
1980년대 후반에만 해도 머신러닝(machine learning)이나 데이터 과학자와 같은 개념은 없었습니다. 대신 통계, 분석, 데이터 마이닝, 데이터 모델링과 같은 단어가 사용됐는데요.
이후 글로벌 기업들은 30년 이상 머신러닝 모델을 연구해 왔으며, 페이스북의 이미지 인식 소프트웨어, 아마존의 음성 비서 알렉사, KT의 인공지능 서비스 기가 지니(GiGA Genie)까지 그 결과들이 연이어 쏟아지고 있죠!
이러한 결실 뒤에는 훌륭한 머신러닝 알고리즘 모델들이 있는데요. 앞으로 연재를 통해 현존 최고의 데이터 과학자들로부터 수년간 학습한 내용과 실제 수백 건의 프로젝트를 통해 확인한 최고의 모델을 기반으로 머신러닝 알고리즘 개발을 위한 베스트 프랙티스 10가지를 소개하고자 합니다. 오늘은 그 1탄으로 4가지 베스트 프랙티스를 공유합니다.
- 기본기 다지기
- 희귀한 이벤트 탐지하기
- 수많은 모델 결합하기
- 모델 적용하기
Chapter 1. 기본기 다지기
(1) 데이터 탐색하기
학습용 데이터 세트를 준비하는 데 작업 시간의 80% 이상이 소비됩니다. 따라서 모델을 구축하기 전에 우선 관찰 수준에서 데이터를 확인해야 합니다. Base SAS®에서는 OBS = 20 옵션으로 PROC PRINT를, SAS® VIYA에서는 FETCH 액션을, Python에서는 HEAD 또는 TAIL 기능을 사용해 데이터를 심도 깊게 확인할 수 있습니다. 이러한 과정을 통해 적합한 데이터가 올바른 형식으로 갖춰져 있는지 빠르게 판단할 수 있습니다.
또 학습용 데이터를 구축하는 단계에서 첫 번째 실수가 발생하는 경우가 많기 때문에 이 팁을 통해 오히려 많은 시간을 절약할 수 있습니다. 그리고 자연스럽게 집중경향치(central tendency)와 분산도(dispersion) 등의 통계치를 얻을 수 있습니다. 또 레이블을 기준으로 특징별 요약 통계(summary statistics)를 계산해서 주요 추세(key trends)와 이상치(anomalies)을 분리시킬 수 있습니다. 레이블이 범주형(categorical)이면, 변수를 기준으로 그룹화한 레이블을 사용해 요약 측정값을 계산하면 됩니다. 또 레이블이 등간격(interval)이면 상관 관계를 계산하고, 범주형 특징이 있으면 그룹화해 사용할 수 있습니다.
(2) 데이터 조각내기
일반적으로 데이터에는 숨겨진 하부 구조가 있습니다. 따라서 마치 피자처럼 데이터를 조각 내고, 슬라이스의 크기는 모두 다르지만 슬라이스마다 별도의 모델을 생성합니다. 이미 학습용 데이터에 계층화가 내재되어 있는 지역(REGION) 또는 차종(VEHICLE_TYPE)과 같은 그룹 변수를 이용할 수 있는데요. 타깃이 있을 때에는 얕은 의사결정 트리(decision tree)를 만든 후 각 세그먼트별로 별도의 모델을 생성합니다. 타깃이 있을 때 클러스터링(clustering) 알고리즘을 사용해 세그먼트를 만드는 경우는 거의 없습니다. 타깃 변수를 무시하는 것은 좋지 않겠죠?
(3) 오컴의 면도날(Occam’s Razor), 절감의 법칙 기억하기
오컴(Occam) 학습의 목적은 학습용 데이터의 간결한 표현을 출력하는 것입니다. 이성적으로 우리는 가능한 한 간단한 모델로 정보에 입각한 의사결정을 내리고자 하는데요. 많은 데이터 과학자들은 더 이상 오컴의 면도날 법칙을 믿지 않습니다. 데이터로부터 최대한의 정보를 추출하고, 더욱 복잡한 모델을 만드는 것이 중요한 기술이기 때문이죠.
그러나 회귀(regression) 및 의사결정 트리를 사용해 간단한 화이트박스(white-box) 모델을 구축하는 것도 좋습니다! 이 간단한 모델이 얼마나 잘 수행되고 있는지 빠르게 확인하기 위해서 그래디언트 부스팅 모델(gradient boosting model)을 사용할 수 있습니다. 또 회귀 모델의 성능을 개선하기 위해 1차 상호작용(first order interactions)이나 여타 기본적인 변형(basic transformations)을 추가할 수 있는데요. 필자는 일반적으로 모델 효과의 수를 줄이기 위해 L1을 사용합니다. 모델이 간단할수록 배포도 쉬워집니다. IT와 시스템 운영팀에게도 좋은 소식이겠죠? 또 가능한 한 가장 단순한 모델을 사용하면 비즈니스 담당자가 결과를 바탕으로 의사결정을 내리기 전에 결과와 그 결론에 도달한 방법을 더 쉽게 설명할 수 있습니다.
Chapter 2. 희귀한 이벤트 탐지하기
머신러닝 작업에는 일반적으로 매우 불균형한(unbalanced) 데이터가 사용됩니다. 예를 들어, 사기를 탐지하거나 제조 상의 결함을 분리할 때 대게 타깃 이벤트는 1% 미만으로 매우 희귀한데요. 따라서 99% 정확도의 모델을 사용하더라도 이처럼 희귀한 이벤트를 정확하게 분류하지 못할 수도 있습니다. 건초 더미에서 바늘을 찾기 위해 무엇을 할 수 있을까요?
많은 데이터 과학자들이 ‘샘플링(sampling)’이라는 단어를 들으면 눈살을 찌푸립니다. 대신 오버 샘플링(oversampling) 또는 언더 샘플링(undersampling)으로 편향된(biased) 학습용 데이터 세트를 만드는 ‘집중 데이터 선택(focused data selection)’이라는 용어를 사용할 수 있는데요. 결과적으로 학습용 데이터가 조금 더 균형을 이루고, 종종 10% 이상의 이벤트 수준을 갖출 수 있습니다. (그림 1 참조) 이벤트 비율이 높아질수록 머신러닝 알고리즘은 이벤트 신호를 더욱 잘 분리하는 법을 배울 수 있습니다.
참고로 언더 샘플링은 무작위로 관측치(observations)를 제거해 다수 클래스(majority class)의 크기를 하향 조정합니다. 오버 샘플링은 클래스 불균형(class disparity)의 수준을 낮추기 위해 무작위로 소수 클래스(minority class)의 크기를 상향 조정합니다.
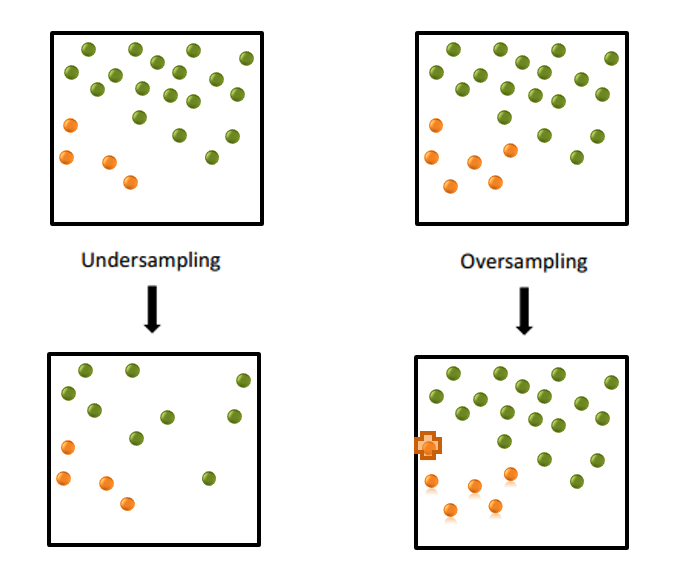
또 다른 희귀 이벤트에 대한 모델링 전략은 정확하게 분류된 이벤트에 더 큰 가중치를 부여하는 의사결정 프로세싱(decision processing) 방식을 사용하는 것입니다.
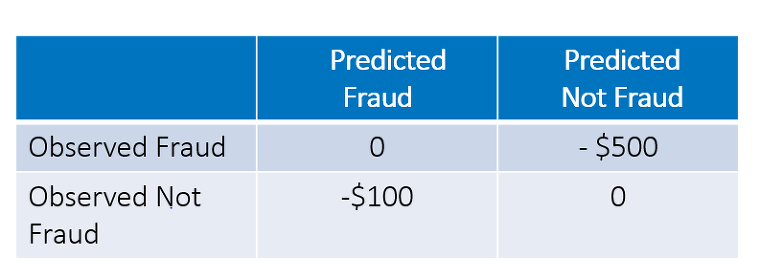
상단 표는 각 의사결정 결과에 따른 비용을 보여줍니다. 이 시나리오에서 사기를 사기가 아닌 것으로 판단(False Negative: 2종 오류)할 경우 예상 비용은 500달러입니다. 반대로 사기가 아닌데 사기로 판단(False Positive: 1종 오류)하는 경우 예상 비용은 100달러입니다.
여기에서는 일부 통계적 평가 기준을 기반으로 모델을 개발하는 대신 총 비용을 최소화하는 최상의 모델을 선택하는 것이 목표입니다. <총 비용 = 2종 오류 X 500 + 1종 오류 X 100> 이 전략에서는 두 가지 유형의 분류 오류에 따른 비용을 정확하게 측정하는 것이 알고리즘의 성공과 직결됩니다.
Chapter 3. 수많은 모델 결합하기
데이터 과학자들은 일반적으로 그래디언트 부스팅(gradient boosting), 랜덤 포레스트(random forests)를 이용하여 수많은 모델을 자동으로 구축합니다. 그리고 잠재적으로 더 강력한 솔루션을 만들기 위해 개별 모델들을 결합하는데요. 가장 정확한 머신러닝 분류기(classifiers) 중 하나는 그래디언트 부스팅 트리(gradient boosting trees)입니다.
랜덤 포레스트(random forest)를 사용할 때는 트리의 깊이를 너무 얕게 설정하지 않도록 주의해야 합니다. 랜덤 포레스트 목표는 크고 깊은 트리를 무작위로 많이 키우는 것입니다. 덤불이 아닌 숲을 생각해야 합니다. 깊은 트리는 확실히 데이터를 과적합(overfit)하는 경향이 있고 일반화를 잘 못하지만, 이들을 결합하면 일반화된 방식으로 공간의 뉘앙스(nuances of the space)를 포착합니다.
일부 알고리즘은 다른 알고리즘보다 데이터의 특정 영역이나 경계 내에서 더 적합합니다. 따라서 베스트 프랙티스는 서로 다른 모델링 알고리즘을 결합하는 것입니다. 또 전체적으로 최상의 분류를 가지거나 검증 데이터에 적합한 모델링 방법에 중점이나 무게를 둘 수도 있습니다. 때로는 학습용 데이터의 특정 공간에서 약한 분류기 두 개가 강력한 분류기 하나보다 더 뛰어날 수 있죠!
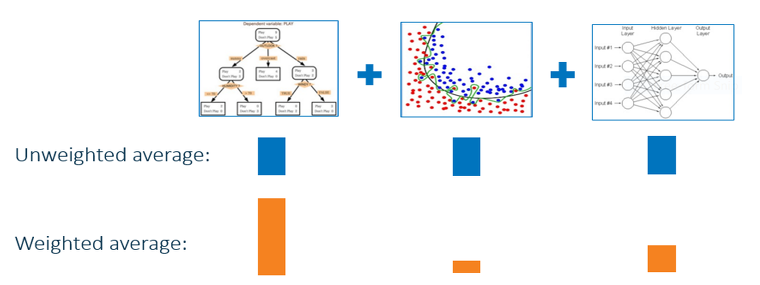
머신러닝 경험을 더 쌓으면서 더 많은 기술을 습득하게 되면 여러 기술을 결합해 희귀한 이벤트 모델링 문제를 해결해 나갈 수 있습니다.
최근 개발된 무허가 송금 비즈니스를 식별하는 모델을 예로 들어보겠습니다. 이벤트 수준은 약 0.09%였는데요. 이 문제를 해결하는 데 여러 기술이 사용됐습니다.
-
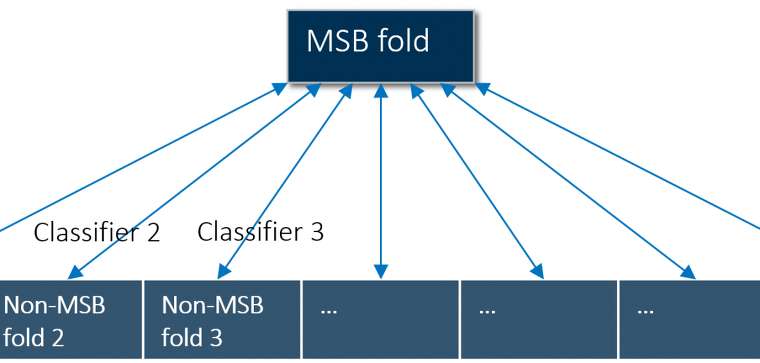
- 우선 개별 폴드(fold) 200개의 모든 이벤트를 유지하면서, 각 폴드마다 무작위로 비-이벤트(nonevents)의 하위 표본(subsample)을 선택해 k-폴드 표본을 개발했습니다.
- 그리고 각 폴드마다 랜덤 포레스트 모델을 구축했습니다.
- 마지막으로 200개의 랜덤 포레스트를 결합해 앙상블 모델을 만들었는데, 다른 모델들 중에서 가장 우수한 분류기가 됐습니다.
이 문제는 많은 연산이 요구되는 문제이기 때문에 모델이 신속하게 훈련할 수 있도록 모델을 여러 데이터 노드에 걸쳐 병렬로 구축하는 것이 중요합니다.
Chapter 4. 모델 적용하기
과거의 학습용 데이터를 기반으로 모델을 구축한 다음, 이 모델을 새로운 데이터에 적용시켜 의사결정을 내리는 것이 일반적입니다. 이 프로세스를 모델 배포(model deployment) 또는 스코어링(scoring)이라고 부르는데요. 데이터 과학자들이 모델을 배포하는 데에는 종종 몇 주 또는 몇 달이 걸립니다. 심지어 때로는 총력을 기울여도 결국 모델을 배포하지 못하는 경우도 있는데요.
각 모델은 수많은 데이터 준비 로직(data preparation logic)를 포함합니다. 따라서 많은 데이터 소스를 집계하고, 모델 수식을 포함시키고, 규칙이나 정책을 기준으로 계층화시켜야 하는데요. 다시 말해 스코어링 모델은 데이터 준비 + 규칙 + 모델 수식 + 잠재적인 더 많은 규칙들로 구성됩니다. 데이터 준비 로직은 스코어링에 필수적입니다. 보통 모든 변환 로직(transformation logic)을 정의함으로써 새로운 특징을 생성하는 작업을 포함하는 이러한 데이터 랭글링(wrangling) 단계는 데이터 과학자가 처리합니다.
그런 다음 모델을 배포하려면 새로운 특징(feature)을 만드는 변환 로직에 대한 정의를 포함하는 데이터 랭글링 단계를 반복해야 하는데요. 대개 IT 부서가 모델을 기업의 의사결정 지원 시스템에 통합하기 위해 이 작업을 완료합니다. 하지만 대부분의 기업은 스코어링을 위해 데이터 랭글링 단계를 재현할 수 있을 만큼 충분한 규칙과 메타 데이터를 가지고 있지 않습니다. 따라서 새로운 스코어링 테이블을 파생시키는 많은 이전 단계의 데이터 소스 종속성이 손실되는데요. 이것이 대부분의 기업에서 모델을 적용시키기까지 시간이 너무 오래 걸리는 가장 큰 이유죠! 이 문제의 해결책은 무엇일까요?
실제 모델을 적용시키려면 다음과 같은 운영 환경에서 예측 모델을 관리하기 위한 베스트 프랙티스를 구현해야 합니다.
-
- 비즈니스 목표 설정
- 데이터 접근 및 관리
- 모델 개발
- 모델 검증
- 모델 배포
- 모델 모니터링
한 가지 팁을 드리자면 모델 스코어 코드와 예비 변환(preliminary transformations)을 포함해 데이터 준비 로직을 자동으로 수집하고 묶을 수 있는 도구를 사용하는 것입니다. 모델 배포를 담당하는 데이터 엔지니어 또는 IT 담당자는 모델 구현을 위한 청사진을 가지고 있습니다. 또 데이터 엔지니어링과 알고리즘 단계를 단편적으로 반복할 필요가 없으므로 엄청난 시간을 절약 할 수 있죠! 데이터 과학자는 모델을 운영 환경에 적용시키기 전에 초기 스코어링 테스트에 참여해야만 합니다.
일부 혁신적인 기업들은 표준화된 분석 데이터 마트를 만들고, 분석을 위한 데이터 복제와 재사용을 촉진합니다. 데이터 과학자와 IT 담당자는 이러한 분석 데이터 마트에서 직접 데이터를 확보하고, 더 많은 모델을 보다 빠르게 구축하고 배포할 수 있도록 공동 작업을 수행할 수 있죠!
또 이 프로세스를 조정하면 일반적인 모델링 작업의 일부를 마치 ‘모델 공장’ 처럼 실행하는 단계까지 이를 수 있습니다. 이때 데이터 과학자가 새로운 특징 로직(feature logic)을 데이터 마트에 제공하는 것이 중요합니다. 모든 데이터 과학자들이 상세한 데이터 소스 수준에서 새로운 특징을 탐색하지 않아도 된다면 훨씬 더 자유롭겠죠?
실제 하나투어는 첨단 고급 분석 솔루션인 ‘SAS 마케팅 자동화(SAS Marketing Automation)’를 이용해 데이터 분석 기반의 통합 마케팅 인프라 환경을 구축하고, 고객·예약·상품 등 기본 정보, 상품 추천 및 고객 세분화 모델링 결과, 캠페인 반응 등 광범위한 마케팅 데이터를 포괄적으로 관리할 수 있는 ‘통합 마케팅 데이터 마트’를 개발했습니다. 이를 통해 타깃 마케팅을 강화시키고, 캠페인 효율을 향상시킴으로써 고객의 상품 예약률을 약 20~30% 향상시켰습니다. 자세히 살펴보기

데이터 과학자가 직접 뽑은 <머신러닝 알고리즘 개발을 위한 베스트 프랙티스 1탄> 어떠셨나요? 다음 블로그를 통해 ‘데이터 오토튜닝(autotuning)’ 등 최고의 팁들을 이어서 소개해드릴 예정입니다. 많은 기대 부탁드립니다.
머신러닝과 인공지능은 빠른 속도로 일상 속 깊숙이 자리잡고 있습니다. 머신러닝 모델과 알고리즘을 통해 새로운 비즈니스 가치를 창출하고, 우리 삶이 더욱 편해지는 날이 멀지 않은 것 같습니다. SAS 웹사이트에서 머신러닝에 대한 자세한 정보를 확인해보세요.







2 Comments
Pingback: 데이터 과학자가 뽑은 "머신러닝 알고리즘 개발 베스트 프랙티스 2탄" - SAS Korea
Pingback: 데이터 과학자가 뽑은 "머신러닝 알고리즘 개발 베스트 프랙티스 3탄" - SAS Korea