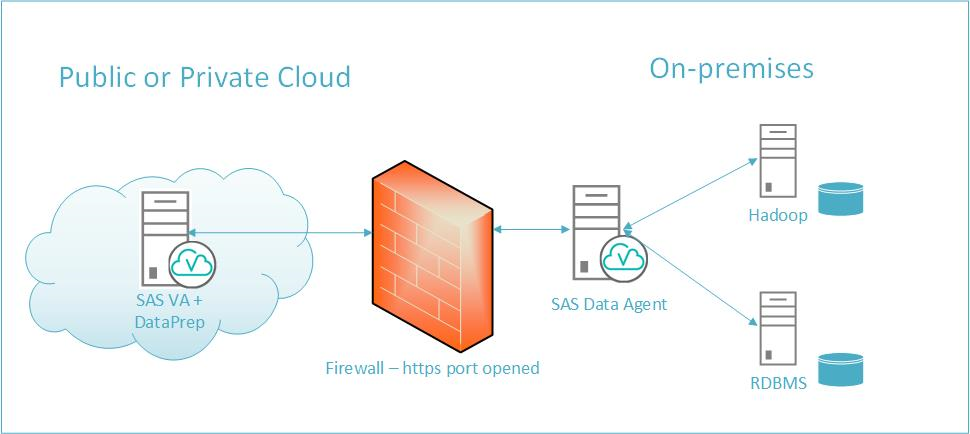
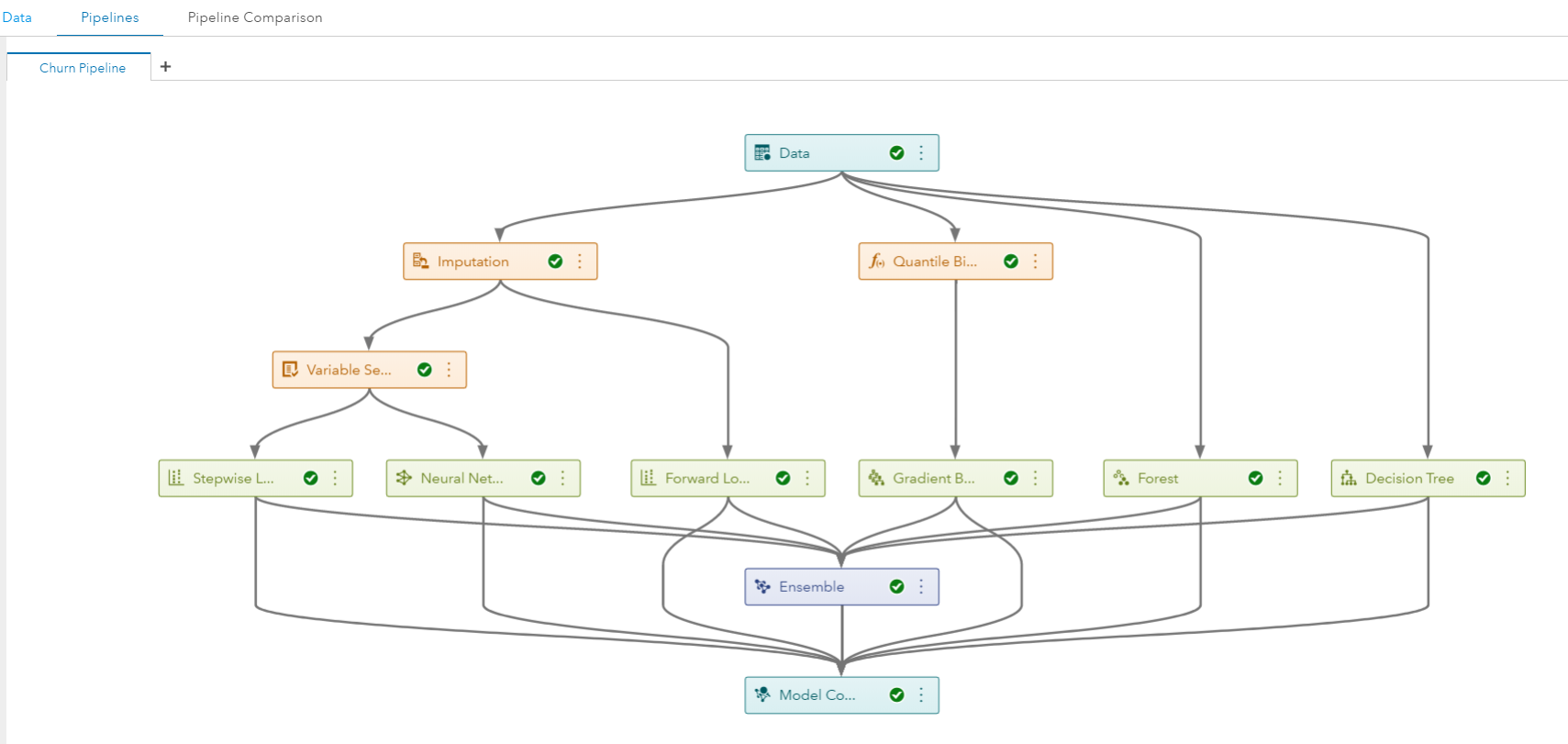
クラウド上のSAS Viyaから、オンプレミス上にあるデータへ、セキュアにアクセス
近年、クラウドファーストを唱える企業が増加し、データ分析のために、クラウド上に展開されている分析サービスを活用したり、クラウド上に独自に分析アプリケーションを構築するケースも増えています。 しかし、クラウド上にある分析サービスやアプリケーションで分析する対象のデータは、オンプレミス上に蓄積されているケースが大半であり、クラウドからこれらのデータにアクセスできるようにするための作業や環境設定は面倒かつ非効率で、膨大なデータをクラウドとやり取りするなどの運用コストも大きく、かつセキュリティのリスク回避も考慮しなければなりません。 こうした課題を解決するために、SAS ViyaではSAS Cloud Data Exchange (CDE)を提供しています。 SAS Cloud Data Exchange (CDE) は、プライベート/パプリックのクラウド上にあるアプリケーション(=SAS Viya)からファイヤーウォールの後ろにある、顧客のオンプレミス上にあるデータに安全かつ確実にアクセスし、大量のデータをクラウドへ高速に転送することを可能とするデータ接続機能です。 CDEは、SAS Viyaのセルフサービス・データ準備向け製品であるSAS Data Preparationに含まれる機能です。 CDEを使用すれば、クラウド上にあるSAS Viyaからオンプレミス上にある様々なデータソース(Oracle, Teradata, Hadoop etc.)へ最小限の手順で容易かつセキュアにアクセスすることが可能になります。 サポート対象データソース: ・DB2, ODBC, Apache Hive, Oracle, Redshift, SQL Server, Postgres, SAP HANA, Teradata, SAS Data Sets CDEでは、最小限の一つのポート(Https port)を使用し、オンプレミス上にあるデータソースにアクセスするための資格情報(ユーザーID /パスワード)も保護された領域に格納し、使用するため、安全性が高められています。 また、クラウド上のSAS Viyaが複数のワーカーノードで分散構成されている場合には、オンプレミス上のデータを並列で高速にSAS Viya環境へロードすることが可能です。 利用手順概要は以下の通りです。 オンプレミス側にSAS Data Agent