
그 동안 머신러닝 해석력 시리즈를 통해서 머신러닝의 부분 의존성(PD; Partial Dependence), 데이터 세트 해석 등을 소개해드렸는데요. 오늘은 라임(LIME; Local Interpretable Model-Agnostic Explanation)을 통해 머신러닝 모델의 해석력을 개선할 수 있는 방법에 대해서 알아보겠습니다. 머신러닝 모델 해석력 시리즈 1탄, 2탄, 3탄을 놓치셨다면 아래 링크를 통해 확인해주세요!
- 머신러닝 해석력 시리즈 1탄: 인공지능(AI)과 머신러닝을 신뢰하기 위한 필수 조건, 해석력!
- 머신러닝 해석력 시리즈 2탄: 데이터 세트를 이해하고 해석하는 방법
- 머신러닝 해석력 시리즈 3탄: 부분의존성(PD) & 개별조건부기대치(ICE) 플롯 정복하기!
머신러닝에는 의사결정 트리(Decision Tree)와 같은 투명한 머신러닝 모델도 있지만, 오늘날 사용되는 대다수의 모델은 심층신경망(Deep Neural Networks), 랜덤 포리스트(Forest), 그래디언트 부스팅(Gradient Boosting) 머신 및 앙상블 모델과 같은 블랙 박스 모델입니다.
머신러닝 모델의 해석력은 모델 행동을 통해 인사이트를 얻을 수 있도록 돕는 필수적인 요소인데요. 라임(LIME; Local Interpretable Model-Agnostic Explanation)은 모든 예측 모델에 대한 결과를 해석 가능하고 신뢰할 수 있는 방법으로 설명하는 새로운 기법을 제공하는 알고리즘으로, 설명하고 싶은 예측 값 근처에 대해서만 해석 가능한 모델을 학습시키는 방법입니다.
이러한 라임 알고리즘을 처음 개발한 사람은 마르코 툴리오 히베이루(Marco Tulio Ribeiro)와 사미르 싱(Sameer Singh), 카를로스 게스트린(Carlos Guestrin)인데요. 라임 기법은 세 사람의 논문에 자세히 설명되어 있습니다. 논문에 나온 예시를 통해 라임과 그 작동 원리에 대해 더욱 구체적으로 소개해드리겠습니다.
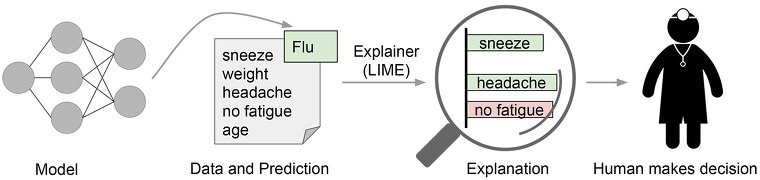
위 그림에 나와있는 첫 번째 예시는 특정 환자가 독감에 걸렸는지 예측하는 모델을 도표화한 이미지입니다. 이 예측 결과는 '설명자(Explainer)'에 의해 설명되는데요, '설명자'는 모델에서 가장 중요한 몇 가지 증상을 강조해 알려줍니다. 이를 통해 의사가 이해할 수 있는 설명이 제공된다면 의사는 모델의 도움을 받아 더 나은 결정을 내릴 수 있습니다.
이 예시에서 해석은 상대적 가중치를 가지는 짧은 목록입니다. 증상들은 예측 값에 기여하는 것이거나(녹색, 양의 가중치) 그것에 반하는(빨간색, 음의 가중치) 것일 수 있습니다.
해석력의 범위
아래와 같이 확연히 구별되는 두 유형의 해석력을 살펴보면 라임의 작동 원리를 더욱 쉽게 이해할 수 있습니다.
글로벌 해석력(Global Interpretability)은 학습된 반응 함수에 의해 모형화 된 조건분포 전체를 이해하는데 도움을 줍니다. 하지만 이 해석은 대략적이거나 평균값에 근거할 수 있습니다. 한편 로컬 해석력(Local Interpretability)은 단일 데이터 포인트나 분포의 작은 영역에 대한 이해를 돕는데요. 한 그룹의 입력 레코드와 이에 상응하는 예측, 또는 10분위수의 예측과 이에 상응하는 입력 행 값에 대한 것일 수 있습니다. 조건분포의 작은 영역은 선형일 가능성이 더 높기 때문에 로컬 설명은 글로벌 설명보다 정확도가 더 높을 수 있습니다.
라임은 로컬 해석력을 제공하도록 설계되었기 때문에 특정 결정이나 결과에 가장 정확합니다.
라임의 직관력
설명자는 모델에 구애받지 않고 로컬 영역에서 신뢰할 수 있어야 합니다. 특히 로컬 영역에서 신뢰할 수 있는 설명은 설명할 인스턴스의 근처에서 분류기(Classifier) 행동을 포착하는데요. 라임은 로컬 설명을 학습하기 위해 분류기의 결정 경계(Decision Boundary)를 해석 가능한 모델을 이용해 근사합니다.
이처럼 라임은 모델에 영향을 받지 않기 때문에 모델 행동에 대한 어떤 가정도 하지 않습니다. 따라서 라임은 어떤 예측 모델에든지 적용할 수 있습니다.
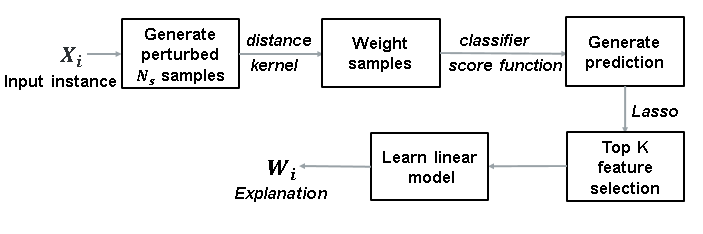
라임은 기본 모델의 행동을 학습하기 위해 입력 값을 교란(Perturb)해 예측이 어떻게 바뀌는지 확인합니다. 라임의 핵심 직관력은 단일의 글로벌 모델보다 단순한 로컬 모델을 통해 블랙 박스 모델을 근사하는 것이 훨씬 쉽다는 것인데요. 이는 교란된 샘플 인스턴스에 대해 설명하고 싶어하는 인스턴스와의 유사성만큼 가중치를 주고, K개의 피처를 선택하기 위해 라소(Lasso) 모델을 적합한 후, 선형 회귀를 통해 이들의 계수를 학습함으로써 가능합니다.
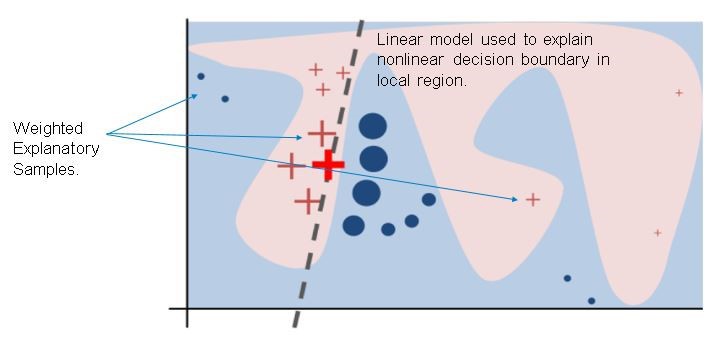
그림 2는 히베이루와 싱, 게스트린이 작성한 논문 에서 발췌된 예시인데요. 라임이 알지 못하는 블랙 박스 모델의 복잡한 훈련 함수 f는 선형 모델이 제대로 근사할 수 없는 파란색 및 분홍색 배경으로 표현됩니다. 굵은 붉은색 십자가는 설명되고 있는 인스턴스를 나타냅니다. 라임은 인스턴스를 샘플링하고, f를 이용해 예측을 얻으며, 설명될 인스턴스와의 근접성에 따라 가중치(여기서는 점과 십자가의 크기로 표현된)를 부여합니다. 점선은 로컬영역 에서 신뢰할 수 있는 학습된 설명을 나타냅니다.
SAS로 라임 활용하기
아래 도표는 SAS 비주얼 데이터 마이닝 앤드 머신러닝(SAS Visual Data Mining and Machine Learning)과 함께 실행한 라임 기법의 일반적 단계를 나타내는데요. 이때 입력 값은 설명을 제공하고자 하는 어떤 관측 값이든 될 수 있습니다. SAS의 모델 스튜디오(Model Studio) 애플리케이션 최신 버전에서는 훈련용 데이터로부터 클러스터가 생성되고 클러스터 중심은 이러한 클러스터에 대한 로컬 모델 설명을 제공하기 위해 사용됩니다. 새로운 관측 값의 경우, 설명은 가장 밀접하게 연관되어 있는 클러스터에 대한 설명에 기여할 수 있습니다. 향후 출시될 버전에서는 개별 관측값에 대한 설명을 생성할 수 있도록 CAS 액션(CAS action)이 제공될 예정입니다.
라임의 이미지 예시 이미지
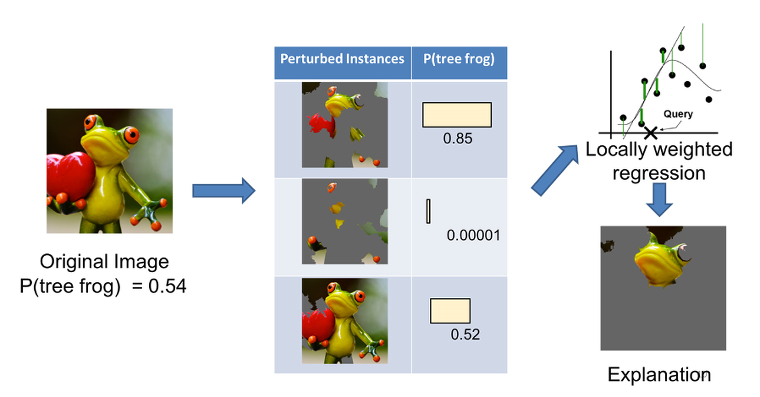
그림 4는 라임이 이미지 분류에서 어떻게 작동되는지 설명하는 유명한 예시인데요. 여기서 이미지가 청개구리를 포함할 가능성을 예측하는 분류기를 설명해드리겠습니다.
각 이미지에서 해석 가능한 픽셀 일부를 회색으로 가리면 교란된 인스턴스의 데이터 세트가 생성됩니다. 라임은 예측이 설명될 이미지를 가지고 교란된 인스턴스 집합을 생성합니다. 이후 각 교란된 인스턴스에 청개구리가 있는지에 대한 예측은 블랙 박스 모델을 통해 산출됩니다.
블랙 박스 모델의 예측을 타깃으로 이용해 교란된 인스턴스에서 가중치가 부여된 라소 회귀가 실행되는데요. 이때 이 예시에서 피쳐는 픽셀입니다. 라소는 이들 중 K개를 선택합니다. 이렇게 선택된 피쳐는 가중치가 부여된 단순한 선형 회귀에서 동일한 인스턴스, 가중치 및 타깃에 대해 사용됩니다. 마지막에는 가장 높은 양의 계수를 가지는 픽셀이 설명 역할을 합니다. 설명은 설명에 사용되지 않는 픽셀을 회색으로 표시한 원본 이미지를 보여주며 제공됩니다. 마지막에는 가장 높은 양성 계수를 가진 픽셀이 설명 역할을 합니다. 설명은 설명되지 않는 픽셀을 회색으로 표시한 원본 이미지를 보여주며 제공됩니다.
이 예시는 오라일리(O’Reilly)에서 발행한 마르코 툴리오 히베이루(Marco Tulio Ribeiro), 사미르 싱(Sameer Singh), 카를로스 게스트린(Carlos Guestrin)가 쓴 '라임 개론(Introduction to Local Interpretable Model-Agnostic Explanations (LIME)’ 기사에서 발췌했습니다.
SAS 플랫폼에서 활용된 라임 활용 사례 살펴보기
이제 두 개의 간단한 사용 사례를 통해 SAS 모델에서 라임이 어떻게 활용되고 라임이 어떻게 모델의 해석력을 어떻게 개선하는지 말씀드릴 텐데요.
당뇨병 모델
첫 번째 사례는 UCI 머신러닝 저장소(UCI Machine Learning Repository)에서 이용할 수 있는 아키멜 오담(Akimel O’otham)족의 당뇨병 데이터 세트를 이용하는데요. 이 데이터 세트는 이전에 피마 인디언(Pima Indian)으로 알려져 있던 유명한 데이터 세트입니다. 미국 애리조나주 피닉스 근처에 거주하는 아키멜 오담 족 중 21살 이상의 여성을 대상으로 세계보건기구(WHO) 기준에 따라 당뇨병 검사를 실시했습니다. 이 검사 데이터는 미국국립보건원 산하 당뇨·소화·신장질환연구소(NIDDK)에 의해 수집됐습니다.
SAS는 아래 변수와 768개의 관측 값으로 구성된 해당 데이터에 대해 SAS 신경망 모델을 훈련합니다.
- 바이너리 타깃(Binary Target): 당뇨병 발병
- 8개의 인터벌 피쳐(Interval Features): 임신 횟수, 혈장포도당, 확장기혈압, 삼두근 피부 주름 두께, 2시간 혈청 인슐린, 체질량지수, 당뇨병 병력 함수 및 나이
라임은 예측을 설명하기 위해 먼저 체질량 지수 33.6, 확장기 혈압 72, 삼두근 피부 주름 두께 35mm, 2시간 혈청 인슐린 0 mu U/ml, 혈장포도당 148, 임신 횟수 6번 및 당뇨병 병력 함수 0.627인 50세 여성 당뇨병 환자를 살펴보는데요. 신경망 모델은 이 환자가 당뇨병에 걸릴 확률을 60%로 예측합니다.

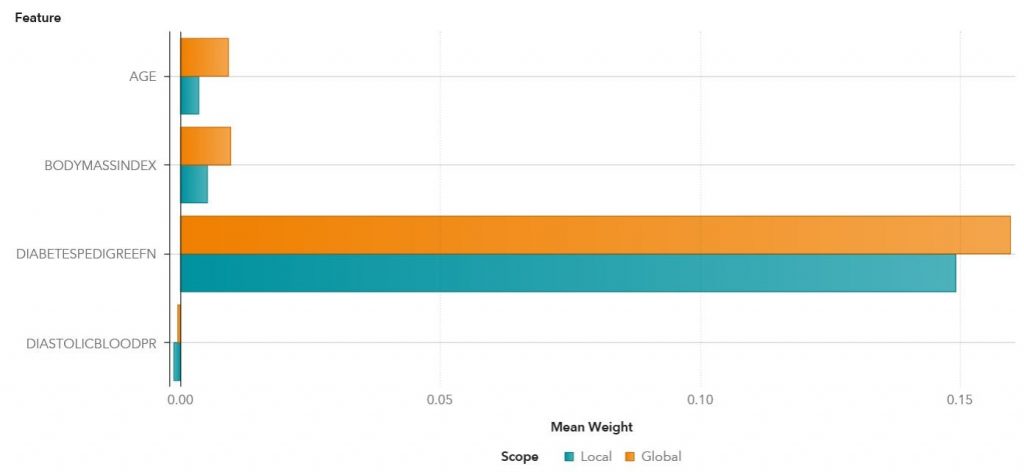
위 그림은 당뇨병 모델에 대한 로컬 설명과 글로벌 설명을 비교합니다. 나이, 체질량 지수 및 당뇨병 병력 함수는 로컬 및 글로벌 설명 모두에서 당뇨병 발병 확률 증가와 선형적으로 연관돼 있습니다. 당뇨병 병력 함수는 가장 영향력 있는 요인인데요. 당뇨병 병력 함수 측정값이 1 유닛(unit)씩 증가할 때, 당뇨병이 있는 환자를 예측할 수 있는 확률은 로컬 설명에서는 15%, 글로벌 설명에서는 16%씩 증가합니다.
NBA 선수 모델
두 번째 사례는 스포츠레이더 US(Sportradar US LLC)가 제공하는 NBA 박스스코어 선수 통계(NBA Box Score Players Stats)를 활용하는데요. SAS는 아래를 포함해 17만 4천여개의 기록으로 구성된 데이터에서 SAS 그래디언트 부스팅 모델을 훈련합니다.
- 바이너리 타깃(Binary Target): 슛 성공 여부
- 8개의 인터벌 입력 값(Interval Inputs): 나이, 인치 단위의 신장, 분 단위의 슈팅 후 남은 시간, 쿼터, 초 단위의 슈팅 후 남은 시간, 슛 거리, 파운드 단위의 몸무게, 경력 년수 3개의 명목형 입력 값(nominal inputs): 포지션, 슛을 시도한 위치, 슛을 시도한 위치와 림까지의 거리
이 사례는 나이 40세, 신장 83인치, 몸무게 250파운드, 슛 성공 여부=1, 센터 포워드 포지션, 슛을 시도한 위치는 센터, 슛을 시도한 위치와 림까지의 거리 8피트 미만인 선수 ID 1495의 예측을 사용했습니다. 이 선수는 슛에 성공했고, 슛 성공 여부1은 0.6557입니다.
이제 NBA 선수 모델에 대한 로컬 설명과 글로벌 설명을 비교해보겠습니다.

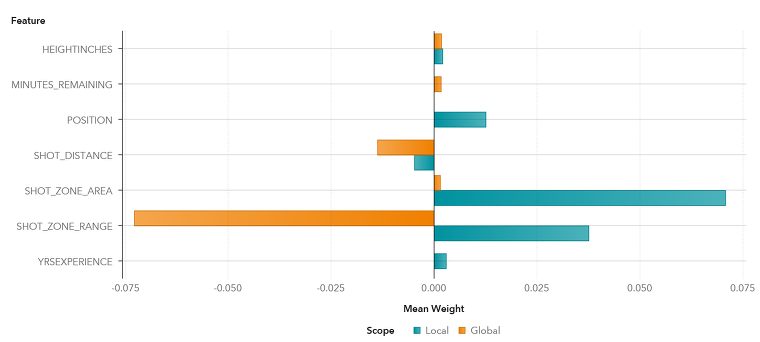
신장이 83인치인 선수의 신장이 1인치 증가한다면 슛 성공 여부1의 확률은 0.21% 증가하는데요. 이는 전체 증가율인 0.18%과 비슷합니다. 18년 경력을 가진 선수의 경력이 1년씩 증가할수록 슛 성공 여부1 확률은 0.3% 증가합니다. 하지만 경력 년수는 글로벌 모델에서 선택된 상위 5개의 피쳐에 포함되지 않습니다.
포지션, 슛을 시도한 위치, 슛을 시도한 위치와 림까지의 거리 등과 같은 다른 피쳐들은 명목형 피쳐입니다. 이 선수의 경우, 센터에서 슛을 시도했을 때 슛 성공 여부1의 확률이 백코트에서 시도했을 때보다 7.1% 더 높습니다. 반면 글로벌 설명에서는 단 0.15%만 증가하는 다소 적은 차이가 나타났습니다.
슛을 시도한 위치와 림까지의 거리의 경우, 슛을 시도한 위치와 림까지의 거리가 8피트 미만일 때 슛 성공 여부1의 확률은 16~24 피트일 때보다 3.76% 증가하는데요. 이와 반대로 글로벌 설명에서의 차이는 7.28% 감소했습니다.
SAS는 분석의 모든 프로세스를 표준화하고, 다양하고 검증된 머신러닝 알고리즘을 적용해 비즈니스 고민을 쉽게 해결할 수 있도록 돕고 있습니다. 앞으로도 라임을 비롯한 다양한 머신러닝 알고리즘 등을 통해 해석력을 높일 수 있는 다양한 정보를 공유해드릴 예정이니 많은 기대 부탁 드립니다!






