
현존 최고의 데이터 과학자들이 뽑은 머신러닝 알고리즘 개발 베스트 프랙티스! 그 두 번째 시간입니다. 시리즈를 처음 접하시는 경우 블로그 1탄을 참고해주세요.
- 기본기 다지기
- 희귀한 이벤트 탐지하기
- 수많은 모델 결합하기
- 모델 적용하기
- 국소 최적해에 빠지는 것을 방지하기 위해 모델 오토튜닝하기
- 시간 효과(temporal effect) 관리하기
- '일반화' 이해하기
Chapter 5. 국소 최적해에 빠지는 것을 방지하기 위해 모델 오토튜닝하기
하이퍼파라미터는 학습 모델을 구축 할 때 모델을 튜닝하기 위한 알고리즘의 옵션들입니다. 하이퍼파라미터는 알고리즘을 사용하여 학습할 수는 없습니다. 따라서 이러한 파라미터는 모델 을 학습시키기 전에 할당해야 합니다. 기계 학습에서 우리가 개발하고자 하는 모델의 하이퍼파라미터의 최적 조합을 발견하기 위해 많은 수작업 노력이 필요합니다. 시행 착오를 통해 최적 조합을 발견하는 것보다 더 효율적으로 적합한 하이퍼파라미터 조합을 어떻게 찾을 수 있을까요? 다음의 방식을 통해 파라미터를 자동으로 조정함으로써 문제를 해결할 수 있습니다.
1. 그리드 탐색(Grid search): 하이퍼파라미터 공간에서 수동으로 지정한 하위 집합을 단순하게 모든 조합을 다 탐색하는 것을 말합니다. 이러한 작업은 학습용 세트에 대한 교차 검증(cross-validation) 또는 held-out 검증 세트에 대한 평가에 의해 측정된 모델 성능 척도에 따라 진행돼야 합니다. 균등한 공간의 시작 점들로부터 시작해 이 점들의 목적 함수 값(objective functions)을 계산하고, 가장 작은 것을 최적조합으로 선택하면 됩니다. 그렇지만 이 작업은 파라미터 공간이 클 때는 그리 현실적이지 않습니다.
2. 베이지안 최적화(Bayesian optimization): 베이지안 최적화는 노이지 블랙박스(noisy black-box) 함수의 글로벌 최적화를 위한 방법입니다. 하이퍼파라미터 최적화를 적용시 베이지안 최적화는 검증 세트에 평가된 목적에 하이퍼파라미터 값에서 도출한 함수 통계 모델을 개발하는 것으로 구성됩니다.
보다 다양한 오토튠과 하이퍼파라미터 방법은 SAS 블로그와 오토튠 백서를 통해 확인할 수 있습니다.
Chapter 6. 시간 효과(temporal effect) 관리하기
고대 그리스의 철학자 아리스토텔레스는 관찰을 통해 학습함으로써 경험주의(empiricism)를 연구 한 최초의 데이터 과학자 중 한명인 것 같습니다. 대부분의 데이터 과학자들과 마찬가지로 그는 시간이 지남에 따라 현상이 어떻게 변하는지를 살펴봤습니다. 즉, 모델의 통계적 특성은 개념 드리프트(concept drift)라고 알려진 프로세스를 통해 시간에 따라 변합니다.
필자는 한 가지 기능을 변경하거나 새로운 기능을 추가하면 전체 모델이 변할 수 있다는 사실을 인식하면서, ‘change-anything-changes-everything’ 방식을 준수합니다. 기능(특성 및 속성) 또한 변경될 수 있습니다.
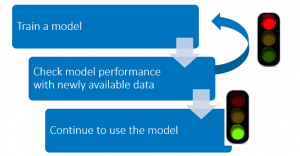
필자는 이 과정을 점진적 학습(progressive learning)이라고 부르며, 이때 모델은 데이터의 변화에 따라 적응하고 학습할 수 있습니다. 다음은 시간적 효과(temporal effect)를 보상하기 위해 사용하는 몇 가지 트릭입니다.
- 모집단 안정성 지수와 특성 모니터링 통계를 계산해 빈번한 간격으로 모델 쇠퇴를 측정합니다.
- 분류 모델(classification models)를 위해 ROC와 리프트를 모니터링합니다.
- 모델을 운영 환경에 적용시키기에 충분한 수준으로 엄격하게 준수했다면, 모델 쇠퇴를 탐지하도록 모니터링 작업을 설정합니다.
- 지정한 일정 간격으로 재학습 작업에 대한 일정을 수립합니다.
- 이벤트 발생을 예측하기 위해 시간 요인을 포함하고 있는 생존 분석(Survival analyses)은 충분히 활용되지 않고 있지만, 포인트 예측(point predictions)을 뛰어 넘습니다. 필자는 이산-시간 로지스틱 모델(discrete-time logistic models)을 사용한 생존 데이터 마이닝(survival data mining)을 권장합니다.
- 재귀 네트워크(Recurrent networks)는 순차적 데이터(sequence data)를 모델링할 때에도 매우 효과적입니다.
Chapter 7. ‘일반화’ 이해하기
일반화(Generalization)는 학습된 모델이 학습에 사용했던 데이터 대신 새로운 이전에 보지 못했던 데이터에 잘 들어 맞는 능력을 의미합니다. 과적합(Overfitting)은 하단 ‘그림 1’처럼 학습용 데이터와 너무 잘 맞는 모델을 말하는데요. 반면 저적합(Underfitting)은 하단 ‘그림 2’처럼 학습용 데이터와 잘 들어맞지 않고, 새로운 데이터 상에서도 일반화되지 않는 모델을 의미합니다. 만약 모델이 과적합이거나 저적합이라면 쉽게 말해 잘 일반화되지 않는다는 뜻인데요.
일반화는 편향(bias)이 높거나 분산이 큰 모델 사이에서 움직이는 균형 잡힌 활동을 의미합니다. 새로운 데이터에 잘 일반화하는 모델을 선택하기 위해서는 올바른 평가 메트릭(evaluation metric)을 사용하는 것이 필수적입니다.
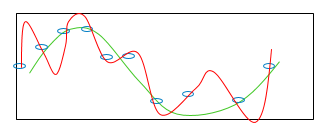
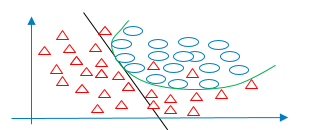
일반화에 대한 팁을 더 드리자면,
- 분산 오류가 큰 경우 더 많은 데이터 또는 부분 집합의 피쳐(feature)를 사용하세요.
- 편향 오류가 높은 경우 더 많은 파쳐(feature)을 사용하세요.
필자는 거의 항상 테스트용 데이터 세트를 사용합니다. 이 데이터 세트를 사용해 모델링을 하진 않지만 내 모델이 얼마나 잘 일반화되는지에 대한 불편 추정치를 얻을 수 있습니다. 학습용, 검증용, 테스트용 데이터 세트로 분할하기에 충분한 데이터가 없는 경우, 모델 일반화를 평가하기 위해 k-폴드(k-fold) 교차 검증(cross validation)을 사용합니다.
과적합을 피하는 또 다른 방법은 모델의 파라미터에 정규화(regularization)를 적용하는 것입니다. L1, L2, L21 등 몇몇 정규화를 선택할 수 있습니다. 정규화에 대한 자세한 내용은 또 다른 블로그 ‘정규화를 이용해 모델 과적합을 방지하는 방법’를 참고해주세요.
이어지는 <머신러닝 알고리즘 개발 베스트 프랙티스 3탄>에서는 학습용 데이터에 피쳐(feature)를 추가하는 방법 등이 소개될 예정입니다. 마지막 3탄에도 많은 관심 부탁드립니다.








1 Comment
Pingback: 데이터 과학자가 뽑은 "머신러닝 알고리즘 개발 베스트 프랙티스 3탄" - SAS Korea