
“모델링에 뛰어들기 전에 먼저 데이터를 이해하고 탐색하라!”
데이터 과학자를 위한 일반적인 조언입니다. 데이터 세트가 정리되어 있지 않으면 모델을 구축해도 문제를 해결하는 데 도움이 되지 않습니다. 마치 쓰레기를 꺼냈다, 넣었다 하는 것과 같죠. 강력한 머신러닝 시스템을 구축하기 위해서는 예측 작업을 정의하고, 문제를 해결하기 전에 데이터 세트를 탐색하고 이해해야 합니다.
데이터 과학자는 대부분의 시간을 모델링을 위한 데이터의 탐색, 정리, 준비 과정에 씁니다. 이를 통해 정확한 모델을 구축하고, 해당 모델에 적합한 가정을 확인할 수 있습니다.
데이터를 관찰하려면 어떻게 해야 할까요?
- 데이터가 수백만 개의 관측값들로 구성되어 있으면 모두 확인할 수 없습니다. 그렇다고 첫 100개의 관측값이나 임의로 고른 100개의 관측값 만으로 결론을 내릴 수도 없죠.
- 데이터가 수천 개의 변수로 구성되어 있으면 모든 변수에 대해 통계를 작성할 수 없습니다.
- 데이터가 이질적인 변수로 구성됐다면 모든 변수를 동일한 방식으로 처리할 수 없습니다.
그 대신! 다양한 탐색적 데이터 분석과 시각화 기법을 이용해 데이터 세트에 대한 이해를 높일 수 있습니다. 여기에는 데이터 세트의 주요 특징을 요약하고, 데이터 세트의 대표적이거나 중요한 포인트를 찾고, 데이터 세트에서 관련 특성 (feature)을 찾는 작업이 포함됩니다. 데이터 세트를 전반적으로 이해한 후에는 모델링 과정에 사용할 관측치와 특성를 고려해야 합니다.
오늘은 머신러닝 알고리즘 해석력 시리즈 2탄으로 데이터 세트를 이해하고 탐색하는 다양한 기법을 살펴보겠습니다. 1탄을 놓치셨다면 클릭!
시각화를 이용한 요약 통계
요약 통계를 사용해 데이터 세트의 연속(구간) 및 이산(명목) 변수를 이해할 수 있습니다. 이를 개별적으로 또는 통합적으로 분석할 수 있는데요. 예상치 못한 값(unexpected values), 결측치(missing values)의 비율, 왜도(skewness) 등 여러 가지 문제를 찾을 수 있습니다. 서로 다른 분포와 학습 및 테스트 데이터 세트의 통계를 비교할 수도 있죠. 요약 통계는 그 사이의 차이 값을 발견하는 데 유용합니다.
그렇지만 주의해야 할 점이 있습니다. 요약 통계를 과도하게 신뢰하면 데이터 세트의 문제를 발견하지 못할 수 있습니다. 추가 기법을 적용해 데이터 세트를 완전히 이해하는 것이 좋습니다.

예시 기반의 설명(Example-based explanations)
수천 개의 변수와 수백만 개의 관측치가 있는 데이터 세트를 수집했다고 가정해볼까요? 추상화 없이 데이터 세트를 이해하는 것은 매우 어려워집니다. 이 문제를 해결하기 위한 한 가지 방법은 예시 기반의 설명(example-based explanations)을 사용하는 것입니다. 이 기법으로 데이터를 이해하는 데 중요한 관측치와 차원을 선택할 수 있습니다. 또 서로 다른 분포를 통해 매우 복잡한 빅데이터 세트를 해석할 수 있습니다.
이 방법에는 데이터 세트 안의 그룹을 characterize, criticize, distinguish 위해 관측치와 차원을 찾는 것이 포함됩니다.
1. Characterize: 일반적으로 범주화와 의사결정을 위해 데이터의 대표적인 예시를 사용합니다. 이 대표적인 예시를 보통 프로토타입이라고 부르는데요. 프로토타입은 데이터 세트의 범주를 가장 잘 설명하는 관측치입니다. 특정 범주의 모든 관측치를 사용해 해석하기는 어렵기 때문에 범주를 해석하는 데 사용됩니다.
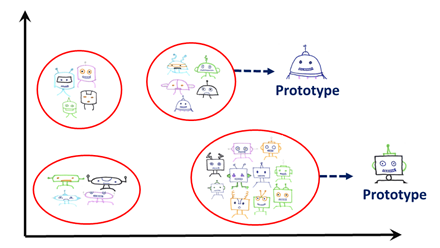
2. Criticize: 프로토타입을 찾는 것만으로는 데이터를 이해하기에 충분하지 않습니다. 지나친 일반화로 이어질 수 있기 때문인데요. 프로토타입으로 잡아내지 못한 특정 그룹이 공유하는 특성 간에는 변수가 존재합니다. 따라서 규칙에 예외(exceptions), 즉 criticisms을 적용해야 합니다. 이러한 관측치는 프로토타입과는 매우 다른 소수의 관측값(minority observations)으로 간주 될 수 있지만 여전히 동일한 카테고리에 속합니다.
예를 들어, 아래 그림에서 각 카테고리의 로봇 사진은 각기 다른 머리와 몸을 가진 로봇들로 구성되어 있습니다. 옷을 입은 로봇의 사진은 일반적인 로봇 사진과 매우 다를 수 있지만 같은 카테고리에 속할 수도 있습니다. 이러한 사진들은 의미 있는 소수이기 때문에 데이터를 이해하는 데 중요합니다.
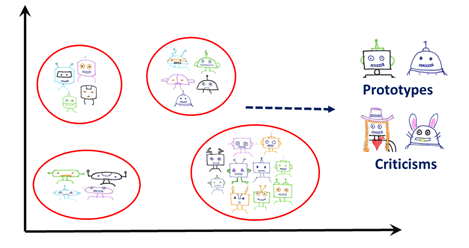
해당 분야에서 Been Kim의 연구는 최대 평균 불일치(MMD; maximum mean discrepancy) critic이라고 불리는 비지도(unsupervised) 학습기법을 이용해 프로토타입은 물론 이 같은 소수를 찾는 것에 집중합니다. 여기서 MMD는 전체 데이터 세트를 나타내기 위해 프로토타입을 선택합니다. 그런 다음 프로토타입이 나타내지 않는 데이터 세트의 일부분에서 criticisms을 선택합니다. 비평 포인트를 선택하는 동안 MMD critic는 이러한 포인트가 다양하고 프로토타입과 크게 다르다는 것을 확인합니다. 이 방법은 데이터 세트 전체를 특성화하기 위해 데이터에 적용할 수 있습니다. 다른 카테고리를 이해하기 위해 레이블되지 않은 데이터에도 적용할 수 있습니다.
3. Distinguish: 대표를 찾는 것으로는 항상 충분할 수 없습니다. 특성의 수가 많으면 선택된 관측치를 이해하는 것은 여전히 어렵습니다. 사람은 길고 복잡한 설명을 이해하기 힘들기 때문에 설명은 간단해야 합니다.
이런 경우, 선택한 관측치의 가장 중요한 특징을 살펴봐야 합니다. 부분 공간 묘사(Subspace representation)로 이 문제를 해결할 수 있는데요. 프로토타입과 부분 공간 묘사를 이용해 해석력을 높일 수 있습니다. 이때 베이지안 케이스 모델(BCM; Bayesian Case Model)을 이용할 수 있는데요. 비지도 학습 방법으로 기본 데이터는 혼합 모델(mixture model)과 각 클러스터에 중요한 특성 세트를 사용해 모델링됩니다.
중요한 특성을 이해하는 것 외에 감별 진단(differential diagnosis)과 같은 여러 애플리케이션을 위해 클러스터 사이의 차이를 이해하는 것도 중요합니다. 이를 위해서는 데이터의 차원을 식별해야 하는데요. MGM(mind the gap model)은 이를 달성하기 위해 추출 및 선택적 접근 방식을 결합합니다. 그리고 추가적인 데이터 탐색에 도움이 되도록 구별 가능한 차원(distinguishable dimensions)의 전체 세트(global set)를 보고합니다.
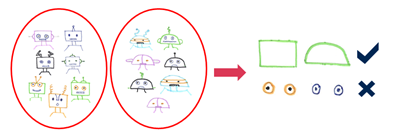
예를 들어, 위 그림의 서로 다른 로봇 사진에서 추출한 특성을 살펴보면 로봇의 머리 모양이 구별되는 차원임을 알 수 있습니다. 그렇지만 눈은 매우 비슷하게 생겼기 때문에 구별된다고 할 수 없겠죠.
임베딩 기법(Embedding techniques)
임베딩은 단어, 관측치와 같은 이산 값을 벡터로 매핑하는 것입니다. 다양한 임베딩 기법을 사용해 데이터 세트의 저차원 대표(lower-dimensional representation)를 시각화할 수 있습니다. 임베딩은 수백 가지의 차원이 될 수 있는데요. 이를 이해하는 일반적인 방법은 2, 3차원으로 투영하는 것으로 다음과 같은 다양한 경우에 유용합니다.
- 지역 인접성(local neighborhoods)을 탐색할 수 있습니다. 주어진 포인트에서 가장 가까운 포인트를 탐색해 해당 포인트들이 서로 연관되어 있는지 확인할 수 있습니다. 이러한 포인트들을 선택해 추가 분석을 하고 모델의 동작을 이해할 수도 있죠.
- 전체 구조(global structure)를 분석할 수 있습니다. 포인트 그룹을 찾을 수 있고, 데이터 세트에서 클러스터와 이상치를 찾을 수 있습니다.
임베딩 기법은 다음과 같은 여러 가지 방법으로 사용할 수 있습니다:
- 주성분 분석(PCA; Principal Component Analysis): 데이터의 차원수를 줄이기 위한 효과적인 알고리즘으로, 특히 변수 사이에 강력한 선형 관계가 존재하는 경우 유용합니다. 데이터 변동(data variation)을 가능한 한 적은 차수에서 포착하는 선형 결정론적 알고리즘(linear deterministic algorithm)입니다.
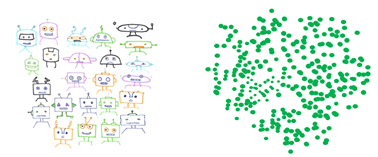
- 변동을 하이라이트하고 차원을 제거하는 데 사용할 수 있습니다. 데이터를 해석하려는 경우, 상당한 양의 변동을 고려한 몇 가지의 주성분을 유지할 수 있습니다. 나머지 주성분은 미세한 변화를 설명합니다. 그러므로 해석과 분석을 목적으로 보관해서는 안 됩니다.
- t-SNE(T-distributed stochastic neighbor embedding): t-SNE는 데이터에서 지역 인접성(local neighborhoods)을 보존하려고 시도하는 차원 축소 알고리즘(dimension reduction algorithm)입니다. 비선형적이며 비결정적(nondeterministic)인데요. 2D 또는 3D 투영을 계산할 때 이용할 수 있습니다. t-SNE는 다른 방법이 놓칠 수 있는 구조를 발견할 수 있습니다.
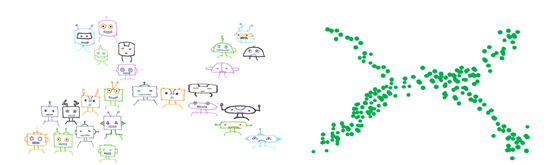
방법만 알고 있다면 데이터 세트를 시각화하고 해석하는 것은 매우 유용합니다. 하지만 조심해야 할 것들이 많이 있습니다. 지역 구조(local structure)를 유지하려다가 전체 구조(global structure)를 왜곡시킬 수 있기 때문입니다. t-SNE와 관련해 주의해야 할 것들은 distill.pub의 ‘t-SNE을 효과적으로 사용하는 방법(How to Use t-SNE Effectively)’이라는 훌륭한 기사를 참고해보세요.
t-SNE 임베딩을 사용하면 데이터의 차원을 줄이고 구조를 찾을 수 있습니다. 그러나 데이터 세트가 매우 큰 경우에는 구조를 파악하기가 여전히 어려울 수 있는데요. 데이터 세트에 대한 이해를 높이려면 데이터의 형상(geometry of the data)을 확인해보세요.
토폴로지 데이터 분석(TDA; Topological Data Analysis)
토폴로지는 개체를 분리하지 않고 변형시킬 때 보존된 기하학적 특성을 연구하는 분야입니다. 토폴로지 데이터 분석은 토폴로지를 이용해 데이터의 기하학적 특성을 연구하는 툴을 제공하는데요. 여기에는 특성을 탐지하고 시각화하는 것과 관련된 통계적 조치가 포함됩니다. 여기서 기하학적 특성은 데이터의 독자적인 클러스터(distinct clusters), 루프, tendrils로 분류될 수 있다. 네트워크에 루프가 있는 경우, 이 데이터 세트에 주기적으로 발생하는 패턴이 있다고 결론을 내릴 수 있습니다.
TDA의 매퍼(Mapper) 알고리즘은 데이터 시각화와 클러스터링에 매우 유용한데요. 노드가 비슷한 관측치 그룹인 데이터 세트의 토폴로지 네트워크를 구축하고, 노드가 공통적인 관측치를 갖는 경우 노드를 연결하는 엣지를 생성할 수 있습니다.
결론
데이터를 이해하고 해석하는 과정은 머신러닝 작업에서 매우 중요합니다. 데이터의 크기, 차원, 유형에 따라 알고리즘을 선택할 수 있습니다. 예를 들어, 원본 데이터가 크면 무작위 샘플 대신 대표적인 예시를 사용할 수 있습니다. 광범위한 데이터 세트를 보유하고 있는 경우 대표적인 샘플(representative samples)을 이해하는 데 중요한 차원을 찾을 수도 있습니다.
이처럼 서로 다른 기법을 이용해 데이터에 대한 다양한 인사이트를 얻고 머신러닝 알고리즘의 미스터리를 풀 수 있습니다. 머신러닝 해석력에 대한 블로그 1탄에 이어 2탄을 소개해드렸습니다. 앞으로 머신러닝 블랙박스 모델을 이해하는 해석 기법과 관련 기술의 발전에 대한 블로그가 이어질 예정입니다. 많이 기대해주세요.







1 Comment
Pingback: 머신러닝 해석력 시리즈 3탄: 부분의존성(PD) & 개별조건부기대치(ICE) 플롯 정복하기! - SAS Korea