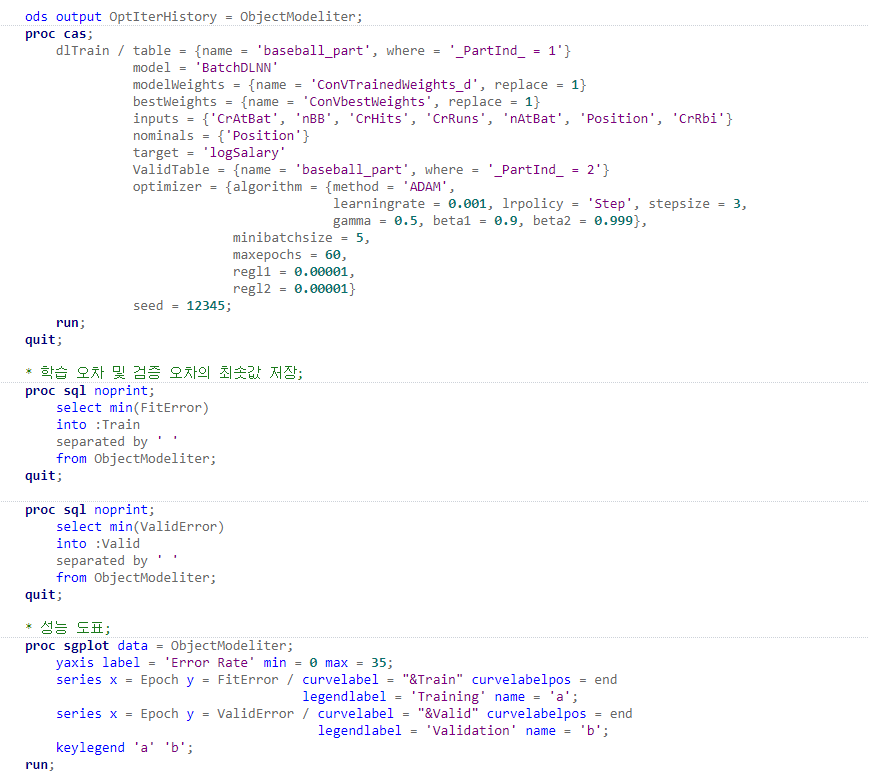
일단 데이터가 업로드되고 모델이 정의되면 모델 학습을 시작할 수 있습니다. 다음 프로그램 코드는 dlTrain 액션을 사용하여 모델을 학습시키고 여러 반복에 걸친 모델 적합 오차 도표를 생성합니다. 또한 학습용과 검증용으로 파티션 된 각 데이터셋에 대하여 가장 작은 오차를 그래프 위에 표시합니다.
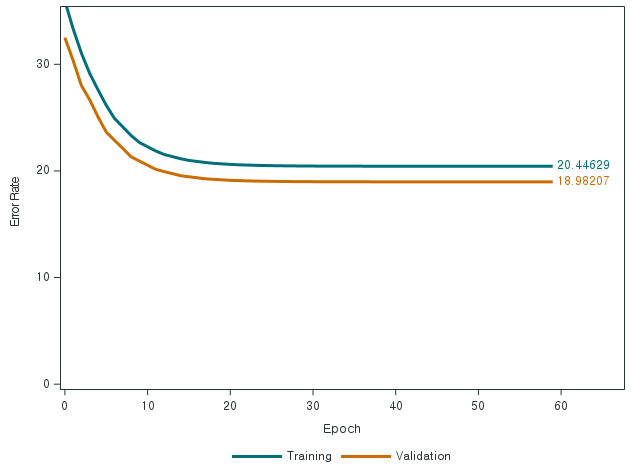
다음 시리즈에서는 딥 러닝 성능을 개선할 수 있는 하이퍼파라미터를 조정에 대해 소개할 예정입니다.





