All Posts
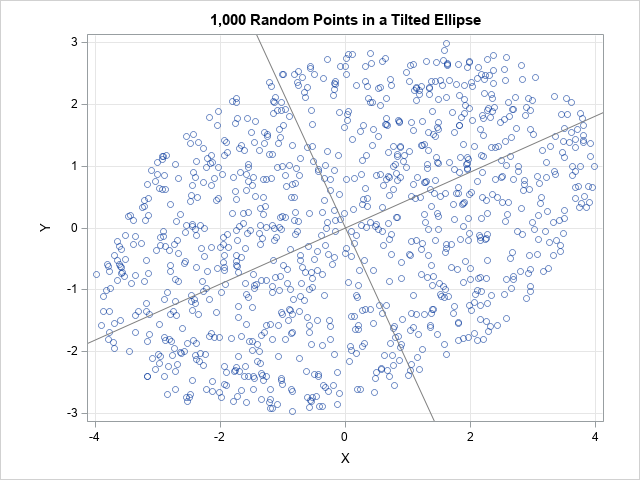

I have previously written about how to efficiently generate points uniformly at random inside a sphere (often called a ball by mathematicians). The method uses a mathematical fact from multivariate statistics: If X is drawn from the uncorrelated multivariate normal distribution in dimensiond, then S = r*X / ||X|| has

Welcome to the continuation of my series Getting Started with Python Integration to SAS Viya. In this post I'll show how to impute missing values in a distributed CAS table using the fillna method from the Pandas API in the SWAT package and the impute CAS action. Load and prepare data


We’re taught the rainbow has 7 primary colors - red, orange, yellow, green, blue, indigo and violet - and in this occasional series, we’ve discussed the unique set of nutrients and health benefits each of these colors provide. But what about the other colors that exist in nature?
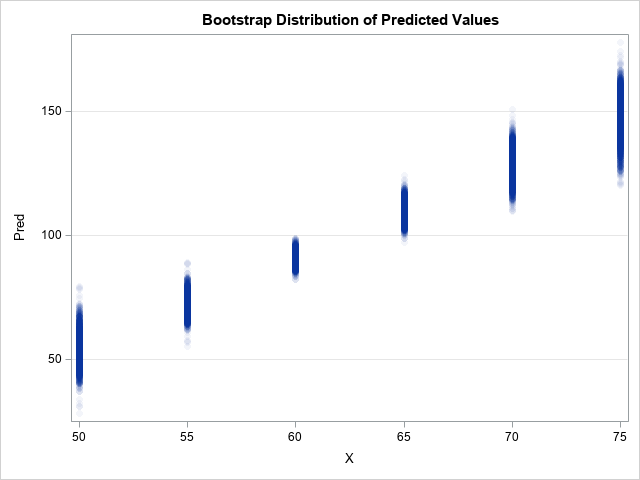
A previous article shows how to use the MODELAVERAGE statement in PROC GLMSELECT in SAS to perform a basic bootstrap analysis of the regression coefficients and fit statistics. A colleague asked whether PROC GLMSELECT can construct bootstrap confidence intervals for the predicted mean in a regression model, as described in


Más del 5% de los ingresos anuales de las aseguradoras se pierden ante la perpetración del fraude, del que se registran un promedio de 2 mil 500 casos por año, divididos en 125 países, de acuerdo con la Asociación de Certificadores de Fraude de Estados Unidos. Estas cifras incluyen sólo


SAS SVP Kimberly May announces the launch of the new SAS Customer Service Portal.
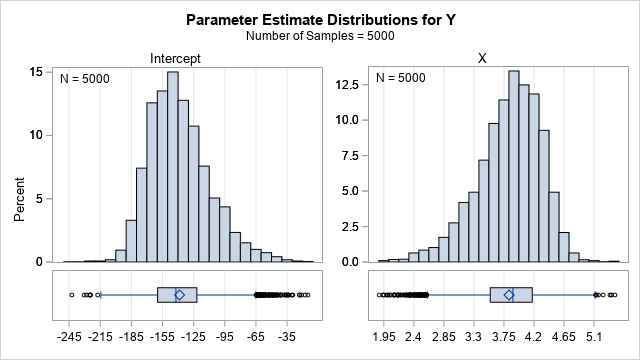
I've written many articles about bootstrapping in SAS, including several about bootstrapping in regression models. Many of the articles use a very general bootstrap method that can bootstrap almost any statistic that SAS can compute. The method uses PROC SURVEYSELECT to generate B bootstrap samples from the data, uses the


El lavado de dinero siempre se ha considerado un mal mayúsculo, pero las cifras actuales son abrumadoras. Al revisar los datos de la Financial Action Task Force (FATF), se revelan pérdidas actuales situadas entre el 2% y el 5% del PIB mundial por este flagelo. El panorama en Colombia, sin


Vivimos en una era de empresas data-driven, como una de las máximas premisas para la toma de buenas decisiones. ¿Pero qué pasa cuando la información nos supera? Si está pensando en Inteligencia Artificial, va por el camino correcto. Según proyecciones de analistas, el planeta generará más de 181 zettabytes de


실무에서 데이터를 다루다 보면 필연적으로 결측 데이터를 만나게 됩니다. 핑계 없는 무덤이 없다는 속담이 있듯, 데이터가 결측인 이유도 정말 다양합니다. 특별한 경우에만 값이 있는 경우, 서버 장애로 관측되지 않은 경우, 응답자가 응답을 거부하는 경우, 데이터 구조가 바뀌면서 새로운 컬럼이 추가된 경우 등등 너무 다양하죠? 오늘 포스팅에서는 이와 같은 결측치를 처리하는


At a time when data has become the center of innovation, the utility industry finds itself at a crossroads. Utilities worldwide are challenged by the ever-increasing demand for efficient energy consumption and the pressing need for sustainability. Balancing these priorities is not easy, nor is it cheap. In 2022, London


Artículo escrito por Violeta Gállego y Oscar Saavedra. Los algoritmos de IA combinados con el histórico de las interacciones son el match perfecto para mejorar tus resultados de ventas. Esto es gracias a la mejora en la personalización de las preferencias de los clientes que nos permiten hacer. ¿Qué es?


Bancos precisarão avançar seus modelos analíticos para se adequar às regras de previsão de perda esperada de crédito e normas internacionais No mercado financeiro, garantir a conformidade às regulamentações é uma constante na vida do tomador de decisão de tecnologia - e o IFRS 9 e a CMN 4.966/21 são

In maternal and newborn health care, a pressing challenge looms large – neonatal sepsis. This dangerous infection claims the lives of countless newborns each year, devastating families and other loved ones. The World Health Organization (WHO) identifies neonatal infections as a leading cause of infant mortality, responsible for nearly a


It's easy to feel pulled in too many directions. Living in the Western world and studying mind/body modalities from an Eastern perspective can often feel like a tug of war. The Western culture is often focused on the pursuit of attainment while the East accentuates “letting go.” As I grew