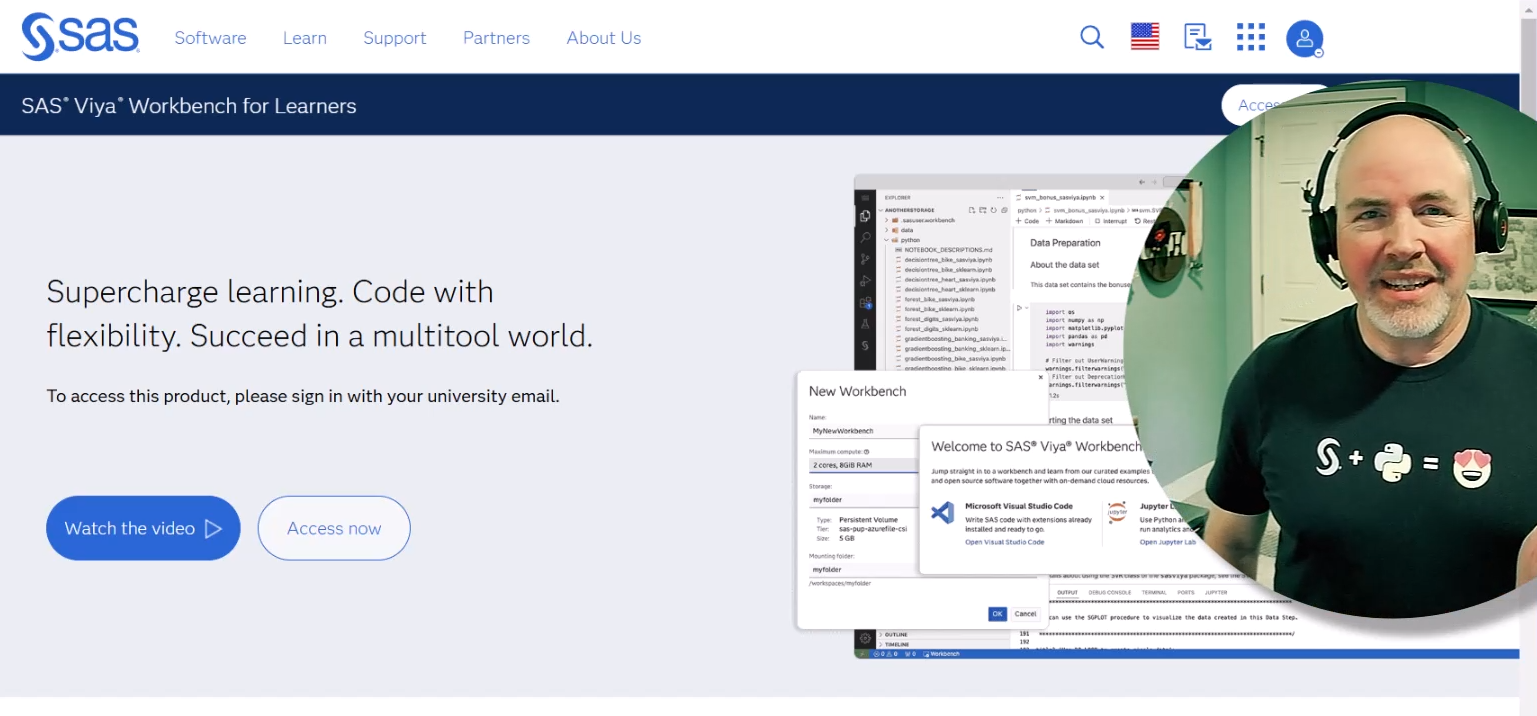
Getting Started with Python Integration to SAS Viya for Predictive Modeling - Fitting a Support Vector Machine (SVM) Model

Fitting a Support Vector Machine (SVM) Model - Learn how to fit a support vector machine model and use your model to score new data In Part 6, Part 7, Part 9, Part 10, and Part 11 of this series, we fit a logistic regression, decision tree, random forest, gradient